【论文导读】2022年论文导读第九期


论文导读
2022年论文导读第九期(总第四十九期)
目 录
|
1 |
Source Data-Free Unsupervised Domain Adaptation for Semantic Segmentation |
|
2 |
Weight Evolution: Improving Deep Neural Networks Training through Evolving Inferior Weight Values |
|
3 |
AdvHash: Set-to-set Targeted Attack on Deep Hashing with One Single Adversarial Patch |
|
4 |
LSTC: Boosting Atomic Action Detection with Long-Short-Term |
|
5 |
Boosting mobile CNN Inference for Semantic Memory |
|
6 |
BridgeNet: A Joint Learning Network of Depth Map Super-Resolution and Monocular Depth Estimation |
01
Source Data-Free Unsupervised Domain Adaptation for Semantic Segmentation
作者:叶慕聪,张晶,欧阳金鹏,袁丁
单位:北京航空航天大学
邮箱:
mucongye@buaa.edu.cn,
zhang_jing@buaa.edu.cn,
oyjp965445220@buaa.edu.cn,
dyuan@buaa.edu.cn
论文:
https://dl.acm.org/doi/abs/10.1145/3474085.3475384
1.引言
基于深度学习的语义分割算法通常需要大量带有像素级标注的训练图像。用于语义分割的无监督域适应 (UDA) 可以将具有低成本标注的合成数据(源域)中学到的知识迁移到真实图像(目标域)。然而,当前的 UDA 方法大多需要完全访问源域数据以进行可行的领域自适应,这限制了它们在具有隐私、存储或传输问题的现实场景中的应用。为此,本文提出在禁止访问原始源域数据的情况下的用于语义分割的 UDA 问题和方法,这个问题更切合实际但更具挑战性。换言之,本文旨在基于预训练的源模型和未标记的目标域数据提高目标域语义分割性能。为了解决这个问题,本文提出通过选择由预训练源模型预测的目标域高置信度样本来构建一组源域虚拟数据来模拟源域分布。然后通过分析跨域语义分割任务中的数据特性,提出了一种不确定性和先验分布感知域自适应方法,将虚拟源域和目标域与对抗学习和自训练策略对齐。对三个跨域语义分割数据集的广泛实验和深入分析验证了所提出方法的有效性。
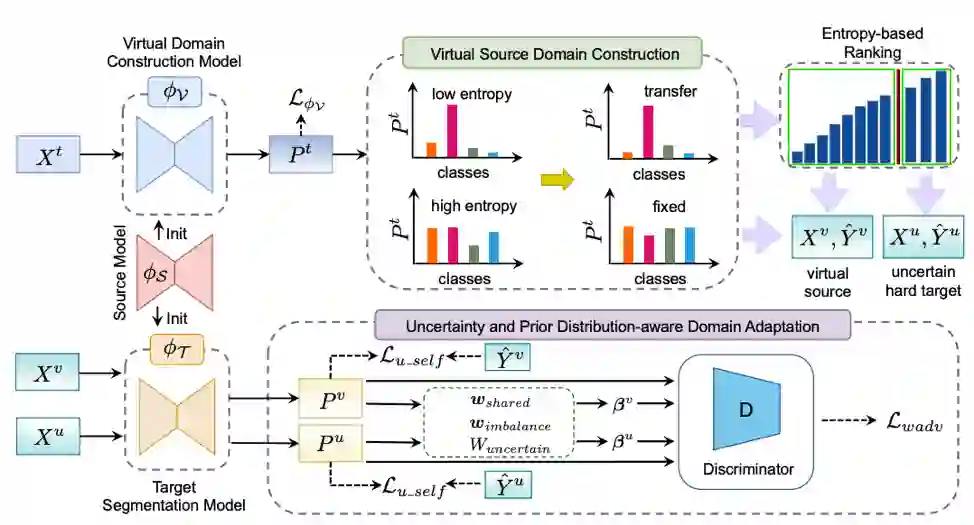
图1 基于虚拟源域构建和不确定性和考虑先验分布差异的领域自适应方法框架。
2.方法概述
如图1所示,本文分析总结了现有跨域语义分割算法的缺点和局限性,提出了一个两阶段方法:1)虚拟源域构建阶段,2)考虑先验分布的不确定性感知自适应阶段。
具体而言,在第一阶段,为了有效提高目标域的语义分割性能,提出一种虚拟源域构建方式,用于后续的域适应任务。通过观察到源预训练模型对源域样本的预测往往具有部分低熵的高置信预测,本文提出通过基于源预训练模型估计的像素级预测类别分布熵来识别目标域高置信度样本来模拟源域分布。为了进一步缩小虚拟源域和真实源域之间的分布差距,提出了一种正则化加权熵最小化方法,选择与源域数据分布接近的目标样本作为虚拟源域。
在第二阶段,为了减小目标域与源域数据的分布差异,利用了基于对抗训练的域对齐方法和基于自训练的伪标记方法。与现有有方法不同,通过观察特定于跨域语义分割任务的一些被忽视的数据属性和先验知识,例如,在语义分割任务中存在来自不同域的两个图像之间存在物体类别不匹配问题;每个图像内存在的类别不平衡问题;由于虚拟源域和目标域均无标注数据,域对齐时需要考虑预测不确定性,从而确定对齐方向。通过考虑这些数据特性和先验知识,提出了一种新的加权对抗学习方法,而非平等对待预测图的每个像素来对齐目标和虚拟源域。此外,基于贝叶斯深度学习,利用一种新颖的不确定性感知自训练方法来生成可靠的伪标签,从而摒弃了繁琐的手动阈值调整过程,并考虑模型不确定性以从嘈杂的伪标签中学习。
3.实验结果
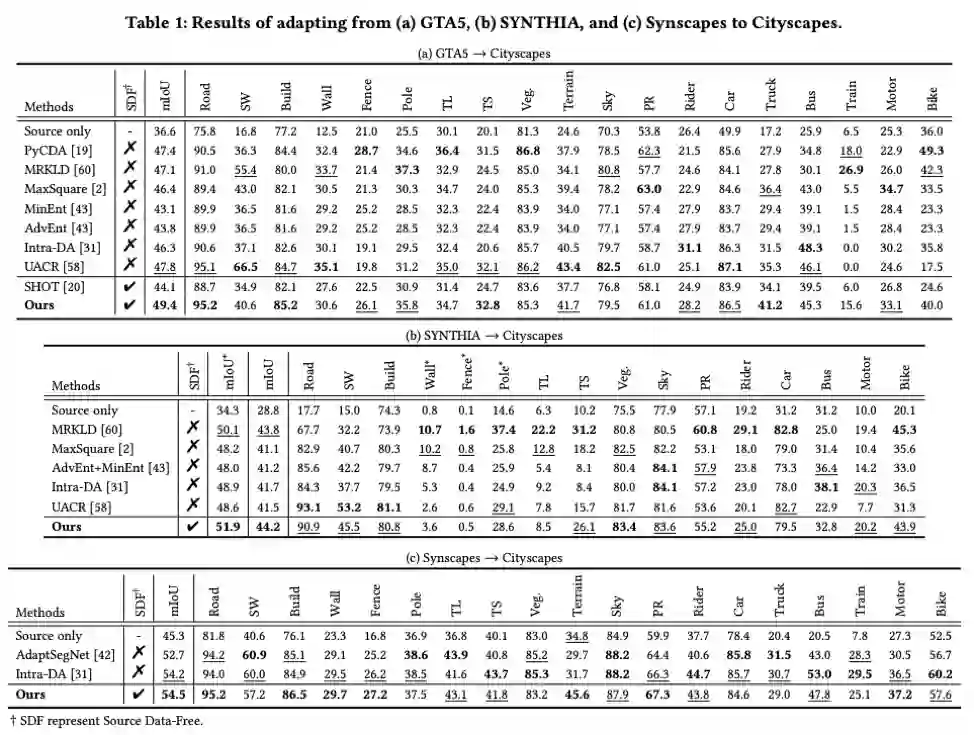
本文以Cityscapes作为目标域,GTA5、SYNTHIA、和Synscapes 分别作为源域进行实验验证。实验结果如表1所示,本文提出的方法在三组跨域语义分割任务上超越现有源域数据可访问方法。

02
Weight Evolution: Improving Deep Neural Networks Training through Evolving Inferior Weight Values
作者:林振泉1,郭锴凌1,*,邢晓芬1,2,徐向民1,3
单位:1华南理工大学,2华南理工大学-优必选联合实验室,3中山市华南理工大学现代产业技术研究院
邮箱:
zhenquan_lin@163.com,
guokl@scut.edu.cn,
xfxing@scut.edu.cn,
xmxu@scut.edu.cn,
论文:
https://doi.org/10.1145/3474085.3475376
代码:
https://github.com/BZQLin/Weight-evolution
*通讯作者
1. 引言
为了获得良好的性能,卷积神经网络通常会被过度参数化。这一现象激发了两个有趣的话题:(1) 修剪不重要的权值以进行模型压缩,(2) 重新激活不重要的权值以充分利用网络的能力。然而,目前的权重重新激活方法通常会重新激活整个神经元,这可能还不够精确。回顾网络剪枝的历史,神经元剪枝的繁荣主要是由于它对硬件实现的友好性,但在更精细的结构层次上的修剪,即权重元素,通常会导致更好的网络性能。本文研究了权值元素的重新激活问题。受到进化的启发,我们选择不重要的神经元,并将其与重要的神经元中的重要元素相结合,就像基因交叉产生更好的后代一样,本文所提出的方法称为权重进化(WE)。
2. 方法概述
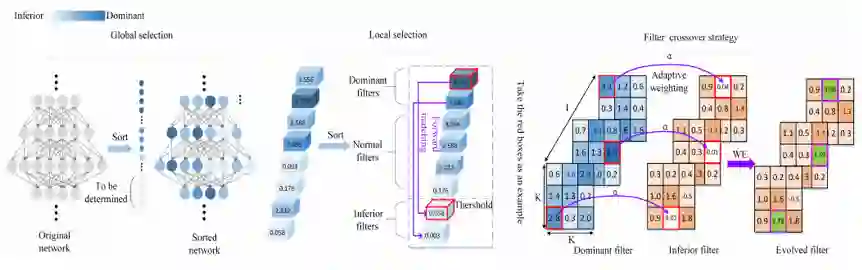
图1 权重进化整体示意图
如图1所示,本文所提出的方法包含了四种策略。(1) 全局选择策略,初步筛选,定位神经网络中不重要的神经元所在的层。(2) 局部选择策略,根据在特定层中神经元的相对重要性,在这些层中选择最终的不重要神经元。结合全局和局部选择策略可以精准定位不重要的神经元。(3) 前向匹配策略,寻找匹配的重要神经元,保持神经元的相对大小顺序。(4) 自适应权重激活策略,利用重要神经元中的重要元素来激活不重要的神经元,使得重激活后的神经元能有效携带重要神经元的信息。
3. 实验结果
本文在常见的数据集CIFAR-10,CIFAR-100和ImageNet上做了相关实验。实验结果表明,对于典型的卷积神经网络,尤其是轻量级网络,本文提出的方法相比于其他网络重激活方法取得了更好的分类效果。
表1 与传统网络在CIFAR数据集上的准确率(%)比较
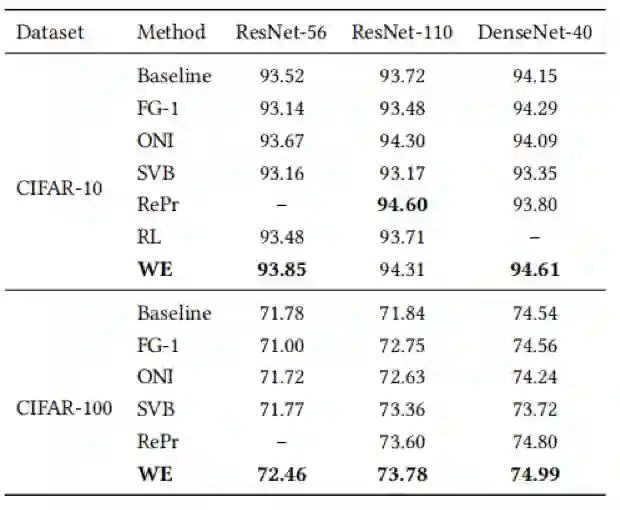
表2 与轻量化网络在CIFAR数据集上的准确率(%)比较
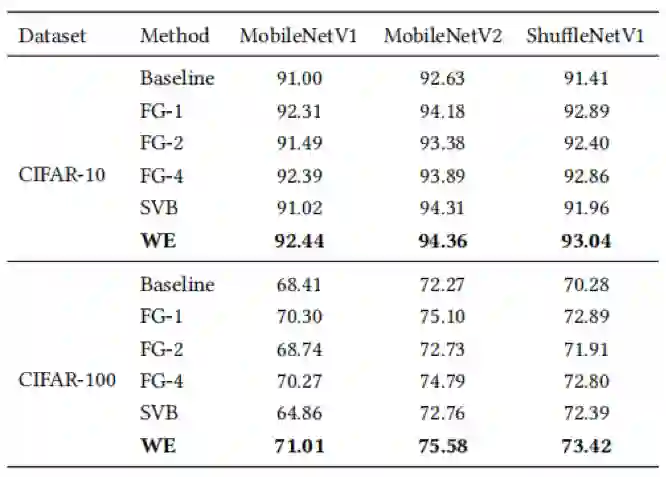
表3 不同方法关于ResNet-34网络在ImageNet数据集上的准确率(%)比较
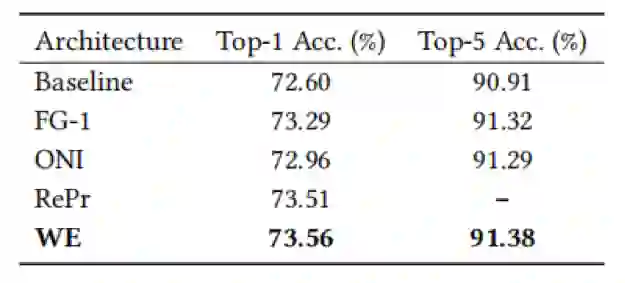
表4 不同方法关于MobileNetV2-0.5网络在ImageNet数据集上的准确率(%)比较,训练和测试的图像大小都是128x128

03
AdvHash: Set-to-set Targeted Attack on Deep Hashing with One Single Adversarial Patch
作者:胡胜山1,张业超1,刘晓耕1,Leo Yu Zhang2,李明慧3†,金海4
单位:1华中科技大学网络空间安全学院,2迪肯大学,3华中科技大学软件学院,4华中科技大学计算机学院
邮箱:
hushengshan@hust.edu.cn,
ycz@hust.edu.cn,
liuxiaogeng@hust.edu.cn,
liuxiaogeng@hust.edu.cn,
leo.zhang@deakin.edu.au,
minghuili@hust.edu.cn,
论文:
https://mp.weixin.qq.com/s/3pJUogMCoY2AI1lQUAi_aQ
代码:
https://github.com/CGCL-codes/AdvHash
†通讯作者
1.背景与动机
深度学习技术已经逐渐成为多媒体领域领先的解决方案,但其安全性也引起了人们的极大关注与担忧。具有大规模高效率的深度哈希图像检索技术已在各种商用检索系统中得到了广泛应用,而其对抗脆弱性的研究工作还存在着多种局限,全面的考虑深度哈希的脆弱性对于构架更鲁棒的高效检索方案具有指导性意义。现有针对深度哈希图像检索的对抗攻击方案具有三项弱势:1)所有方案都局限于对抗绕动。2)所有方案生成的对抗噪声并不具有泛化性,很难实现高效率的批量攻击。3)多数方案只能实现无目标攻击,而具有极高危害性的有目标攻击的探索还不够全面。为此,我们期望针对深度哈希检索系统实现基于对抗补丁的具有泛化性的有目标攻击,并设计出了AdvHash。如图1所示,AdvHash能够同时突破上述三个约束条件,一个局部的对抗补丁可以适用于同种标签的所有图像,并欺骗目标检索系统返回指定标签的样本。
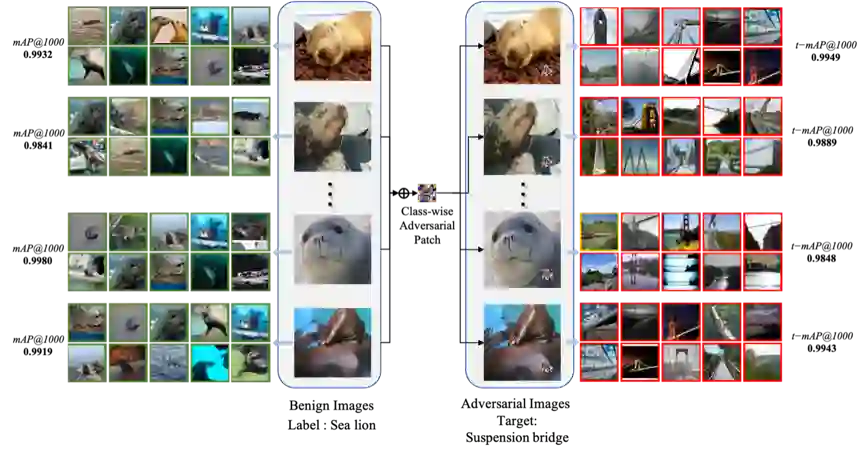
图1 AdvHash攻击效果示意图
2. 方案概述
我们将实现具有泛化性的有目标指向性的对抗噪声视为一个集到集的问题。为有效地求解该问题以及高效率地生成具有泛化性对抗噪声,我们从优化算法、梯度聚合和预防过拟合这三个层面分别考虑设计了更佳的策略:
1)集到集的优化需要拉小每一个“原始-目标”样本对的距离,这种优化策略不仅需要O(n2)的搜索复杂度和计算开销,且很难达到稳定的收敛,于是我们采用了投票算法得到一个目标锚点来代替攻击的目标集合。
2)为了实现对抗噪声的适用泛化性,对抗噪声的更新不能仅仅依赖于某一张图片,而是要对来自于整个mini-batch(小批次)的所有图片的梯度进行聚合。如图2所示,我们提出了动态的加权梯度聚合策略。
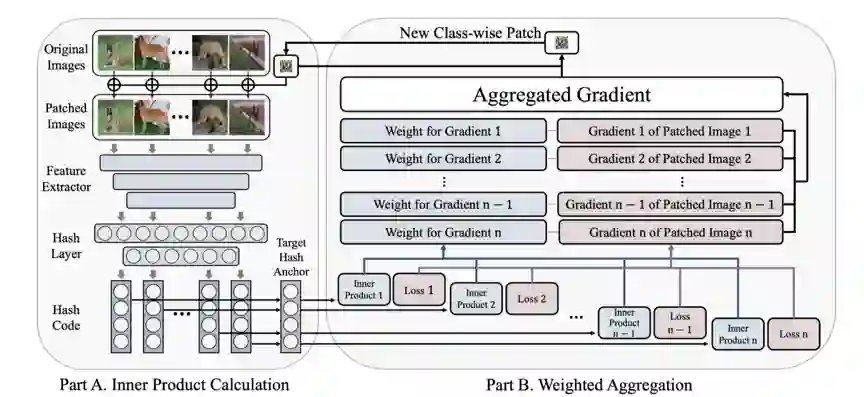
图2 加权梯度聚合策略
3)我们发现对抗噪声对当前mini-batch的样本实现了局部的泛化性,但是对未见过的mini-batch适用性很低。为此,我们采用了一种简单却十分有效的平均策略,通过选取前几个mini-batch的噪声的平均作为新的mini-batch的起始噪声开始训练可以很好的预防过拟合。
3、实验结果
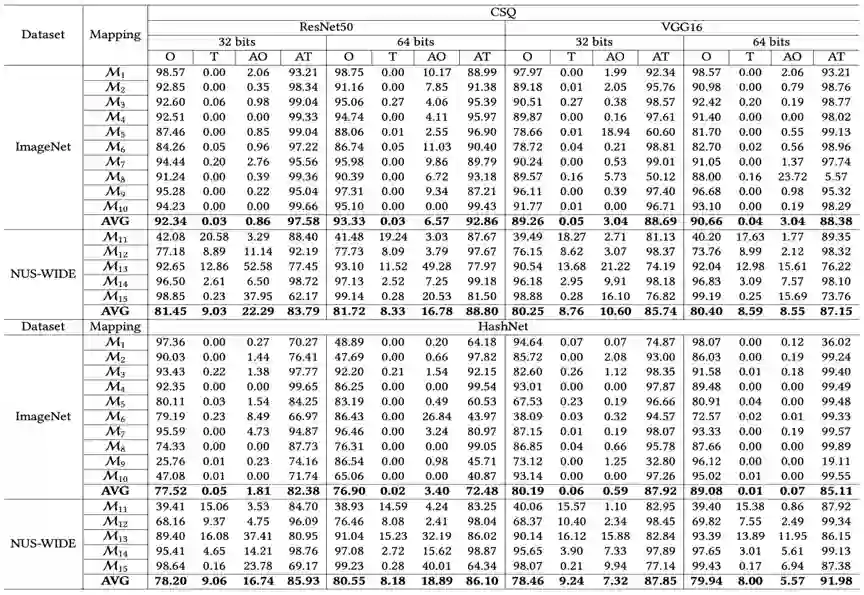
如表1所示,我们对两个业界领先的深度哈希算法HashNet和CSQ进行了对抗脆弱性评估。从mAP的急剧下降和t-mAP的显著上升表明被对抗样本在哈希空间中已经成功地离开了原来的聚类,进入了目标聚类。
表1 在CSQ和HashNet上对每个映射的攻击表现
04
LSTC: Boosting Atomic Action Detection with Long-Short-Term
作者:李昱希,张博深,李剑,王亚彪,林巍峣,汪铖杰,李季凛,黄飞跃
单位:腾讯优图,上海交通大学
邮箱:
yukiyxli@tencent.com,
boshenzhang@tencent.com,
swordli@tencent.com,
caseywang@tencent.com,
wylin@sjtu.edu.cn,
jasoncjwang@tencent.com,
jerolinli@tencent.com,
garyhuang@tencent.com
论文:
https://arxiv.org/abs/2110.09819
代码:
https://github.com/TencentYoutuResearch/ActionDetection-LSTC
引言
视频信号具有极强的时空相关性,因此视频中的高级语义信息的判别往往需要借助大量的上下文信息帮助判断。2018年,google提出atomic visual action (原子视觉行为)的概念并提出了新的视频理解任务--原子行为检测,该任务中,视频人物的行为被进行了更加精细的划分,不同的行为表现出不同的时空以来特性(如图1)所示,有的短时行为(如打电话,站立)涉及到动作发生对象与当前环境的交互,而有的长时以来关系(如交谈)涉及不同镜头下的人物关系;本文从这一特性出发,设计了一种长短时上下文依赖独立解耦的行为检测方法,将两种依赖关系独立建模进行推断,提升算法在细粒度的视频行为理解和检测上的效果。

图1 视频中不同时空依赖关系下的行为
方法概论
为实现不同时空关系下的上下文依赖建模,本文首先建立如图2所示的概率图模型,给定视频中的行为主体V, 可以直接关系到上下文空间中的不通隐变量Zl和Zs,分别表示V在视频中的长时和短时依赖关系,且在给定该主体的情况下条件独立,即长时以来的行为与短时依赖关系无关,反之亦然。针对不同的依赖关系,本文设计不同的结构分别建模P(Zl|V)和P(Zs|V)进行独立推断。
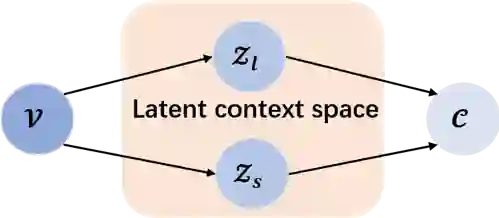
图2 长短时依赖概率图模型
针对短时的依赖,本文将同一镜头下的短时视频片段提取视频特征,并通过ROI操作提取行为主体的特征,通过在片段内进行注意力机制加权得到短时特征描述,该特征能够反映主体行为在较短的视频片段中的依赖关系(如图3所示)。

图3 短时依赖关系上下文可视化
针对长时的上下文关系,考虑到行为主体在一定的观测区间内会设计到多个交互对象,本文设计了一种结合长时特征记忆(Long-term Feature Bank)的二阶注意力机制,将长时依赖的注意力机制改良为多个行为主体的交互关系,而非两个行为主体对之间的交互,并通过解耦的方式,将计算的复杂度O(n2)从降低至O(n),实现等价计算结构(如图4所示)
长时和短时依赖在给定行为主体特征后,独立建模不同依赖关系下的原子行为类型分布,最后通过一个归一化集成操作得到最终的行为类别判断。
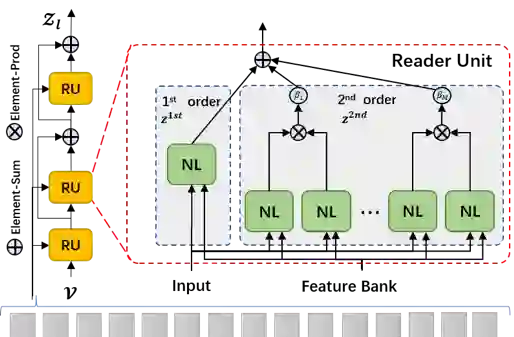
图4 结合二阶注意力机制的长时特征记忆
实验结果
结合实验,我们发现不同的长短时依赖关系能够有效提升我们的基准算法在原子行为检测上的能力,同时该算法相对灵活,长短时上下文的特征提取和建模可以通过不同的深度网络获得。与既有算法相比,该方案在AVA, HiEve等数据集上均取得较优的效果。
表1 不同上下文关系对效果的影响
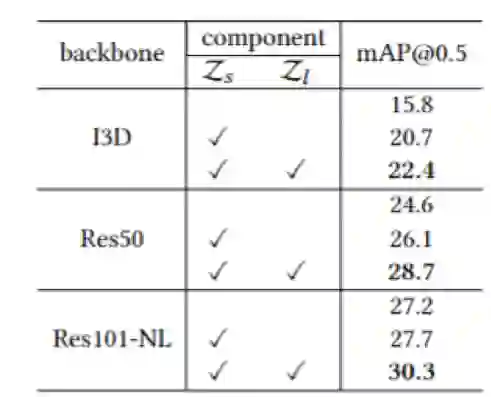
表2 不同上下文特征组合的效果
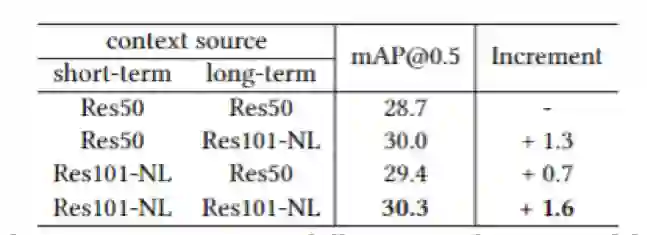
表3 AVA v2.2下与其他方法比较
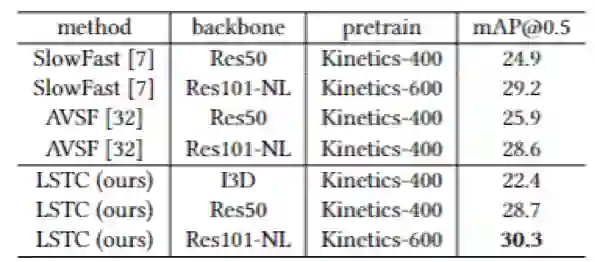

图5 不同长短时上下文独立推断的行为结果
05
Boosting mobile CNN Inference for Semantic Memory
作者:李运1,张宸2, *,韩世豪3,张丽4,殷保群1, *,刘云新5,徐梦炜6
单位:1中国科学技术大学,2阿里巴巴达摩院,3Rose-Hulman Institute of Technology,4Microsoft Research,5清华大学智能产业研究院,6北京邮电大学
邮箱:
yli001@mail.ustc.edu.cn,
mingchong.zc@alibaba-inc.com,
hans3@rose-hulman.edu,
lzhani@microsoft.com,
bqyin@ustc.edu.cn,
liuyunxin@air.tsinghua.edu.cn,
mwx@bupt.edu.cn,
论文:
https://dl.acm.org/doi/abs/10.1145/3474085.3475399
*通讯作者
1. 引言
生物学实验表明,人脑可以通过激活神经元上更快的记忆编码和访问来加快重复呈现对象的视觉识别,这种现象称为知觉启动效应(Priming Effect),如图1所示。受到上述启发,本文首次提出了语义记忆(Semantic Memory, SMTM),用于加速端侧卷积神经网络推理。SMTM采用图2所示的分层记忆架构来利用移动视频中感兴趣对象的长尾分布和时间局部性,并进一步提出了三种新的技术使其发挥推理加速的作用:1)SMTM将特征图中的高维信息编码为低维语义向量,通过构建“语义-类别”键值对,以实现高效的“记忆存储”和低成本高精度的“记忆查找”;2)考虑到不同网络层的固有特性,SMTM提出一种新的度量标准来确定退出推理的最佳时机;3)SMTM自适应地调整分层记忆区的缓存大小和语义中心以适应场景的动态变化。最终,SMTM在商业化卷积神经网络推理引擎上进行了原型设计,可在移动端CPU和GPU上执行神经网络的推理加速。
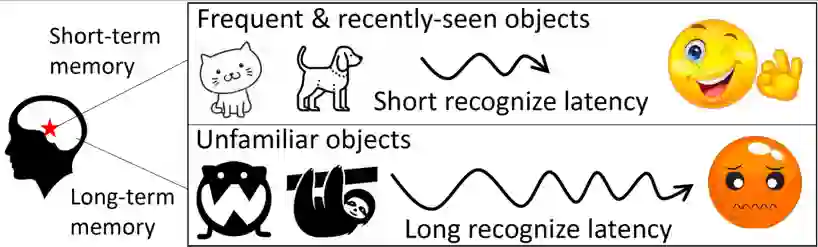
图1 知觉启动效应
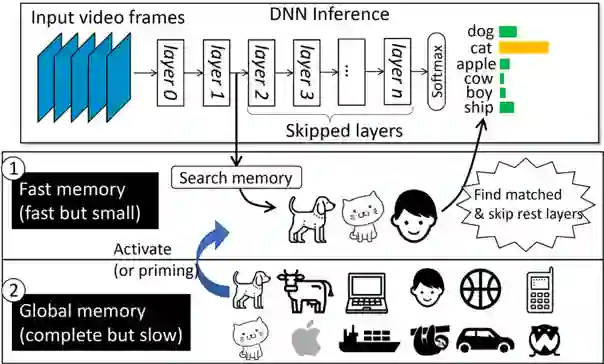
图2 SMTM核心思想
2. 方法概述
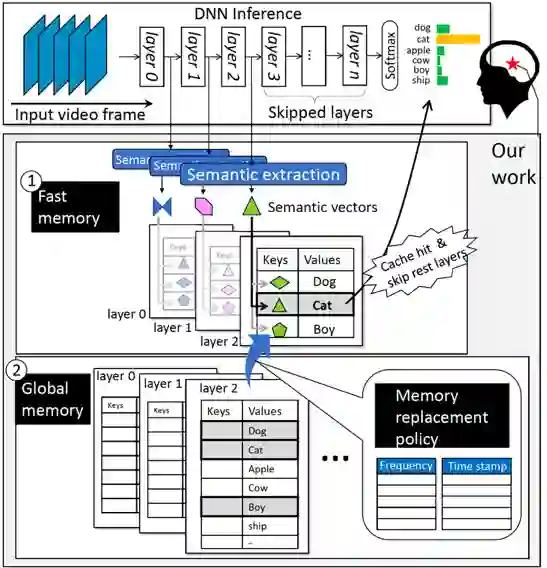
图3 SMTM工作流程
SMTM的整体工作流程如图3所示。SMTM引入了全局记忆单元和快速记忆单元来改进传统的 CNN 推理过程。其核心理念基于以下两个观察:1)长尾分布:移动视频中部分对象相比于其他对象更为常见。2)时间局部性:最近看到过的对象有更大可能在接下来的几帧中再次出现。在 CNN 推理过程中,SMTM逐层提取中间特征,并将它们与快速记忆区中的缓存特征进行匹配。
具体工作方式如下:首先,SMTM在训练集中提取的每个类别的特征表达,构建全局记忆;并在运行时关联“记忆”与类别出现的“频率”和“时间戳”。其次,SMTM通过判别时间戳和频率来激活一些热点类别,将其记忆内容从全局记忆单元提升到快速记忆单元中。在推断过程中,SMTM对每一层输出的特征图与快速记忆单元中的内容进行特征匹配。一旦匹配成功,SMTM将跳过其余层并直接输出最终结果。最后,SMTM更新频率表和时间戳表,这些表将定期用于缓存更新策略。
3. 实验结果
本文在商业化CNN推理引擎上搭建了 SMTM 的系统原型,并在 5 个流行的 CNN 架构、2 个大规模视频数据集以及移动CPU/GPU 硬件平台对其性能进行了全面评估。结果表明,与无记忆的方法相比,SMTM 实现了 1.2-2.0X 的加速和 13.7%-48.5% 的节能。相比先前提出的缓存系统(DeepMon和 DeepCache),SMTM实现了 1.1-1.5X 的加速。在上述结果的基础上,SMTM 仅带来较低的准确度损失(平均1.05%)和较少的内存占用开销(平均 2MB)。基于所提出的潜意识识别方式,本文的方法甚至可以达到比基线更高的识别准确度。
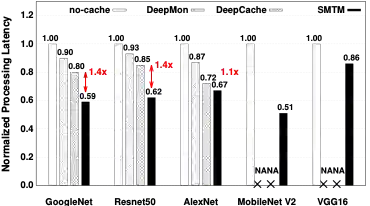
图4 SMTM在移动CPU(无SIMD)上的平均推理耗时
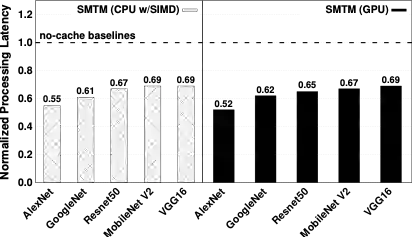
图5 SMTM在移动CPU(SIMD)和移动GPU上的平均推理耗时
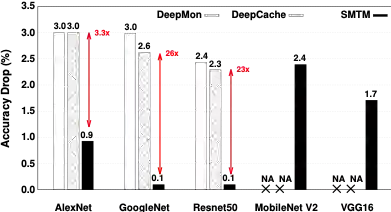
图6 SMTM的Top-1准确率损失
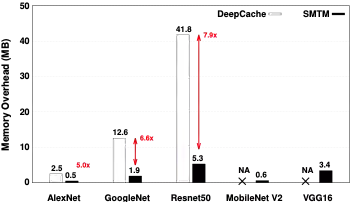
图7 SMTM在移动CPU(SIMD)和移动GPU上的平均推理耗时
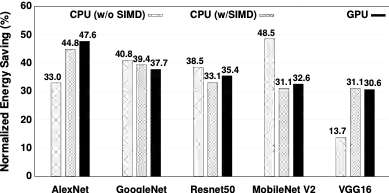
图8 SMTM的能耗节省情况
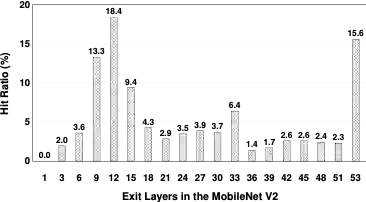
图9 SMTM在不同层的提前退出率(以MobileNet v2为例)
06
BridgeNet: A Joint Learning Network of Depth Map Super-Resolution and Monocular Depth Estimation
作者:Qi Tang1, Runmin Cong1, Ronghui Sheng1, Lingzhi He1, Dan Zhang2, Yao Zhao1, Sam Kwong3
单位:1北京交通大学信息科学研究所,2驭势科技,3香港城市大学
邮箱:
ronghuisheng@bjtu.edu.cn,
rmcong@bjtu.edu.cn
论文:
https://dl.acm.org/doi/10.1145/3474085.3475373
消便携式消费级深度相机的出现和普及,为准确快速地获取场景深度提供了极大的便利。但是,由于当前深度相机成像能力的限制,深度图像的分辨率通常较低。面对诸多应用领域对高质量深度图像的需求,深度图像超分辨率重建技术作为解决方案获得了广泛关注。现有彩色图像引导的深度图超分辨率方法通常需要额外的一个分支从RGB图像中提取高频细节信息来指导低分辨率深度图的重建。但是,由于两种模态之间存在差异,直接在特征维度或边缘图的维度上进行信息传输并不能达到满意的效果,甚至可能在RGB-D对的结构不一致的区域引发纹理复制等问题。本文从多任务学习的角度出发,提出了一种联合单目深度估计任务和深度图超分辨率任务的桥网络(BridgeNet),将两个任务纳入一个统一的框架中,并探索两个任务之间的交互指导关系,以达到相互促进、互利共赢的效果。
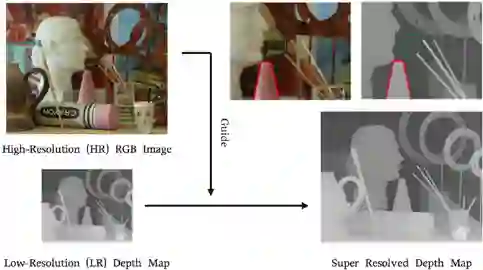
图1 彩色引导下的结构不一致问题
图2给出了网络的整体结构图,具体由两个子网络(即深度图超分辨率子网络DSRNet和单目深度估计子网络MDENet)和两个桥接器(即高频注意力桥接器HABdg和内容引导桥接器CGBdg)组成。深度图超分辨率子网络和单目深度估计子网络都采用了编码器-解码器的结构形式,可以利用现有的网络模型作为基线,两个子网络集成到一个统一的框架中进行联合学习。两个子网络的关联是通过桥接器实现的,高频注意力桥接器作用于编码阶段,学习单目深度估计任务的高频信息来指导深度图超分辨率任务,可以提供更接近深度模态的颜色引导信息;遵循简单任务引导困难任务的原则,在解码阶段内容引导桥接器为单目深度估计任务提供从深度图超分辨率任务中学习到的内容引导。整个网络体系结构是高度可移植的,可以为关联深度图超分辨率和单目深度估计任务提供范例。
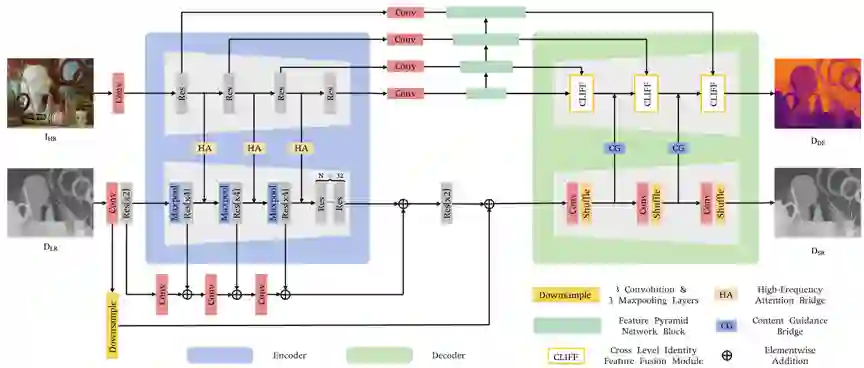
图2 网络框架图
表1 与其它方法在Middlebury数据集的定量比较结果
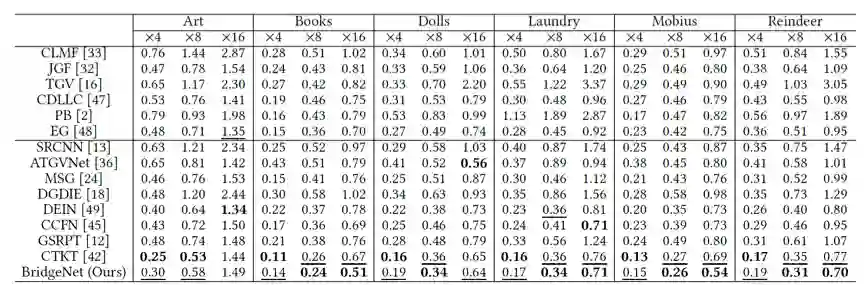
表2 与其它方法在NYU v2数据集的定量比较结果


图3 与其它方法×8倍数下的可视化比较结果。(a)真实深度图与彩色图;(b)LR深度图;(c)-(h)为生成的HR深度图块,分别来自Bicubic、TGV、MSG、DGDIE、CTKT以及BridgeNet模型。(i)真实深度图块。

编辑人:桑基韬、聂礼强
专委会责任副主任:徐常胜


