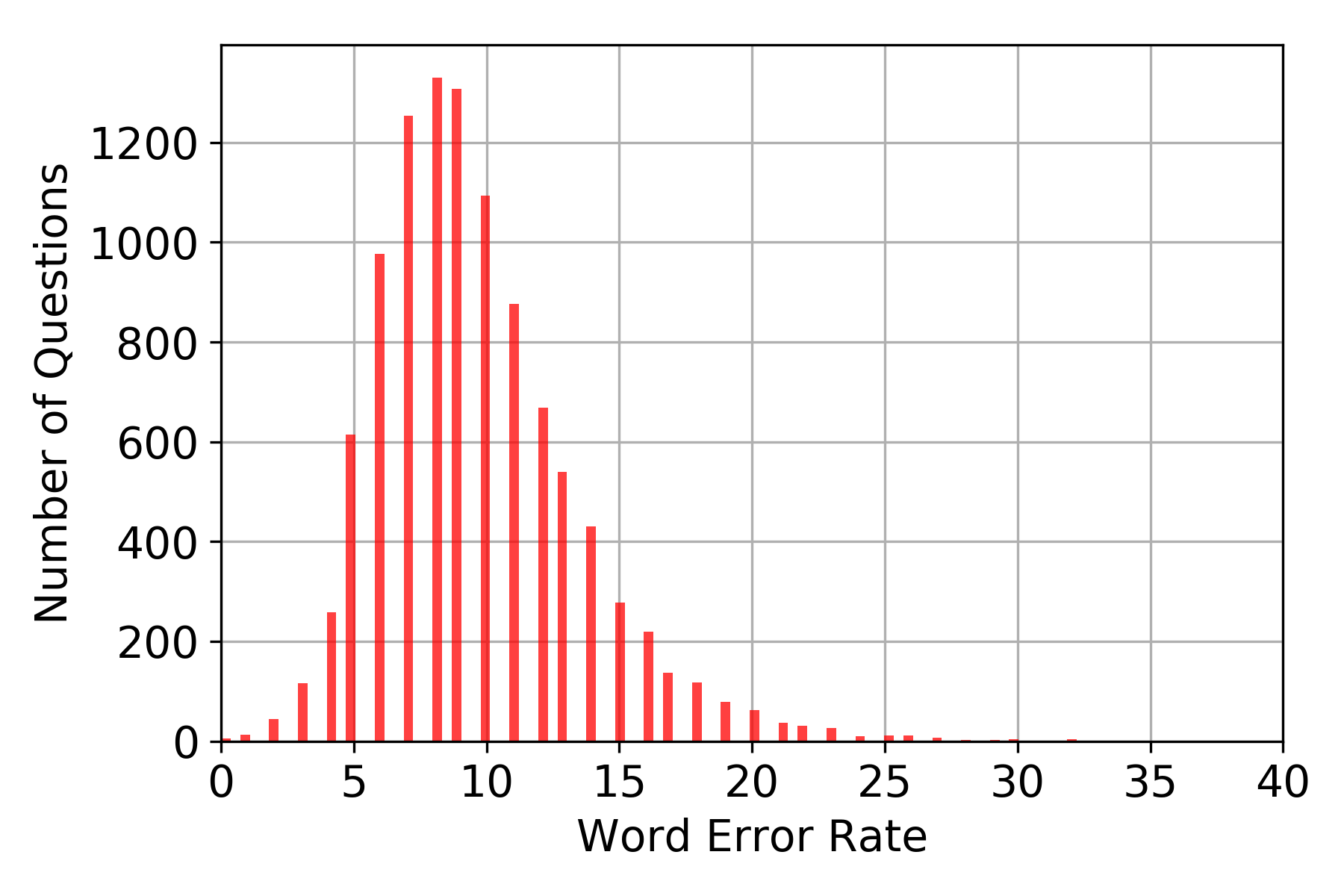
A machine learning model was developed to automatically generate questions from Wikipedia passages using transformers, an attention-based model eschewing the paradigm of existing recurrent neural networks (RNNs). The model was trained on the inverted Stanford Question Answering Dataset (SQuAD), which is a reading comprehension dataset consisting of 100,000+ questions posed by crowdworkers on a set of Wikipedia articles. After training, the question generation model is able to generate simple questions relevant to unseen passages and answers containing an average of 8 words per question. The word error rate (WER) was used as a metric to compare the similarity between SQuAD questions and the model-generated questions. Although the high average WER suggests that the questions generated differ from the original SQuAD questions, the questions generated are mostly grammatically correct and plausible in their own right.
翻译:开发了一个机器学习模型,以自动从维基百科段落中产生问题,使用变压器,这是一种关注模式,取代了现有经常性神经网络的范式。该模型在被倒置的斯坦福问答数据集(SQUAD)上接受了培训,该数据集由一群维基百科文章上的人群工作者提出的100 000+问题组成。经过培训,问题生成模型能够生成与隐蔽通道和答案有关的简单问题,每个问题平均包含8个单词。单词误差率(WER)被用作衡量标准,用以比较SQuAD问题与模型产生的问题之间的相似性。虽然高平均值WER认为产生的问题与原始的SQAD问题不同,但产生的问题大多在语法上是正确和可信的。