EMNLP 2018 | 为什么使用自注意力机制?
选自arXiv
作者:Gongbo Tang、Mathias Muller、Annette Rios、Rico Sennrich
机器之心编译
参与:路
近期,非循环架构(CNN、基于自注意力机制的 Transformer 模型)在神经机器翻译任务中的表现优于 RNN,因此有研究者认为原因在于 CNN 和自注意力网络连接远距离单词的路径比 RNN 短。本文在主谓一致任务和词义消歧任务上评估了当前 NMT 领域中最流行的三种模型:基于 CNN、RNN 和自注意力机制的模型,发现实验结果与上述论断并不一致。该论文已被 EMNLP 2018 接收。
多种不同架构对神经机器翻译(NMT)都很有效,从循环架构 (Kalchbrenner and Blunsom, 2013; Bahdanau et al., 2015; Sutskever et al., 2014; Luong et al., 2015) 到卷积架构 (Kalchbrenner and Blunsom, 2013; Gehring et al., 2017),以及最近提出的完全自注意力(Transformer)模型 (Vaswani et al., 2017)。由于框架之间的对比主要依据 BLEU 值展开,因此弄清楚哪些架构特性对 BLEU 值有贡献从本质上讲是比较困难的。
循环神经网络(RNN)(Elman, 1990) 可以轻松处理可变长度的输入句子,因此是 NMT 系统的编码器和解码器的自然选择。RNN 的大部分变体(如 GRU 和 LSTM)解决了训练循环神经网络的长距离依赖难题。Gehring 等人(2017)介绍了一种编码器和解码器都基于 CNN 的神经架构,并报告其 BLEU 值高于基于 RNN 的 NMT 模型。此外,该模型训练期间对所有分词的计算可以完全并行执行,提高了计算效率。Vaswani 等人(2017)提出 Transformer 模型,该模型完全基于注意力层,没有卷积或循环结构。他们报告该模型在英语-德语和英语-法语翻译取得了当前最优的 BLEU 值。但 BLEU 值指标比较粗糙,无法帮助观察不同架构如何改善机器翻译质量。
为了解释 BLEU 值的提高,之前的研究进行了理论论证。Gehring 等人(2017)和 Vaswani 等人(2017)都认为神经网络中共依赖因素(co-dependent element)之间的路径长度会影响模型学习这些依赖关系的能力:路径越短,模型学习此类依赖关系就越容易。这两篇论文认为 Transformer 和 CNN 比 RNN 更擅长捕捉长距离依赖。
但是,这一断言仅基于理论论证,并未经过实验验证。本文作者认为非循环网络的其它能力可能对其强大性能贡献巨大。具体来说,本文作者假设 BLEU 值的提高取决于具备强大语义特征提取能力的 CNN 和 Transformer。
该论文评估了三种流行的 NMT 架构:基于 RNN 的模型(下文用 RNNS2S 表示)、基于 CNN 的模型(下文用 ConvS2S 表示)和基于自注意力的模型(下文用 Transformer 表示)。受到上述关于路径长度和语义特征提取关系的理论陈述的启发,研究者在主谓一致任务(需要建模长距离依赖)和词义消歧(WSD)任务(需要提取语义特征)上对三种模型的性能进行了评估。这两项任务分别基于对照翻译对(contrastive translation pair)测试集 Lingeval97 (Sennrich, 2017) 和 ContraWSD (Rios et al., 2017)。
本论文的主要贡献如下:
检验了这一理论断言:具备更短路径的架构更擅长捕捉长距离依赖。研究者在建模长距离主谓一致任务上的实验结果并没有表明,Transformer 或 CNN 在这方面优于 RNN。
通过实验证明 Transformer 中注意力头的数量对其捕捉长距离依赖的能力有所影响。具体来说,多头注意力对使用自注意力机制建模长距离依赖是必要的。
通过实验证明 Transformer 擅长 WSD,这表明 Transformer 是强大的语义特征提取器。
论文:Why Self-Attention? A Targeted Evaluation of Neural Machine Translation Architectures

论文链接:https://arxiv.org/pdf/1808.08946.pdf
摘要:近期,非循环架构(卷积、自注意力)在神经机器翻译任务中的表现优于 RNN。CNN 和自注意力网络连接远距离单词的路径比 RNN 短,有研究人员推测这正是其建模长距离依赖能力得到提高的原因。但是,这一理论论断并未得到实验验证,对这两种网络的强大性能也没有其他深入的解释。我们假设 CNN 和自注意力网络的强大性能也可能来自于其从源文本提取语义特征的能力。我们在两个任务(主谓一致任务和词义消歧任务)上评估了 RNN、CNN 和自注意力网络的性能。实验结果证明:1)自注意力网络和 CNN 在建模长距离主谓一致时性能并不优于 RNN;2)自注意力网络在词义消歧方面显著优于 RNN 和 CNN。
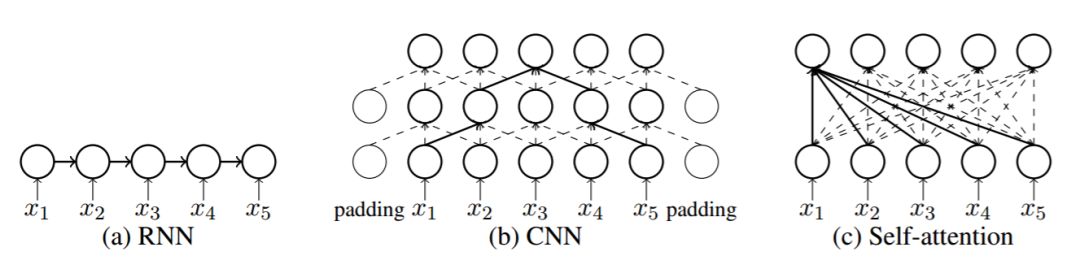
图 1:NMT 中不同神经网络的架构。
主谓一致
主谓一致任务是评估模型捕捉长距离依赖能力的最流行选择,曾在多项研究中使用 (Linzen et al., 2016; Bernardy and Lappin, 2017; Sennrich, 2017; Tran et al., 2018)。因此,我们也使用该任务评估不同 NMT 架构的捕捉长距离依赖能力。
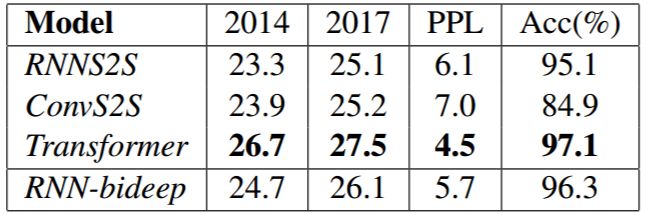
表 2:不同 NMT 模型的结果,包括在 newstest2014 和 newstest2017 上的 BLEU 值、在验证集上的困惑度,以及长距离依赖的准确率。
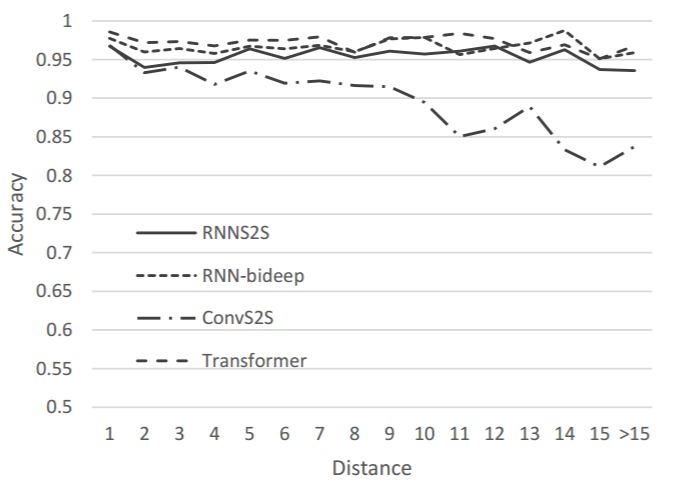
图 2:不同的 NMT 模型在主谓一致任务上的准确率。
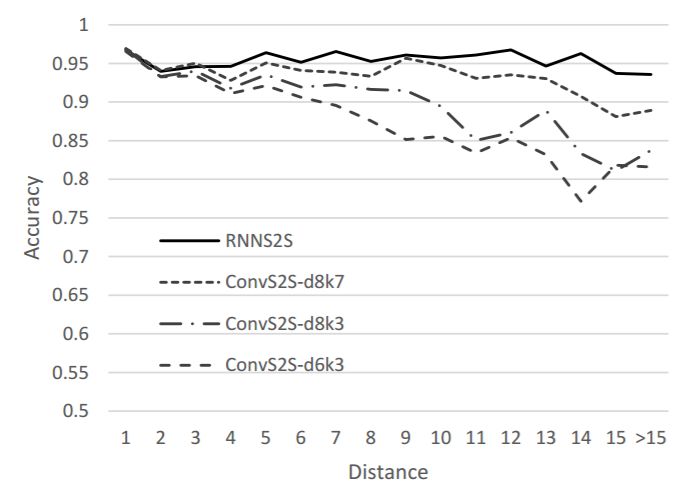
图 3:ConvS2S 模型和 RNNS2S 模型在不同距离处的结果。
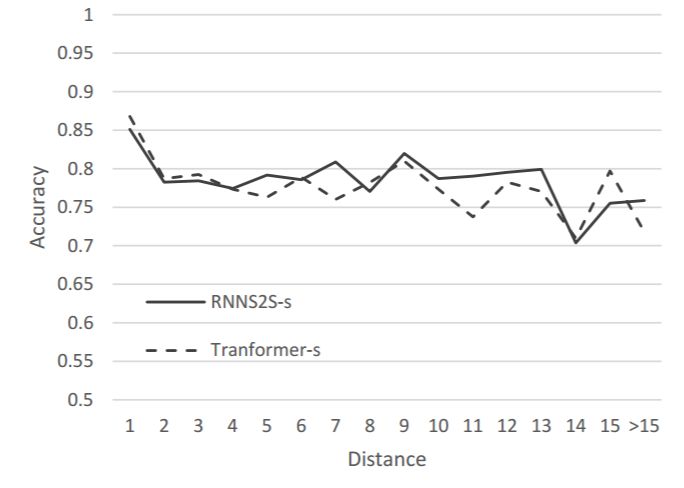
图 4: 在小型数据集上训练的 Transformer 和 RNNS2S 模型的结果。
WSD
主谓一致任务上的实验结果展示了 CNN 和 Transformer 在捕捉长距离依赖方面并没有优于 RNN,即使 CNN 和 Transformer 中的路径更短。这一发现与上文提到的理论断言相悖。但是,从 BLEU 值来看,这些架构在实验中的表现都很不错。因此,我们进一步在 WSD 任务上评估这些架构来验证我们的假设:非循环架构更擅长提取语义特征。
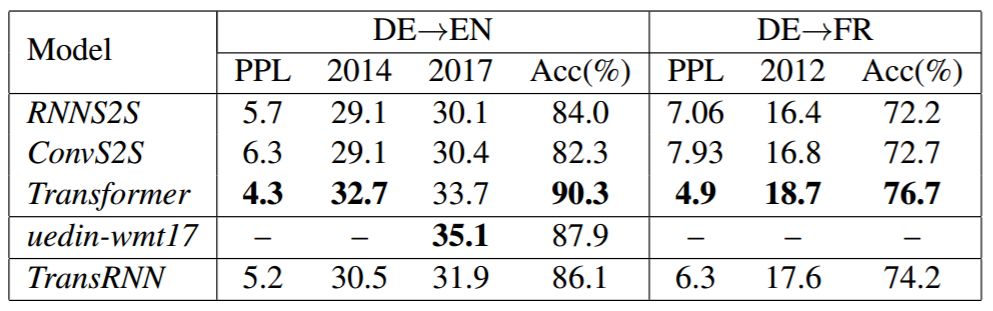
表 5:不同架构在 newstest 数据集和 ContraWSD 上的结果。PPL 指在验证集上的困惑度。Acc 表示在测试集上的准确率。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com




