没有点积注意力就不香了吗?Transformer中自注意力机制的反思

机构:Google Research
作者:Yi Tay, Dara Bahri, Donald Metzler, Da-Cheng Juan, Zhe Zhao, Che Zheng
0.1 摘要
以当下基于 Transformer 的各种先进模型来看,使用点积自注意力(dot product self-attention)是至关重要且不可或缺的。但,事实真的如此吗,没有点积自注意力 Transformer 的各种模型就会不香吗?点积自注意力是否真的不可替代?为此,本文提出 SYNTHESIZER 模型,该模型注意力权重的学习摒弃了传统自注意力机制中 token 之间的交互。本文通过大量实验发现:
(1)随机初始化对齐矩阵所表现出的实力惊人
(2)学习注意力权重其实没有必要基于 token-token 或者说 query-key 之间的交互
此外,实验表明 SYNTHESIZER 模型在多个任务(包括机器翻译、语言建模、文本摘要、对话生成和自然语言理解)上可以与原始的 Transformer 相媲美。
1. 介绍
随着基于 Transformer 的各种模型在众多 NLP 任务上大获成功,Transformer 的霸主地位已成事实。而 Transformer 的核心是 query-key-value 的点积自注意力,点积自注意力的基本作用是学习自对齐(self-alignment),即确定单个 token 相对于序列中所有其他 token 的相对重要性。实际上query、key 和 values 隐含着自注意力模拟一个基于内容的检索过程,而这个过程的核心是 pairwise 之间的交互。本文则对这整个过程进行了反思。
与传统的做法相反,本文提出既不需要点积自注意力,也不需要基于内容的记忆类自注意力。传统上,注意力权重是在实例或样本级学习的,其中权重通过实例级的 pairwise 交互产生。因此,这些特定于具体实例的交互往往在不同的实例间波动,缺乏一致的全局语境。为此,本文提出 SYNTHESIZER,该模型不再计算 token 之间两两点积,而是学习合成自对齐(self-alignment)矩阵,即合成自注意力矩阵。同时本文提出多种合成方式,并对其进行全面评估。这些合成函数接收的信息源包括(1)单个 token(2)token-token 之间的交互(3)全局任务信息。
其实,SYNTHESIZER 是标准 Transformer 的泛化。实验结果表明 SYNTHESIZER 凭借全局注意力权重也能够获得具有竞争性的结果,而完全不用考虑 token-token 交互或任何实例级(局部)信息。随机初始化的 SYNTHESIZER 在 WMT 2014 English-German 上取得27.27的BLEU。在某些情况下,可以用更简单的 SYNTHESIZER 变体替换流行的和完善的基于内容的点积注意力,而不会牺牲太多性能。总的来说,本文的发现将会促进 Transformer 模型中自注意机制真正作用和效用的进一步研究和讨论。
本文的贡献如下:
1. 提出 Synthetic Attention,这是一种新的学习注意力权重的方式。该方法没有使用点积注意力或基于内容的注意力)。生成独立于 token-token 交互的对齐矩阵,并探索了一组用于生成注意力矩阵的参数化函数。
2. 提出 SYNTHESIZER 模型,该模型利用了 Synthetic Attention。该模型在多个自然语言任务(包括机器翻译和语言建模)上可以与最先进的 Transformer 模型相比肩。
3. 证明(1)随机可学习的对齐矩阵的性能具有竞争性;(2)用各种 Transformer 模型进行屠榜时,token-token 的依赖关系并非必要。
2. 模型

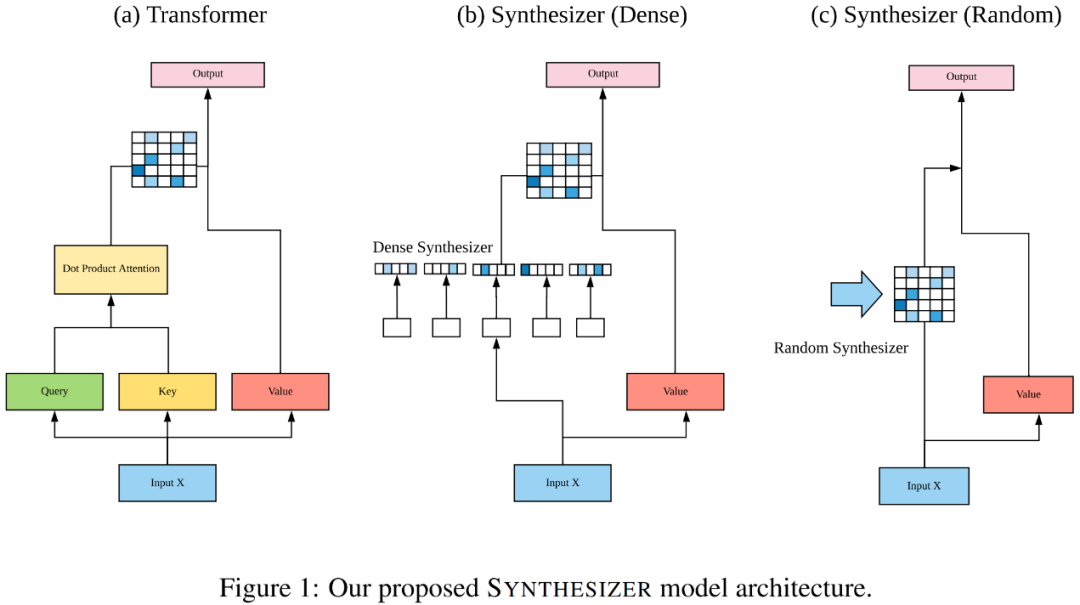


2.2 Random Synthesizer:



本文提出的各种合成函数如 Table 1所示。值得注意的是,常规的点积注意力也可以被纳入 SYNTHESIZER 的合成器框架,换句话说,SYNTHESIZER 是 Transformer 模型的一般化形式。


文本在机器翻译、语言模型、文本生成、多任务自然语言理解等任务上进行了实验。
机器翻译和语言建模:
在 WMT’14 英德(EnDe)和英法(EnFr)机器翻译任务数据集上评测,结果如 Table 2 所示。
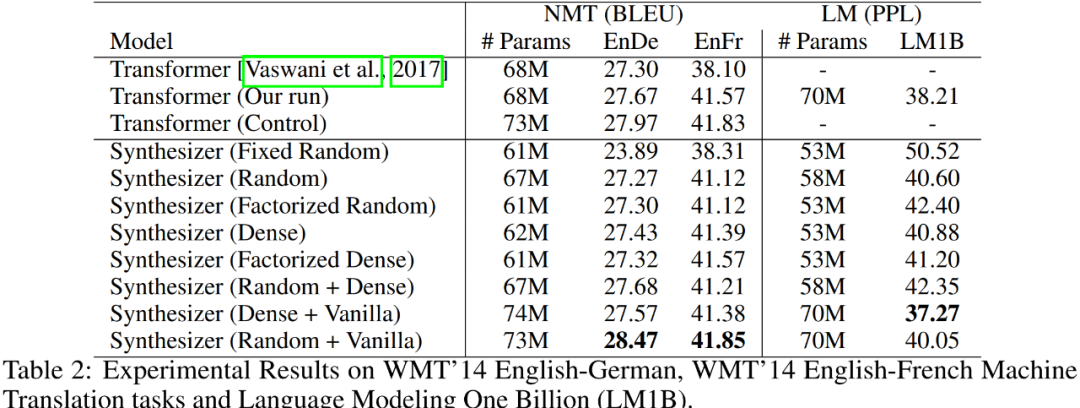
从上述 Table 2 可以看出,除了固定的 Random Synthesizer 表现较差之外,其他模型表现都差不多,尽管相比于 Transformers 略有下降。其实固定的 Random Synthesizer 结果也是蛮惊人的,EnDe上也有大概 24 BLEU。
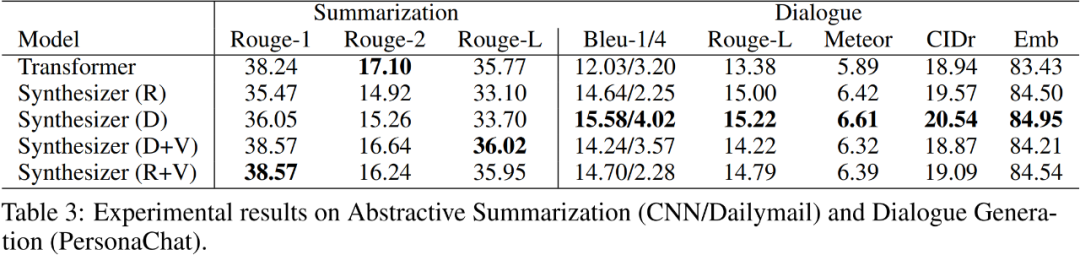
在文本生成上分别使用了摘要生成方面的 CNN/Dailymail 数据集和对话生成方面的 PersonaChat 数据集,具体实验结果如 Table 3 所示:
多任务自然语言理解:
在自然语言理解任务上选用的是使用 GLUE 和 SuperGLUE。SYNTHESIZER 模型和 T5(base)在上述俩个benchmark上的实验结果如 Table 4 和Table 5 所示:
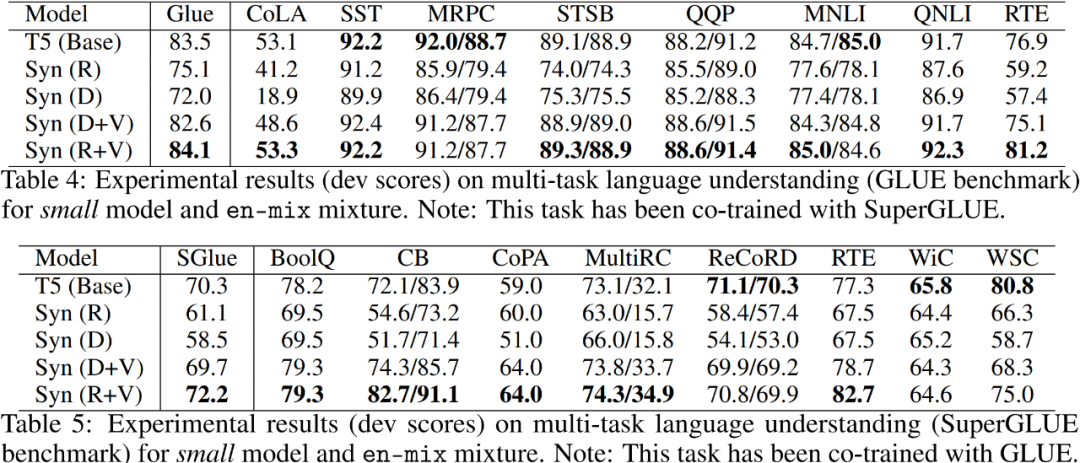
从实验结果可以看出,R+V 的混合模型在多数子任务上取得最好的效果。
本文提出一种新的 Transformer 模型 SYNTHESIZER,该模型它采用合成注意力(Synthetic Attention)。此外试图更好地理解和评估全局对齐、局部对齐和实例对齐(单个 token 和 token-token)在自注意力中的效用。并在机器翻译、语言建模和对话生成等多个任务上证明了合成注意力可以与原始的 Transformer 相媲美。特别是在对话生成任务上,token-token 之间的交互实际上会降低性能。Synthesizer 的不同设置没有绝对的优劣,与具体的任务相关。总的来说,本文是对当下流行的自注意力机制的反思和探索,希望能够抛砖引玉,进一步促进 Transformer 中各个部分效用的研究。

想要了解更多学术进展、前沿科技资讯,参与学术头条每日话题讨论,可以扫描二维码或搜索AMiner308添加学术君微信,对学术君说: “我想进读者群”, 即可进入读者群,不定期发福利~








