Transformer-XL:释放注意力模型的潜力
文 / Zhilin Yang 和 Quoc Le,Google AI 团队
为了正确理解一篇文章,读者有时需要返回前文,参考在几千字之前出现的一个词或句子。这是一个长程依赖性的示例。长程依赖现象在序列数据中非常常见,我们必须理解其含义,这样才能处理很多现实任务。虽然人们可以很自然地这样做,但使用神经网络对长期依赖关系进行建模仍然是一项挑战。门控循环神经网络 (RNN) 和梯度裁剪技术可以提升对长期依赖关系进行建模的能力,但还不足以完全解决这一问题。
要解决这一难题,其中一个方法是使用 Transformer。该工具允许在数据单元之间建立直接联系,从而有可能更好地捕捉长期依赖关系。然而,在语言建模中,Transformer 目前使用固定长度的上下文来实现,即将一个长文本序列截成多个包含数百个字符的长度固定的句段,然后单独处理每个句段。
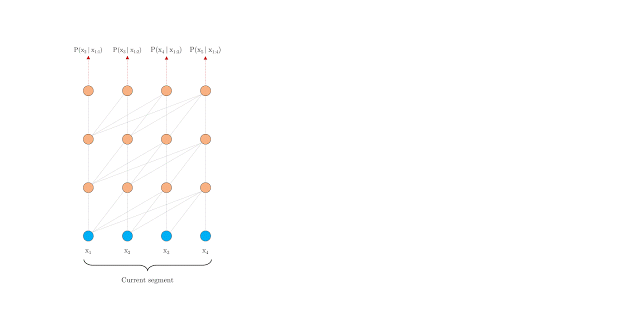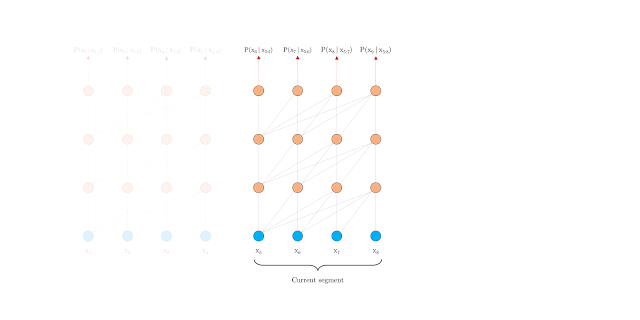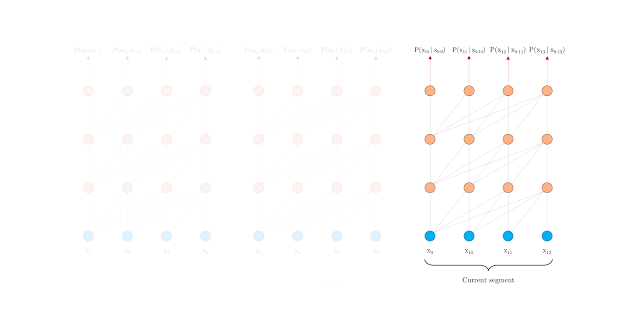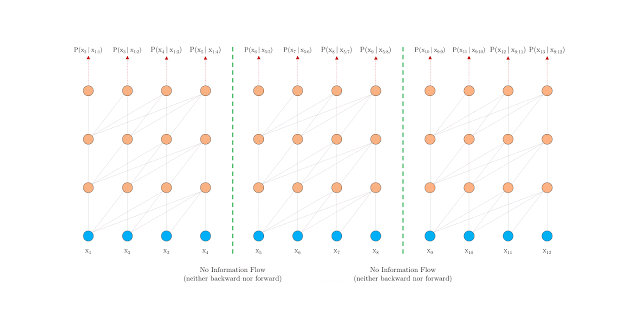
在训练期间具有固定长度上下文的 Vanilla Transformer
这引入了两个关键限制:
算法无法对超过固定长度的依赖关系建模
句段通常不遵循句子边界,从而造成上下文碎片化,导致优化效率低下。在长程依赖性不成其为问题的短序列中,这种做法尤其令人烦扰
为了解决这些限制,我们推出了 Transformer-XL,这是一个非常新颖的架构,可以实现超出固定长度上下文的自然语言理解。Transformer-XL 采用了两项技术:句段层级的循环机制和相对位置编码方案。
句段层级的循环
在训练期间,系统为前一个句段计算的表征会被修正并缓存,当模型处理下一个新句段时,即可将其作为扩展上下文重新使用。上下文信息现在可以跨句段边界流动,因此,这一额外联系将可能的最大依赖关系长度扩大了 N 倍,其中 N 是网络深度。此外,这一递归机制还可以解决上下文碎片化问题,从而为新句段前面的令牌提供必要的上下文。
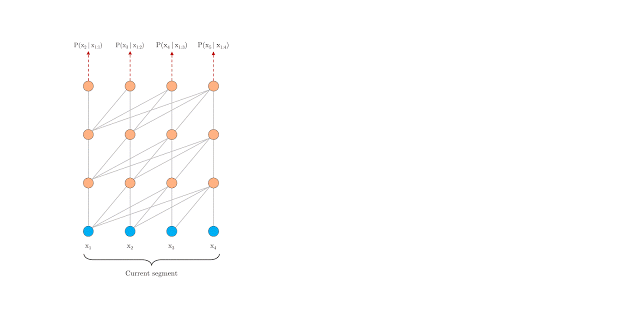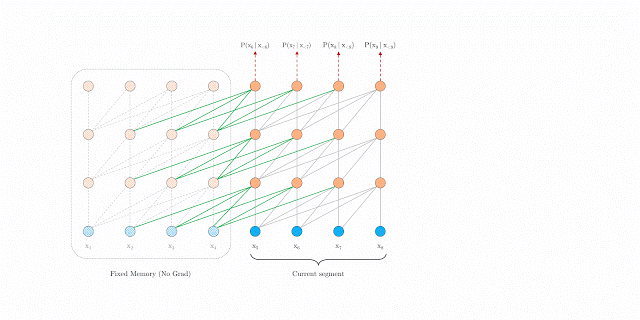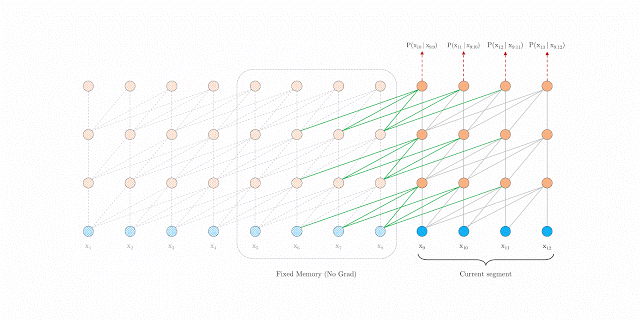
在训练期间采用句段层级循环的 Transformer-XL
相对位置编码
然而,只应用句段层级的循环是行不通的,因为当我们再次使用前面的句段时,位置编码并不一致。例如,假设旧句段的上下文位置是 [0, 1, 2, 3]。当模型处理一个新句段时,这两个句段合并后的位置是 [0, 1, 2, 3, 0, 1, 2, 3],但每个位置编号的语义在整个序列中并不连贯。为此,我们提出了一个新的相对位置编码方案,以使递归机制的应用成为可能。此外,与其他相对位置编码方案不同,我们的方案使用了具备可习得转换的固定嵌入,而非可习得嵌入,因此该方案在测试时可以更广泛地适用于较长的序列。当我们将这两种方法结合使用时,Transformer-XL 在评估期间拥有的有效上下文会比 Vanilla Transformer 模型长得多。
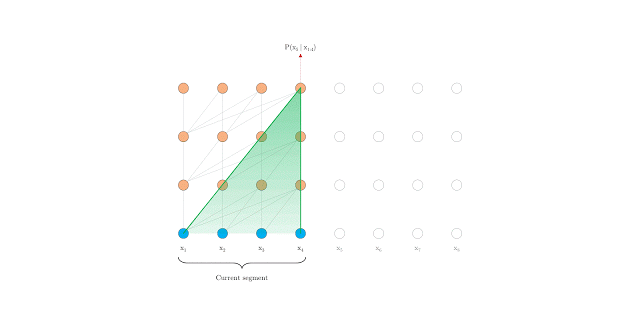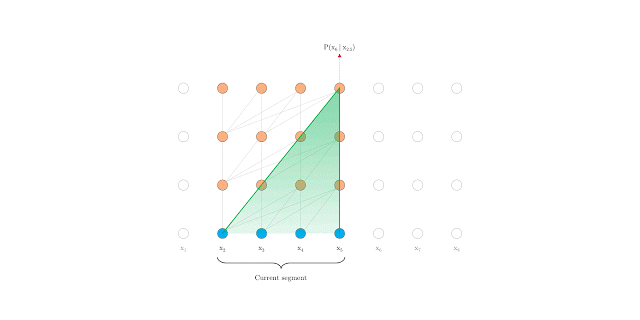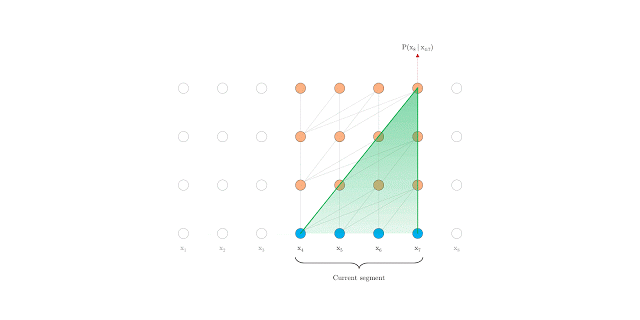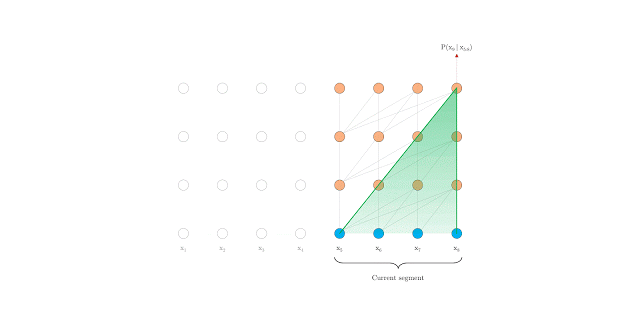
在评估期间具有固定长度上下文的 Vanilla Transformer
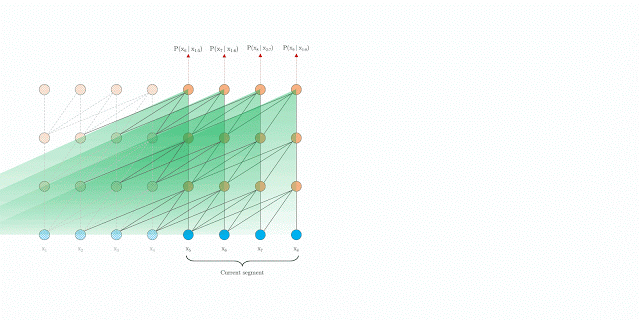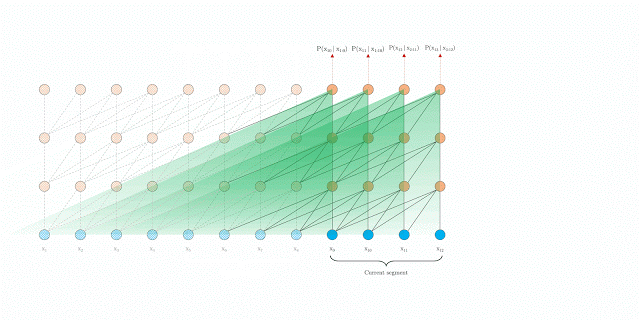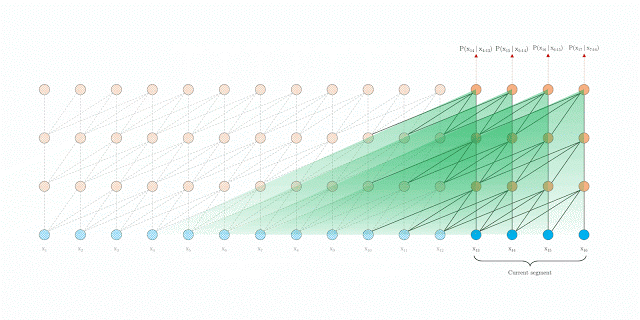
在评估期间采用句段层级循环的 Transformer-XL /td>
另外,Transformer-XL 可以在不进行重新计算的情况下同时处理新句段中的所有元素,进而显著提升速度(在下文讨论)。
成果
Transformer-XL 在各种主要的语言建模 (LM) 基准测试中均获得新的最优 (SoTA) 结果,包括长短序列上的字符层级和单词层级任务。实验证明,Transformer-XL 有三大优势:
Transformer-XL 学习的依赖关系大约比 RNN 长 80%,比 Vanilla Transformer 长 450%,虽然后者的性能比 RNN 更好,但由于上下文的长度固定,因而其并非对长程依赖关系建模的最佳选择(详情请参阅 https://arxiv.org/abs/1901.02860)
由于不需要重新计算,Transformer-XL 在评估语言建模任务期间的速度要比 Vanilla Transformer 快 1800 多倍
由于对长期依赖关系进行建模,Transformer-XL 在处理长序列时的困惑度方面表现更优(即能够更加准确地预测样本)。另外,由于解决了上下文碎片化问题,其在处理短序列时也有更出色的性能表现
Transformer-XL 在 enwiki8 中将最优 bpc/困惑度从 1.06 提升到了 0.99;在 text8 中从 1.13 提升到了 1.08;在 WikiText-103 中从 20.5 提升到了 18.3;在 One Billion Word 中从 23.7 提升到了 21.8;在 Penn Treebank 中从 55.3 提升到了 54.5(未进行微调)。我们是首个在字符层级 LM 基准测试中突破 1.0 障碍的团队。
我们畅想了 Transformer-XL 的很多令人振奋的潜在应用,包括但不限于改进 BERT 等语言模型预训练方法,生成逼真的长篇文章,以及在图像和语音领域的应用,这也是长期依赖关系方面的重要领域。如需了解更多详情,请参阅我们的 论文。
注:论文 链接
https://arxiv.org/abs/1901.02860
您也可以在 GitHub 上的 Tensorflow 和 PyTorch 中查看我们在论文中使用的代码、预训练模型和超参数。
注:GitHub 链接
https://github.com/kimiyoung/transformer-xl
更多 AI 相关阅读:




