CMU论文解读:基于GAN和VAE的跨模态图像生成


在碎片化阅读充斥眼球的时代,越来越少的人会去关注每篇论文背后的探索和思考。
在这个栏目里,你会快速 get 每篇精选论文的亮点和痛点,时刻紧跟 AI 前沿成果。
点击本文底部的「阅读原文」即刻加入社区,查看更多最新论文推荐。
本期推荐的论文笔记来自 PaperWeekly 社区用户 @TwistedW。跨模态的图像生成在模态差异大的情况下是很难实现的,本文将一个模态下编码得到的潜在变量当做条件经过 GAN 映射为另一个模态下的潜在变量,实现了模态间潜在变量之间的相互映射,从而实现了跨模态下的相互生成。
如果你对本文工作感兴趣,点击底部阅读原文即可查看原论文。
关于作者:武广,合肥工业大学硕士生,研究方向为图像生成。
■ 论文 | Cross Domain Image Generation through Latent Space Exploration with Adversarial Loss
■ 链接 | https://www.paperweekly.site/papers/2223
■ 作者 | Yingjing Lu
跨模态之间转换生成在模态间差异大的时候是相对困难的,将一个模态编码得到的潜在变量作为条件,在 GAN 的训练下映射到另一个模态的潜在变量是本文的核心。虽然这篇论文只是预印版,但是文章的这个跨模态潜在变量相互映射的思想是很有启发性的。
论文引入
人类很容易学会将一个领域的知识转移到另一个领域,人类可以灵活地学习将他们已经在不同领域学到的知识连接在一起,这样在一个领域内的条件下,他们就可以回忆或激活他们从另一个领域学到的知识。
深度生成模型通过将它们映射到潜在空间来编码一个域内的隐式知识是被广泛使用的,可以控制潜在变量通过条件在学习域内生成特定样本。然而,与人类相比,深层生成模型在从一个域到另一个域之间建立新连接方面不够灵活。换句话说,一旦它学会了从一组域条件生成样本,使其用于生成以另一组控制为条件的样本通常很难并且可能需要重新训练模型。
跨域转换对于建立模态之间的联系是重要的,能够让神经网络更加地智能化,有一些方法提出来解决跨模态的问题。将条件编码映射到无条件训练的 VAE [1],以允许它用用户定义的域有条件地生成样本,并取得了很好的效果。
但是一个限制是那些条件是通过 one-hot 专门定义的。这样做需要特征工程,并且想要对一些隐含的特征进行条件化时效果较差,例如使用来自一个场景的图像作为条件来生成学习域中的相关图像。在 Unsupervised Cross-domain Image Generation [2] 中训练端到端模型,假设这两个域相关性,再循环训练。
今天要说的这篇论文,在更少的模态假设下实现了跨模态的相互生成。总结一下这篇论文的优势:
利用 GAN 实现了跨模态的潜在变量之间的相互映射
在较少的假设下实现跨模态的转换
实现方法
我们一起来看一下文章实现的模型框架:
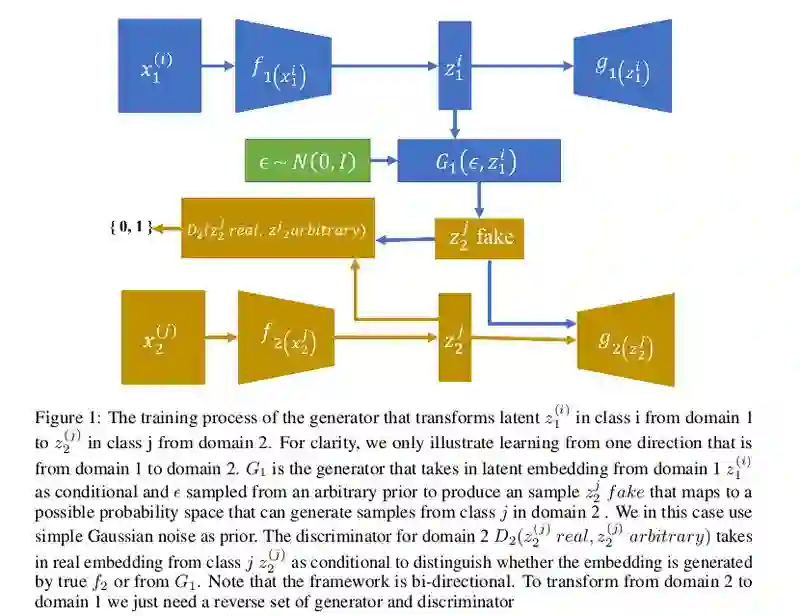
下标为 1 的代表着是模态 1 下的数据变换,相对应的下表为 2 的代表着模态 2 下的数据变换,上标代表着模态下的类别,i 类和 j 类。f 代表着编码器网络,g 代表着解码器网络,G 代表了实现映射的生成器,D 代表了对应的判别器,噪声 ϵ∼N(0,1)。
我们看到上下两路对应的是 VAE 实现框架,也就是上路为模态 1 对应的 VAE1 是一个完整的流程,下路为模态 2 对应的 VAE2 也是一个完整的流程,当训练 VAE1 和 VAE2 到收敛状态时(训练完成),此时的编码器已经可以很好的将模态数据编码到隐藏空间了。
我们分析由模态 1 到模态 2 的变换。模态 1 的第 i 类图像作为输入到模态 1 的编码器
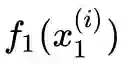
,将
作为条件,ϵ 作为噪声输入到生成器 G1 下从而实现映射到,模态2第j类的图像经过编码得到的潜在空间下,此时由生成器 G1 得到的映射记为
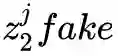
判别器 D2 的目的是为了判别真实模态 2 下 j 类图像编码得到的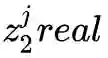
分析了框架的实现方法我们再看一下实现的损失函数上的设计,首先是 VAE 对应的损失优化,这个大家估计也都熟悉了:
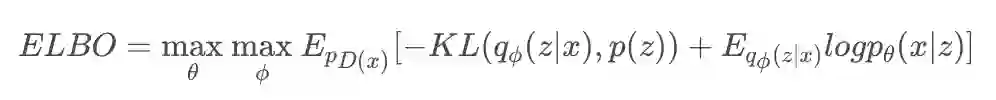
ELBO 下参数的定义和原始 VAE 下是相同的,我就不重复描述了,为了达到更好的 VAE 结果,文章还加了一个像素上的重构误差,所以最终 VAE 下的损失函数为:
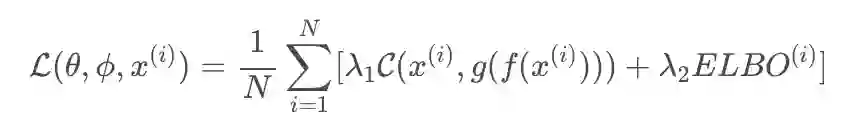
这里的 C 就是像素上的重构误差,λ1,λ2 为控制的参数,这个损失将实现 VAE 的整体优化。
对于映射上的 GAN 的损失函数设计,文章主要采用匹配的方法博弈,文章匹配有三组。一组是真实匹配 z,z,对应的损失记为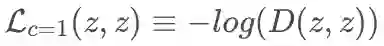
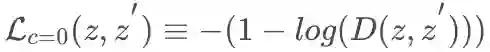
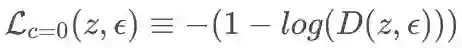
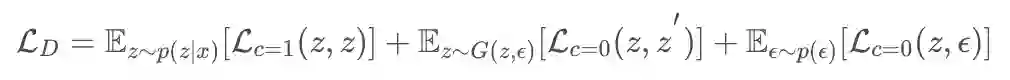
在生成器中文章引入了正则项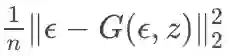
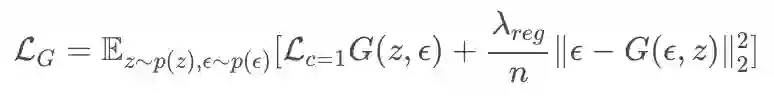
经过对上述损失函数优化,系统将达到平衡,此时就可以实现跨模态的相互生成。输入模态 1 下的经过编码得到
,经过 GAN 的映射得到
,从而实现了模态间的转换。
实验
文中主要是在 MNIST 数据集和 SVHN 数据集下进行的实验,MNIST→MNIST 的实现下的模态转换主要是实现 0→5,1→6,2→7,3→8,4→9,其中 0,1,2,3,4 为模态 1 下的数据,5,6,7,8,9 为模态 2 下的数据,得到的生成的实验结果如下:
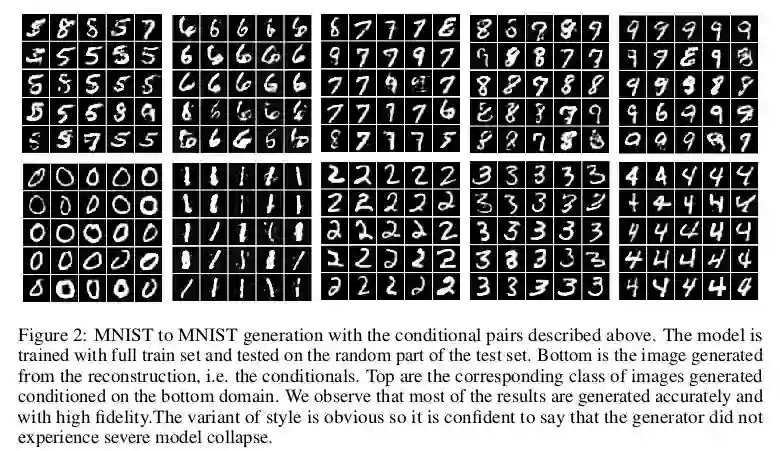
对于 SVHN 到 MNIST 的转换,由于 SVHN 下没有 0 这个数字,所以转换为 1→6,2→7,3→8,4→9,结果如下:

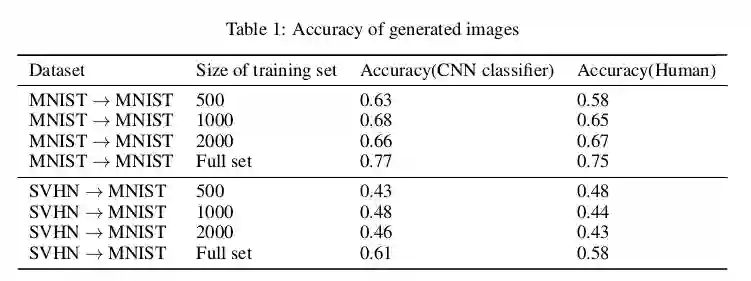
在定量分析上,文中为生成的数据设计了分类器用来检测生成数据的分类效果,侧面反应生成的质量,同时也做了人体辨别实验:
文中还补充了 MNIST 到 Fashion-MNIST 转换的实验,实验生成上得到了不错的效果:

由于只是预印版,所以一些详细的对比实验没有加进去,不过这种方法的启发意义还是蛮大的。
总结
文章利用 GAN 的思想在 VAE 的基础上,实现了模态间的潜在空间的相互映射,得到映射的空间可以进一步的解码生成对应于另一个模态的数据,从而实现了跨模态的相互生成。这种利用潜在空间的变换实现跨模态生成在很多跨模态之间都可以参考,虽然文章只是预印版但是很具有启发意义。
参考文献
[1]. Jesse Engel, Matthew Hoffman, and Adam Roberts. Latent constraints: Learning to generate conditionally from unconditional generative models. arXiv preprint arXiv:1711.05772, 2017.
[2]. Yaniv Taigman, Adam Polyak, and Lior Wolf. Unsupervised cross-domain image generation. arXiv preprint arXiv:1611.02200, 2016.
本文由 AI 学术社区 PaperWeekly 精选推荐,社区目前已覆盖自然语言处理、计算机视觉、人工智能、机器学习、数据挖掘和信息检索等研究方向,点击「阅读原文」即刻加入社区!

点击标题查看更多论文解读:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢? 答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 下载论文



