
【导读】作为世界数据挖掘领域的最高级别的学术会议,ACM SIGKDD(国际数据挖掘与知识发现大会,简称 KDD)每年都会吸引全球领域众多专业人士参与。今年的 KDD大会已经在这周线上举行(疫情影响)。KDD 2020官方发布接收论文,共有1279篇论文提交到Research Track,共216篇被接收,接收率16.8%。KDD 2020 Paper 都已经放出来了,为此,专知小编提前为大家整理了五篇KDD 2020 迁移学习(Transfer Learning)相关论文,供大家参考——对抗攻击、时序数据、半监督协同过滤、迁移集成学习、信息抽取
KDD2020 Accepted Papers https://www.kdd.org/kdd2020/accepted-papers
KDD2020RS、KDD2020GNN_Part2、KDD2020GNN、CVPR2020SGNN、CVPR2020GNN_Part2、CVPR2020GNN_Part1、WWW2020GNN_Part1、AAAI2020GNN、ACMMM2019GNN、
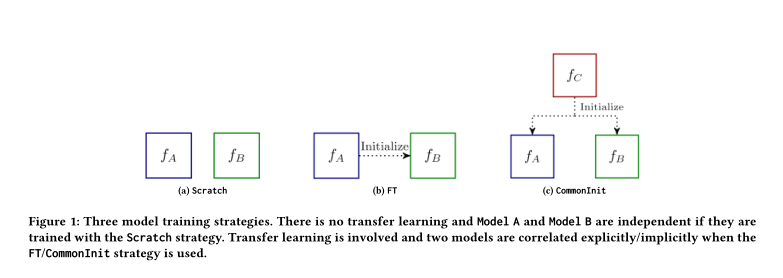
1、Two Sides of the Same Coin: White-box and Black-box Attacks for Transfer Learning
作者:Yinghua Zhang, Yangqiu Song, Jian Liang, Kun Bai, Qiang Yang
摘要:迁移学习已经成为在目标领域训练有限标签数据的深度学习模型的一种常见做法。另一方面,深度模型容易受到对抗性攻击。尽管迁移学习已得到广泛应用,但其对模型稳健性的影响尚不清楚。为了解决这个问题,我们进行了广泛的实验评估,表明这种微调方式有效地增强了模型在白盒FGSM攻击下的鲁棒性。我们还提出了一种针对迁移学习模型的黑盒攻击方法,该方法利用目标模型的源模型生成的对抗性示例攻击目标模型。为了系统地度量白盒攻击和黑盒攻击的效果,我们提出了一种新的度量来评估源模型产生的对抗性示例向目标模型迁移的程度。实验结果表明,与两个网络单独训练时相比,使用微调时的对抗性例子具有更强的可移植性。
网址:
https://dl.acm.org/doi/10.1145/3394486.3403349
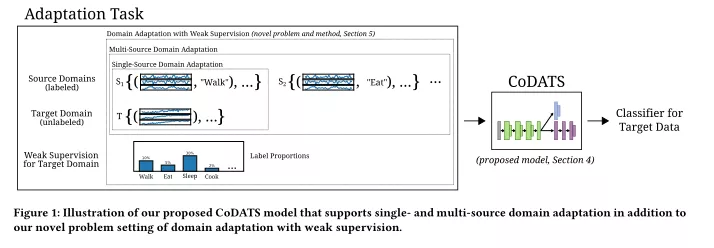
2、Multi-Source Deep Domain Adaptation with Weak Supervision for Time-Series Sensor Data
作者:Garrett Wilson, Janardhan Rao Doppa, Diane J. Cook
摘要:域自适应(DA)为重新使用新问题领域的数据和模型提供了一种有价值的手段。然而,对于时间序列数据,这些技术尚未被考虑。在本文中,我们主要做了三个方面的贡献来填补这一空白。首先,我们提出了一种新的用于时序数据的卷积深度域自适应模型(CoDATS),该模型在真实传感器数据基准上比现有的DA策略显著提高了准确率和训练时间。通过利用来自多个源域的数据,我们增加了CoDATS的有用性,以进一步提高先前的单源方法的准确性,特别是在域间具有高度变异性的复杂时间序列数据集上。其次,我们提出了一种新的弱监督领域自适应(DA-WS)方法,该方法利用目标领域标签分布形式的弱监督,可能比附加的数据标签更容易收集。第三,我们在不同的真实数据集上进行了全面的实验,以评估我们的领域自适应和弱监督方法的有效性。结果表明,单源DA的CoDATS比最先进的方法有了显著的改进,并且我们使用来自多个源域和弱监督信号的数据在准确率上取得了额外的改进。
网址: https://dl.acm.org/doi/10.1145/3394486.3403228
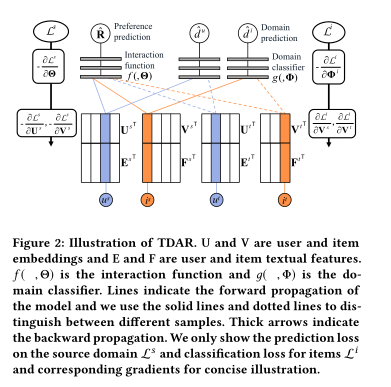
3、Semi-supervised Collaborative Filtering by Text-enhanced Domain Adaptation
作者:Wenhui Yu, Xiao Lin, Junfeng Ge, Wenwu Ou, Zheng Qin
摘要:在推荐系统中,数据稀疏是一个固有的挑战,其中大部分数据都是从用户的隐式反馈中收集的。这给设计有效的算法带来了两个困难:第一,大多数用户与系统的交互很少,没有足够的数据可供学习;第二,隐式反馈中没有负样本,通常需要进行负采样来生成负样本。然而,这会导致许多潜在的正样本被错误地标记为负样本,而数据稀疏会加剧错误标记问题。为了解决这些困难,我们将稀疏隐式反馈推荐问题看作一个半监督学习任务,并探索领域自适应来解决这个问题。我们将从密集数据中学到的知识转移到稀疏数据中,并将重点放在最具挑战性的案例âĂŤ上,该案列没有用户或项目重叠。在这种极端情况下,由于两个潜在空间编码的信息非常不同的,直接对齐两个数据集的嵌入是相当次优的。因此,我们采用领域不变的文本特征作为锚点来对齐潜在空间。为了对齐嵌入,我们提取每个用户和项目的文本特征,并将它们与用户和项目的嵌入一起馈送到领域分类器中。通过训练嵌入来迷惑分类器,并将文本特征固定为锚点。通过域自适应,将源域中的分布模式转移到目标域。由于目标部分可以通过领域自适应进行监督,因此我们放弃了对目标数据集的负采样,以避免标签噪声。
网址:
https://dl.acm.org/doi/10.1145/3394486.3403264
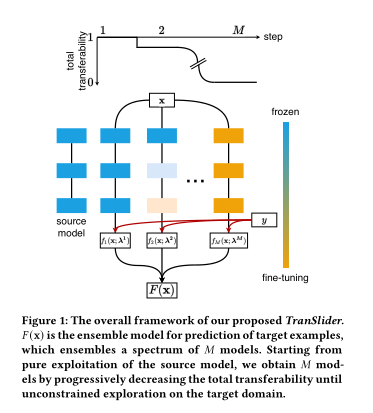
4、TranSlider: Transfer Ensemble Learning from Exploitation to Exploration
作者:Kuo Zhong, Ying Wei, Chun Yuan, Haoli Bai, Junzhou Huang
摘要:在迁移学习中,迁移什么、迁移到哪里已经得到了广泛的研究。然而,学习到的迁移策略有很高的过拟合风险,特别是当目标域中只有几个带标注实例时。在本文中,我们引入了迁移集成学习的概念,这是解决迁移策略过拟合问题的一个新方向。直观地说,具有不同迁移策略的模型提供了关于迁移什么以及迁移到哪里的不同视角。因此,一个核心问题是如何在这些不同迁移的模型中搜索集成,以达到更好的泛化。为此,我们提出了用于迁移集成学习的可迁移性滑块(TranSlider)。通过降低可迁移性,我们得到了从源模型的纯粹开发到对目标域的无约束探索的各种基本模型。此外,参数共享降低可迁移性的方式保证了在不增加训练成本的情况下快速优化。最后,我们对各种分析进行了广泛的实验,证明了TranSlider在综合基准数据集上达到了最先进的性能。
网址:
https://dl.acm.org/doi/10.1145/3394486.3403079
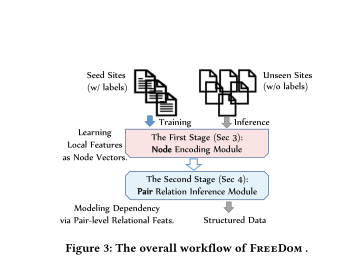
5、FreeDOM: A Transferable Neural Architecture for Structured Information Extraction on Web Documents
作者:Bill Yuchen Lin, Ying Sheng, Nguyen Vo, Sandeep Tata
摘要:从HTML文档中提取结构化数据是一个研究已久的问题,具有广泛的应用,如扩充知识库、支持分面搜索,以及为购物和电影等关键垂直领域提供特定领域的经验。以前的方法要么需要为每个目标站点提供少量示例,要么依赖于构建在网站视觉渲染之上的启发式方法。在本文中,我们提出了一种新的两阶段神经方法,称为FreeDOM,它克服了这两个限制。First阶段通过组合文本和标记信息来学习页面中每个DOM节点的表示。第二阶段使用关系神经网络捕获长距离和语义相关性。通过将这些阶段结合在一起,在不需要在页面的视觉呈现上花费昂贵的手工特征的前提下,Liberty能够从垂直方向对少量 seed sites 进行训练之后,将其推广到不可知的sites。通过在具有8个不同垂直方向的公共数据集上的实验表明,在不需要渲染页面上的特征或昂贵的手工特征的情况下,平均比以前的技术状态高出近3.7的F1点。
网址:
