学界 | 对比对齐模型:神经机器翻译中的注意力到底在注意什么
选自arXiv
机器之心编译
参与:李亚洲、刘晓坤、路雪
神经机器翻译近来广受关注,基于注意力的NMT逐渐流行。但是,很少有研究分析注意力到底在「注意」什么?它与对齐一样吗?本文将对此进行分析。
神经机器翻译(NMT)近期备受关注,它极大地改进了多种语言的机器翻译质量,取得了顶级的结果。神经机器翻译模型的核心架构基于常见的编译器-解码器方法,学习把源语言编码成分布式表征,并把这些表征解码成目标语言。在不同的神经机器翻译模型中,基于注意力的 NMT 逐渐流行,因为它在每一翻译步使用源句最相关的部分。这一能力使得注意力模型在翻译长句时极为优秀。
从 2015 年 Bahdanau 等人的论文将注意力模型引入神经机器翻译以来,出现了各种变体。然而,少有研究分析「attention」到底捕捉到了什么现象。有一些研究认为 attention 与传统的词对齐类似,一些方法也尝试使用传统的词对齐来训练注意力模型,实验结果表明注意力模型也可被视为重排序模型(reordering model)和对齐模型(alignment model)。
但在此论文中,作者调查了注意力模型和对齐模型之间的区别,以及注意力机制到底捕捉到了什么。论文旨在解答两个问题:注意力模型只能做对齐吗?在不同的句法现象中注意力与对齐的类似程度有多大?
该论文的贡献有:
提供了 NMT 中的注意力机制与词对齐的详细对比。
虽然不同的注意力机制会与词对齐有不同程度的符合度,但完全符合对词预测而言不总是有利的。
研究表明根据生成的词类型,注意力也会有不同的模式。
研究证明注意力并不总是符合对齐机制。研究表明注意力与对齐的区别源于注意力模型关注当前要翻译词的上下文,这会影响当前词的翻译结果。
论文:What does Attention in Neural Machine Translation Pay Attention to?

论文链接:https://arxiv.org/pdf/1710.03348.pdf
摘要:神经机器翻译的注意力机制提供了在每一个翻译步中编码源句最相关部分的可能性,因此注意力机制通常被当做对齐模型。然而,目前并没有论文专门研究注意力机制,分析注意力模型究竟学到了什么。所以,关于注意力机制和传统对齐模型的相似性和区别的问题仍然没有答案。在这篇论文中,我们对注意力机制进行了详细分析,并和传统的对齐模型作了比较。对于注意力机制只能做词对齐,还是能捕捉更多信息,我们给出了解答。我们的研究表明,对于某些案例,注意力机制和对齐模型是不同的,注意力能够捕捉到更多有用的信息。
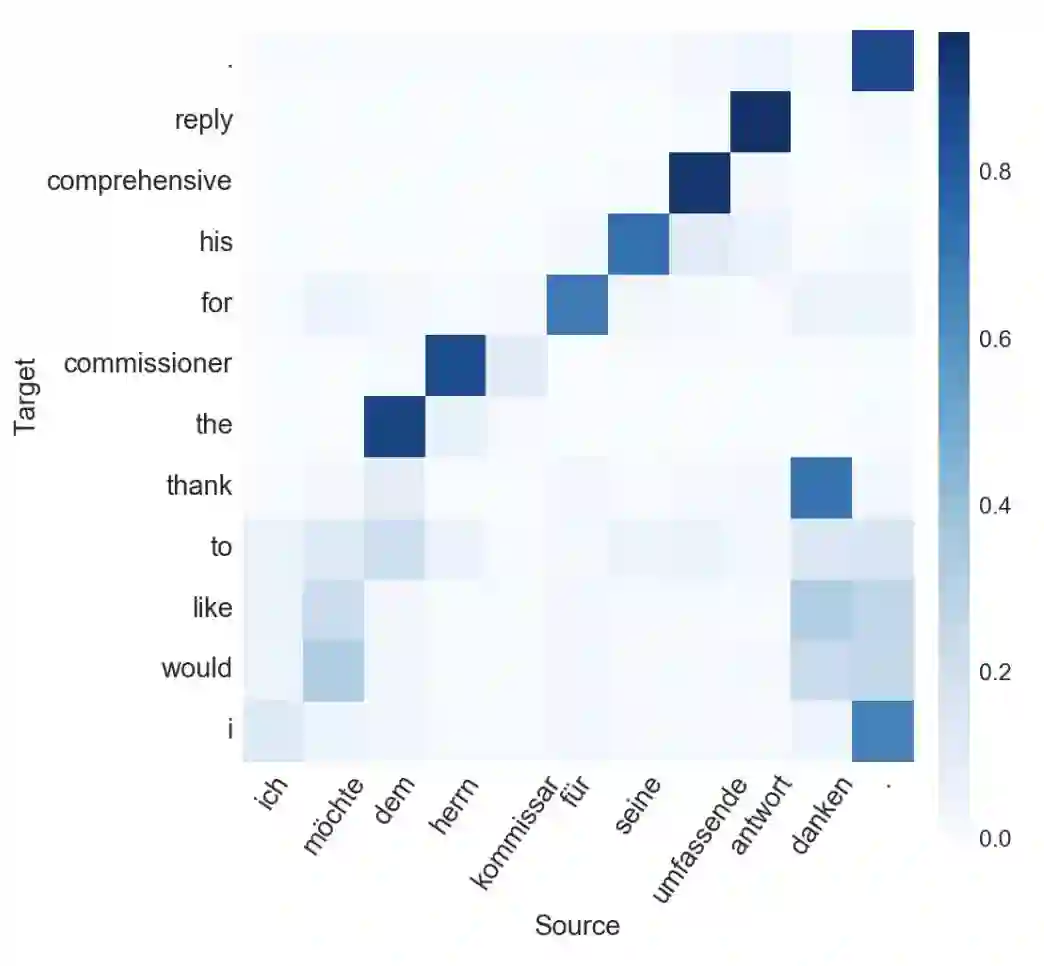
图 1:翻译样本中每一个生成词的源句子最相关部分的注意力可视化。我们可以看到在「would」和「like」的例子中,注意力是如何在多个源词中「弥散」开的。
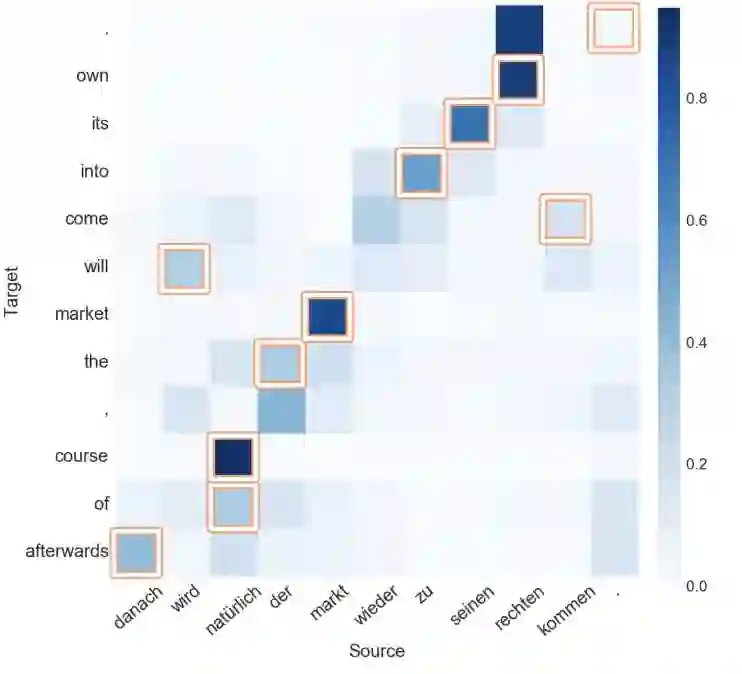
图 2:注意力和对齐不一致的例子。带边框的单元格展示了 RWTH 数据集手工对齐的结果(见表 1)。我们可以看到在「will」和「come」的例子中,注意力是如何偏离对齐点的。

表 1:RWTH 德英数据集提供的手动对齐统计数据。
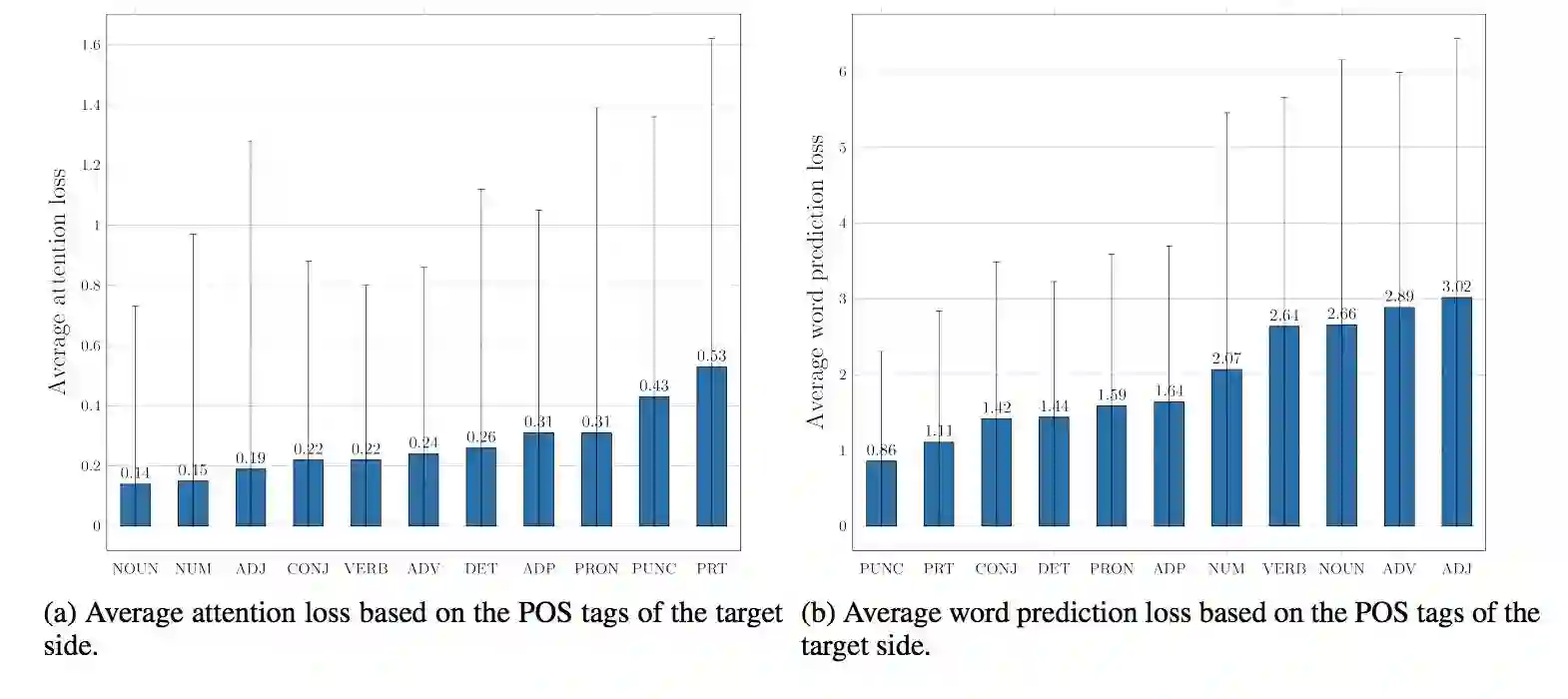
图 3:输入-馈送系统(input-feeding system)的平均注意力损失和平均词预测损失。
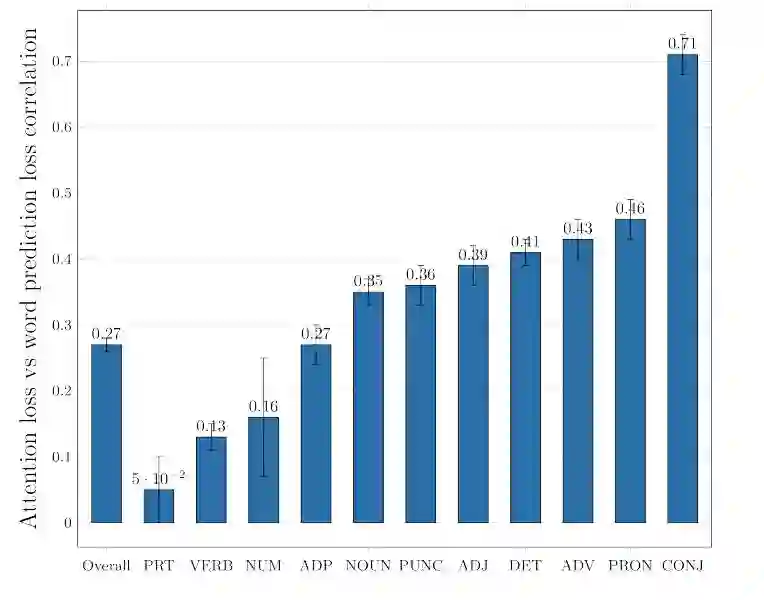
图 4:输入-馈送模型的词预测损失和注意力损失之间的相关性。
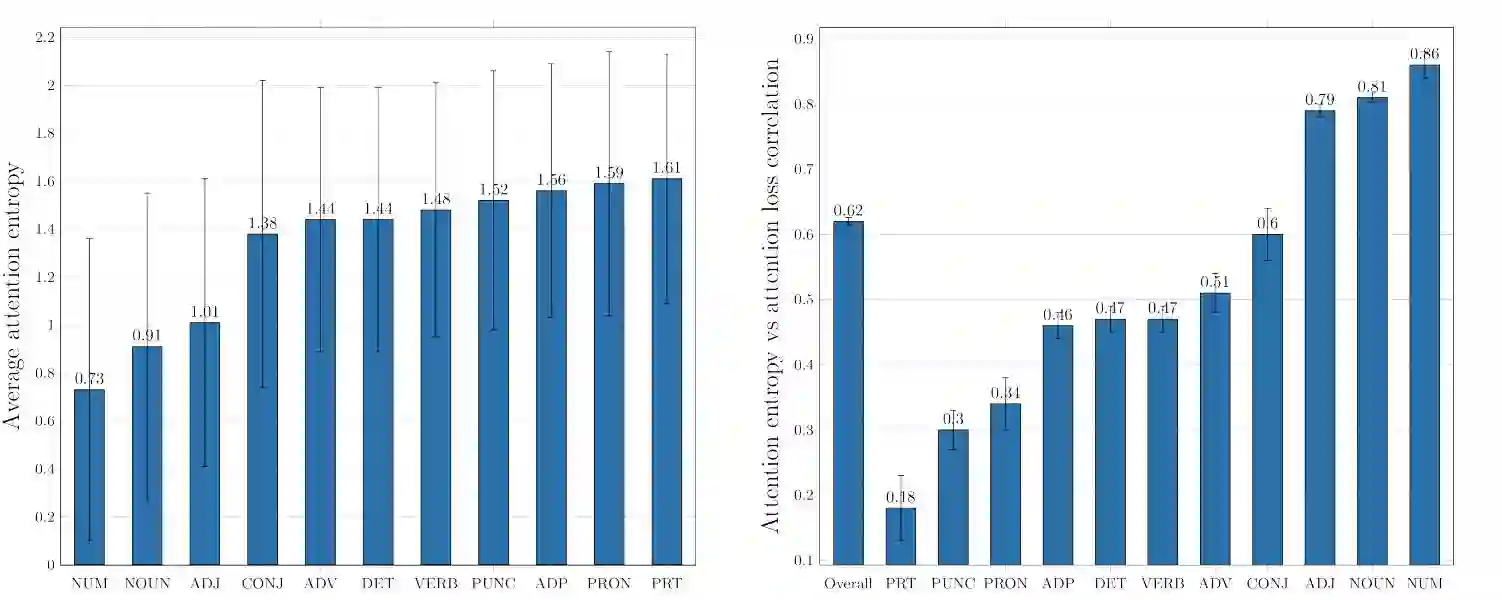
图 5:输入-馈送模型的注意力熵(attention entropy)及其与注意力损失之间的相关性。
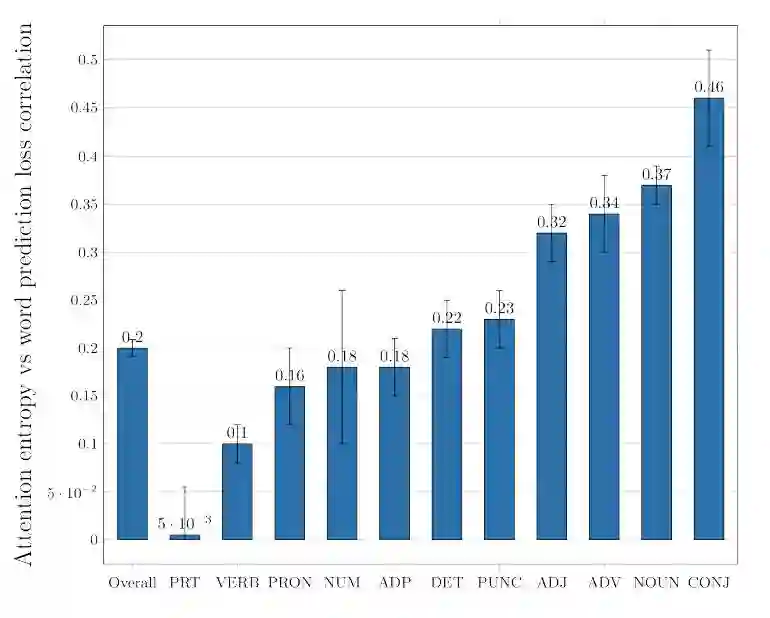
图 6:输入-馈送系统的注意力熵和词预测损失之间的相关性。
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



