【论文导读】2022年论文导读第十期


论文导读
2022年论文导读第十期(总第五十期)
目 录
|
1 |
Bridging the Gap between Low-Light Scenes: Bilevel Learning for Fast Adaptation |
|
2 |
View-Wise Versus Cluster-Wise Weight: Which Is Better for Multi-View Clustering? |
|
3 |
High-resolution Depth Maps Imaging via Attention-based Hierarchical Multi-modal Fusion. |
|
4 |
Build Your Own Bundle- A Neural Combinatorial Optimization Method |
|
5 |
Unsupervised Image Deraining: Optimization Model Driven Deep CNN |
|
6 |
Loss Re-Scaling VQA: Revisiting the Language Prior Problem From a Class-Imbalance View |
01
Bridging the Gap between Low-Light Scenes: Bilevel Learning for Fast Adaptation
作者:金典,马龙,刘日升,樊鑫
单位:大连理工大学
邮箱:
jindianjx@gmail.com;
malone94319@gmail.com;
rsliu@dlut.edu.cn;
xin.fan@dlut.edu.cn
论文:
https://dl.acm.org/doi/abs/10.1145/3474085.3475404
1. 引言
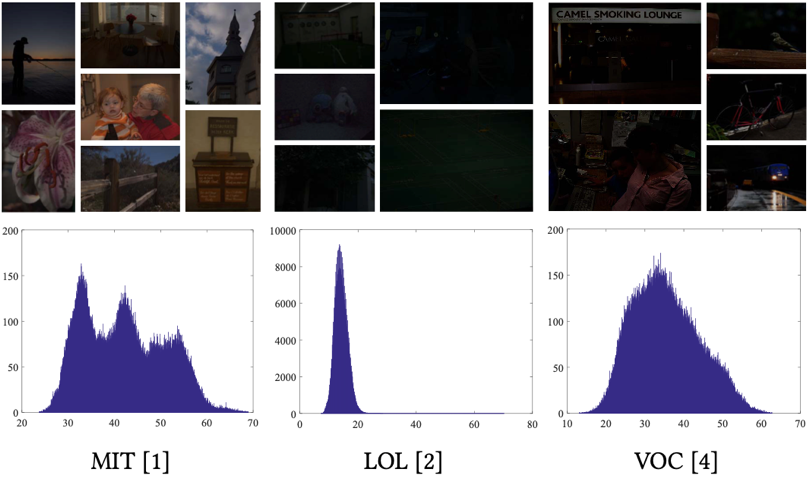
在多媒体社区中,低光图像增强是一项具有挑战性且受到广泛关注的任务。现有的工作大多是通过学习特定场景的数据分布来获得增强模型的。但是,这些方法在增强以前从未遇到过的真实场景时,适应性很差。为了解决这一问题,本文设计了一种新颖的双层优化方案来获得快速适应的能力,以弥合低光场景之间的差异。
2. 方法概述
本文构建了基于Retinex的具有自适应去噪机制的网络结构,旨在能够适用于更多实际场景。与现有的使用大量数据直接学习模型参数的工作不同,本文从一个新的超参数优化视角,可以针对一般的低光场景制定双层优化方案。该方案描绘了不同数据分布之间的潜在对应关系(即场景无关编码器)和各个数据的特征(即特定场景的解码器),以实现对一般低光场景的快速适应。由于内部优化需要大量的计算成本,可能无法精确估计超参数梯度,因此,本文引入单步近似和有限差分设计了近似超参数梯度方法。
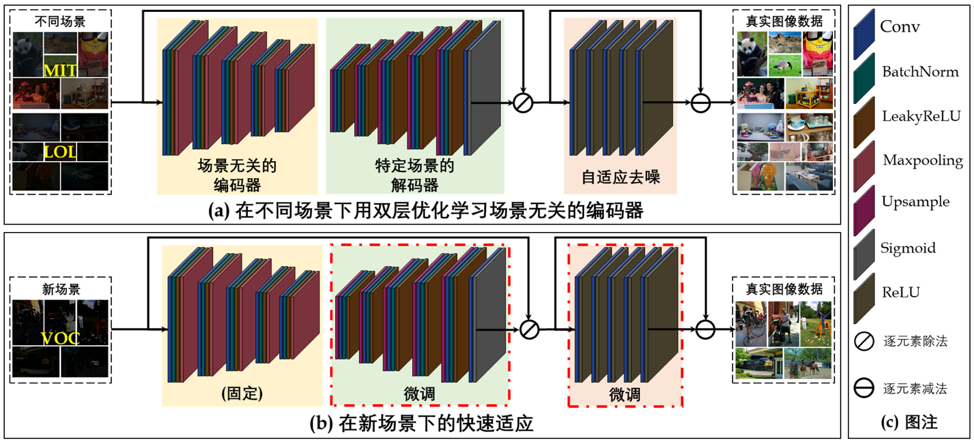
3. 实验结果
本文的方法和众多前沿算法之间进行了一系列比较。显然,在这些方法中,本文提出的算法表现出色,在曝光度、颜色和图像清晰度方面都是所有比较方法当中最好的。第一组和第二组图像显示了本方法避免过曝的能力。第三和第四组样例中,本方法生成的图像在色彩上比其他的方法生成的图像更加饱满,并且光照也更加准确。


02
View-Wise Versus Cluster-Wise Weight: Which Is Better for Multi-View Clustering?
作者:胡世哲,娄铮铮,叶阳东*
单位:郑州大学
邮箱:
ieshizhehu@zzu.edu.cn
zzlou@zzu.edu.cn
ieydye@zzu.edu.cn
论文:
https://ieeexplore.ieee.org/document/9623366
*通讯作者
加权多视角聚类方法旨在通过加权的方式整合多视角数据(例如具有不同类型特征的图像数据)的互补信息,以获得一致的聚类结果。然而,当跨视角的簇权重差异很大时,大多现有加权多视角聚类方法因多是基于视角权重学习,如图1(a)所示,无法学习细粒度的簇权重,导致难以充分利用视角互补信息。此外,大多现有加权多视角聚类算法都需要额外的参数来控制权重分布的稀疏性或平滑度,如果没有相关先验知识,这些参数将很难调整。
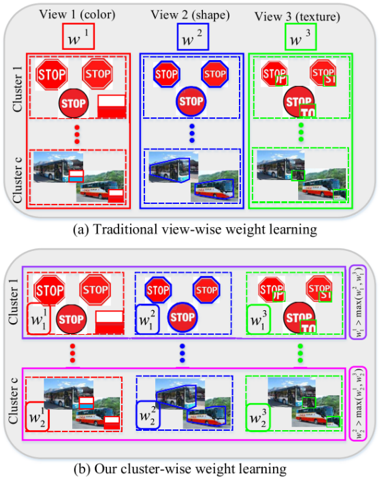
图1 (a) 传统的视角权重学习方式; (b) 所提出的簇权重学习方法
为了解决以上问题,我们提出了一种新颖有效的簇加权多视角信息瓶颈 (Cluster-weighted Multi-view Information Bottleneck) 聚类算法,该算法可以自动学习簇权重以发现多个视角中高鉴别性的簇,如图1(b)所示,利用更为精细化的簇层次互补信息提高整体聚类性能。为了学习簇权重,我们通过挖掘特定簇(包含一组数据样本)联合概率分布的互信息与该簇权重之间的关系来设计一种新的簇权重学习方案。与现有加权多视角聚类算法相比,所提算法不仅能够有效地处理含有复杂多样簇的多视角数据集,而且不需要任何参数来控制权重分布的平滑度或稀疏度。最后,提出了一种抽取-合并的方法来解决优化问题,如图2所示。
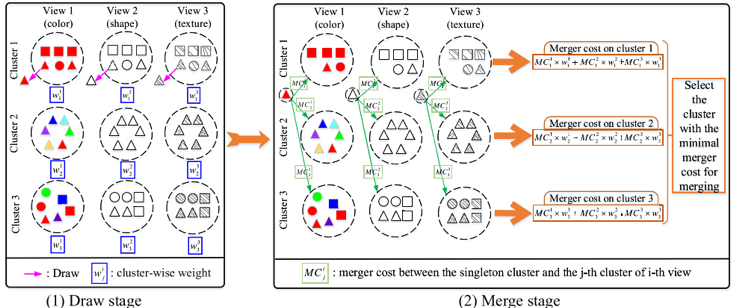
图2 抽取-合并优化方法
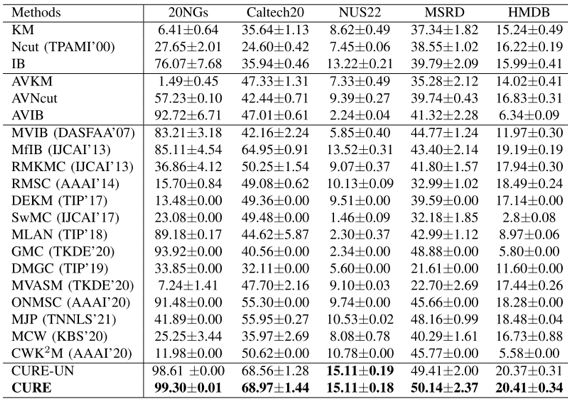
我们使用了多视角文档、图像和视频等五个丰富多样的数据集,与单视角聚类、全视角聚类、现有先进的多视角聚类算法进行对比,如表1和表2所示,实验结果表明了所提簇加权多视角信息瓶颈算法的有效性。
表1 在各个数据集上对比算法和所提算法的准确率ACC结果
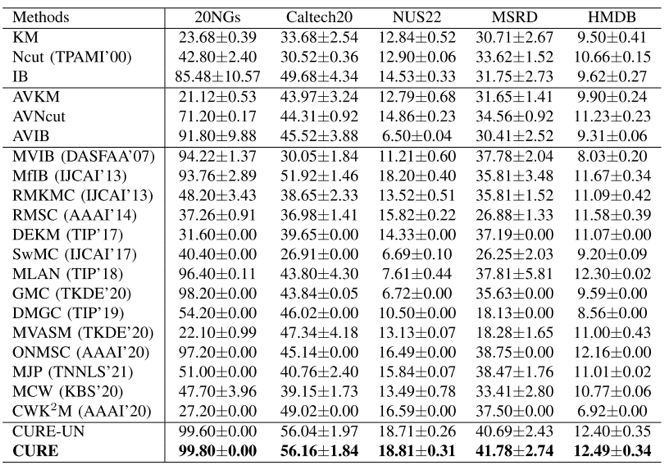
表2 在各个数据集上对比算法和所提算法的标准化互信息NMI结果
03
High-resolution Depth Maps Imaging via Attention-based Hierarchical Multi-modal Fusion
作者:仲志伟1,2,刘贤明1,2*,江俊君1,2,赵德斌1,2,陈志文3,季向阳4
单位:1哈尔滨工业大学,2鹏城实验室,3淘宝,4清华大学
邮箱:
zhwzhong@hit.edu.cn
csxm@hit.edu.cn
jiangjunjun@hit.edu.cn,
zhiwen.czw@alibaba-inc.com,
xyji@tsinghua.edu.cn
论文:
https://doi.org/10.1109/TIP.2021.3131041
*通讯作者
近年来,随着深度传感器的发展,深度信息得到了广泛的应用。然而,由于传感器性能的限制,很难得到高分辨率、高质量的深度图。一方面,超分辨率算法可以突破硬件成本的限制从软件层面提高图像的分辨率,另一方面,现有的RGB相机可以拍摄到高质量的彩色图像,因此彩色图像引导的深度图超分辨算法得到了越来越多研究者的关注。
目前大多数引导的深度图超分辨算法都是基于彩色图像和深度图结构一致性这一假设来设计算法的,然而,相比于深度图,彩色图像会包含更多的纹理信息,不加判别的融合彩色图像和深度图像将会导致问题过度迁移和边缘模糊等问题。
为了解决上述问题,本文提出了一个新的网络结构,如图1所示。首先,为了解决彩色图像纹理错误迁移的问题,我们提出了一个基于多模态注意力的特征融合模块(MMAF),如图 2所示,他可以自适应的选择彩色图像中利于重建的结构信息,并且过滤掉纹理细节等无用的信息。其次,我们观察到,网络的浅层结构提取到的都是一些细粒度的纹理特征,而深层次的结构提取到的都是一些粗粒度的语义结构,他们是互补的。为了进一步增强融合后的多模态特征,我们提出了一个双向特征增强模块,如图3所示,他的核心结构是一个双向GRU单元,因此可以保证每一层的特征都可以被其他层的特征增强 (不同层特征可以看做是长短期记忆)。最后,为了降低网络的计算量,我们在网络的输入部分将彩色图像下采样到和深度图相等的大小,然后对下采样后的彩色图提取特征(现有大多数方法是首先把深度图上采样到和彩色图像大小一致,然后提取特征,这样网络的所有操作都在高分辨率特征上进行,大大的提高了网络的开销)。
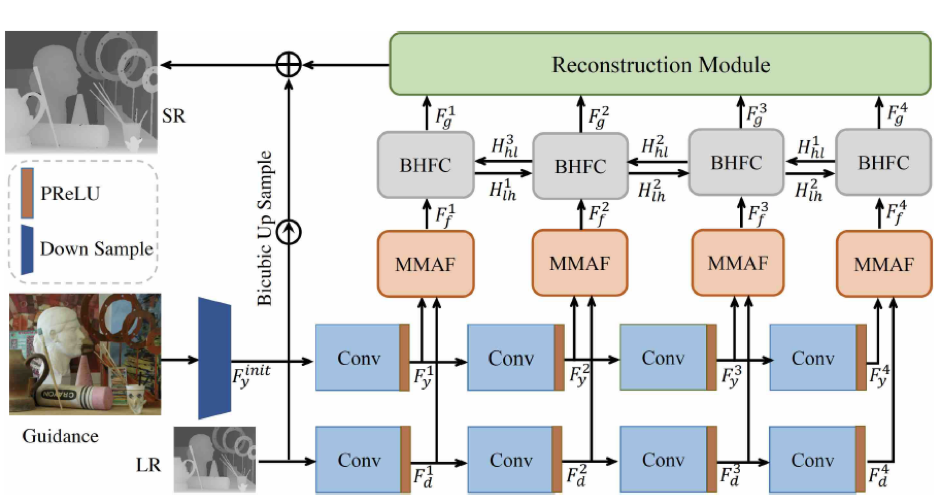
图1 网络框架图
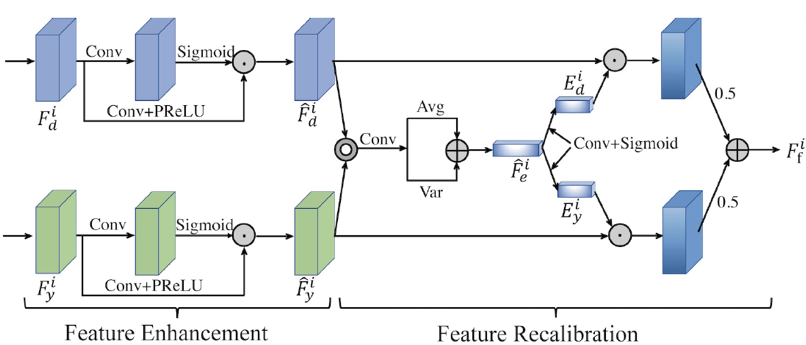
图2 基于多模态注意力的特征融合模块 (MMAF)
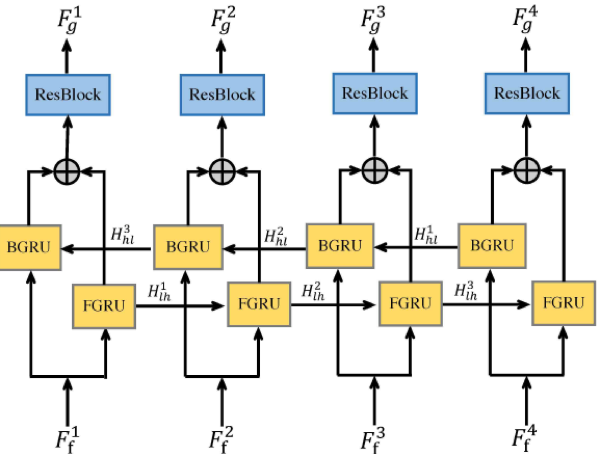
图3 双向特征增强模块(BHFC)
本文的方法在Middlebury, NYU v2 和Lu 三个基准数据及上进行了实验验证,表1和表2展示了本文提出的方法与一些近期深度图超分辨方法的对比。可以看出我们的方法在所有数据集上都取得了较好的结果。图4是主观效果对比,可以看出我们的方法可以更好地恢复深度图的边缘细节。
表1 Middlebury 数据集上MAE客观指标对比
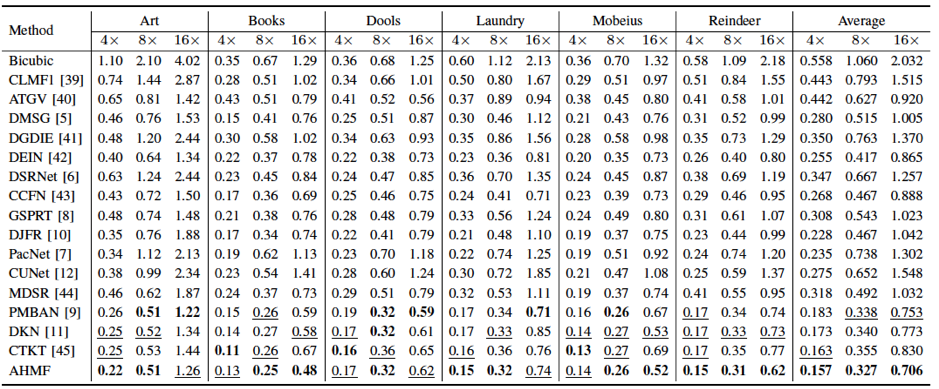
表2 RMSE度量指标对比
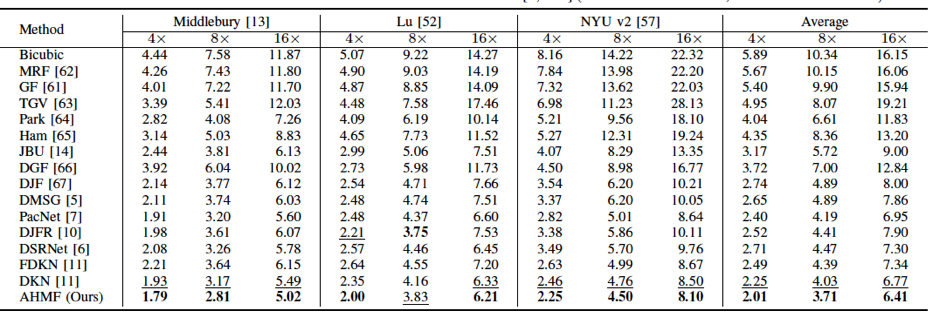
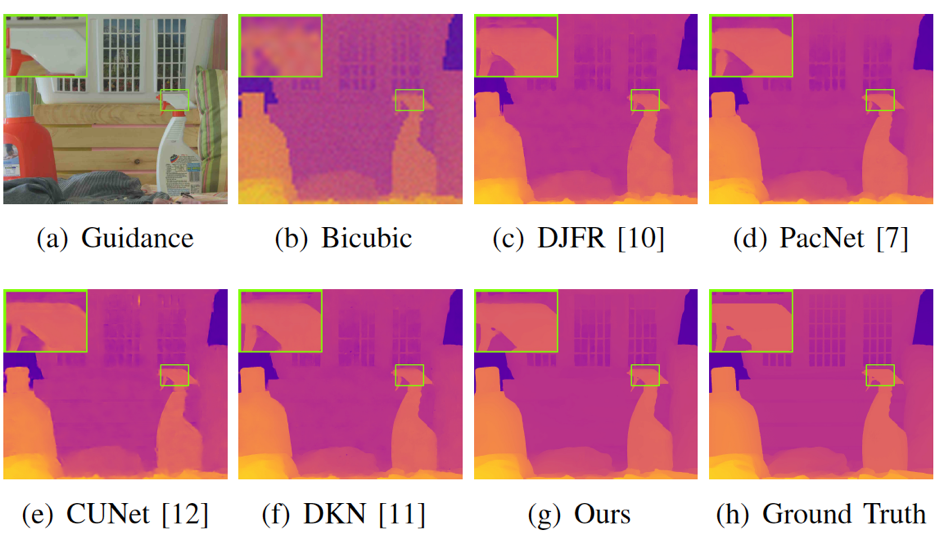
图4 不同算法重见效果可视化对比
04
Build Your Own Bundle- A Neural Combinatorial Optimization Method
作者:邓齐林、王凯、赵明浩、吴润泽、丁彧、邹哲讷、尚悦、陶建容、范长杰
单位:网易伏羲(https://fuxi.163.com)
邮箱:
wurunze1@corp.netease.com
论文:
https://dl.acm.org/doi/pdf/10.1145/3474085.3475440
代码:
https://github.com/fuxiAIlab/BYOB
引言:
在商业领域,搭配销售是进行产品促销的最重要的营销策略之一,在线电子商务和线下零售商普遍采用,比如,淘宝商城(Taobao)的服装搭配,缤趣网站(Pinterest)的图片集,或者游戏里的道具礼包。与单个物品销售不同,搭配销售的物品通常会有一定折扣,而且需要同时被购买。现有的推荐系统主要研究用户对于单个物品的偏好,然而如何建模用户对物品组合的偏好,为用户生成合适的搭配物品组合,学术界的研究相对较少。同时,与搭配推荐(bundle recommendation)不同的是,搭配生成(bundle composition)是为用户个性化地生成搭配组合,而不仅仅是推荐已经存在的搭配组合。
方法:
我们把搭配生成任务建模为如下的背包问题,即在背包内物品数量一定的情况下,最大化所有用户背包内物品组合的平均奖励:
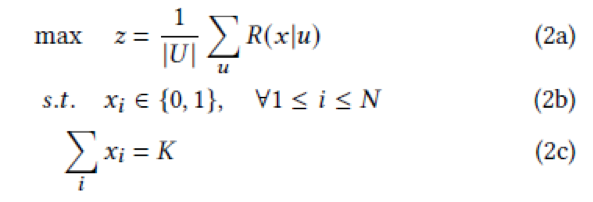
这里的奖励根据具体的需求可以有多种定义方式,比如预估的点击/转化率,或者其他特定的商业目标。由于用户背包的奖励是非线性函数,我们可以使用强化学习求解上述组合优化问题。我们进一步地将搭配生成建模为如下的马尔可夫决策过程(MDP),其中:
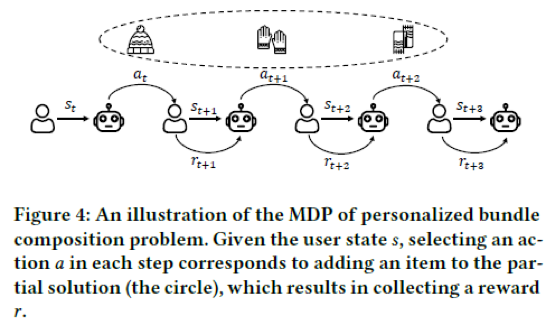
状态S。状态由两部分组成,其中一部分是用户特征以及物品相似图,另一部分是当前已为用户生成的物品。
动作A。动作就是从当前候选池里选择一个新物品。
状态转移P。对于该问题,状态之间的转移是确定的,即选择一个新物品后,用户背包内的物品也随之更新。
奖励R。奖励由环境模型给出,分为两部分组成,一部分是物品级别的奖励,另一部分是背包级别的奖励。其中,物品级别的奖励由用户对于单个物品的偏好得分以及物品与物品之间的相容度得分构成,背包级别的奖励是背包构造完毕后的评价值。
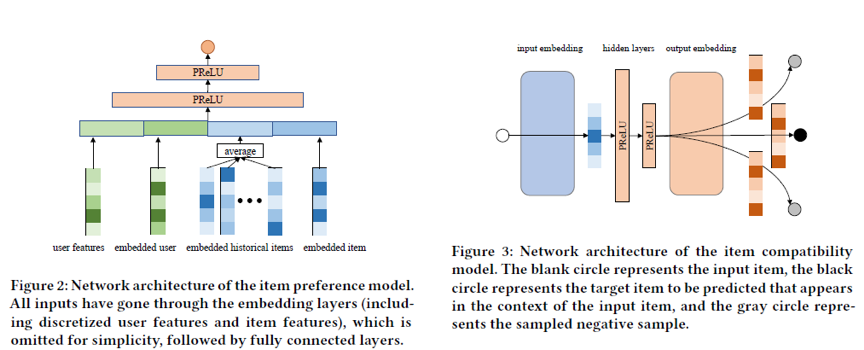
对于环境模型给出的物品级奖励,我们使用下图所示的Deep&Wide方案学习用户对于单个物品的偏好,同时使用Skip-Gram方案预训练物品的嵌入向量,获得物品相似图,从而计算物品之间的相容度。对于背包级奖励,我们可以使用一些搭配推荐模型的模型学出用户对于背包的偏好,但是由于背包物品的组合爆炸问题,很难学好,所以我们尝试直接使用背包的评价指标作为代理奖励。
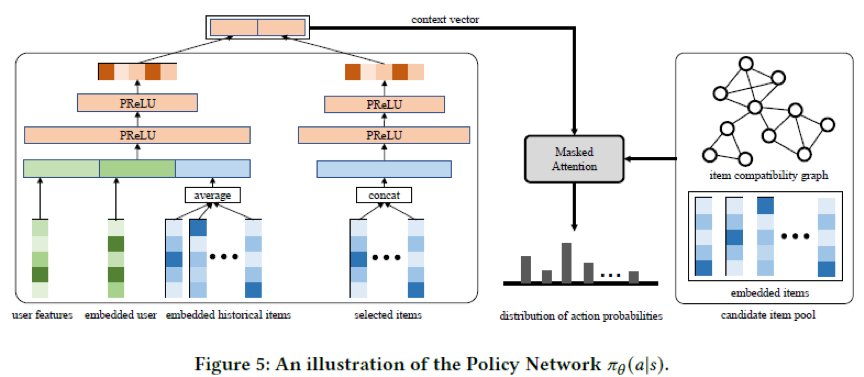
整个策略网络的架构图如下,左侧部分的双塔结构表示用户的状态向量,由用户特征以及当前用户背包内的物品组成。右侧部分由指针网络构成,输入为物品的预训练向量以及用户状态向量,输出物品候选池的采样概率。整个策略网络使用Proximal Policy Optimization(PPO)算法优化,同时我们尝试使用课程学习的思想,将物品级生成任务的知识迁移到背包级生成的任务中,具体而言,我们首先使用物品级奖励进行初步学习,然后使用背包级奖励进一步微调个性化背包的生成策略。
实验:
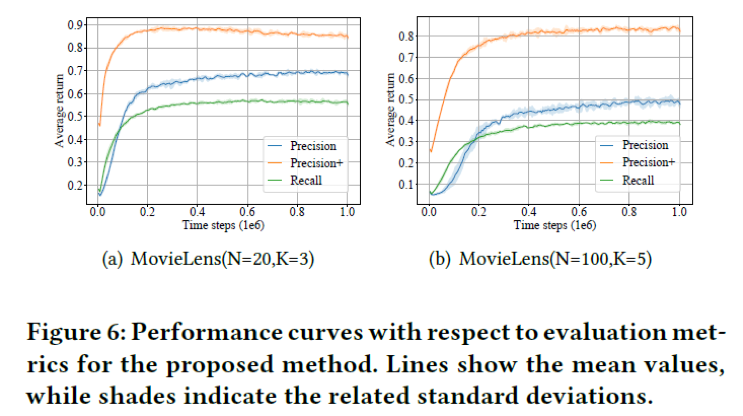
我们在两个工业级的公开数据上验证我们的方案,与传统物品推荐的评价指标不同,我们使用衡量物品组合优劣的评价指标。如下图所示,在物品组合数较小时(图a),算法的收敛速度较块,但是物品组合数较大时(图b),算法的收敛速度变慢,表明
搭配生成任务面临组合爆炸的问题。
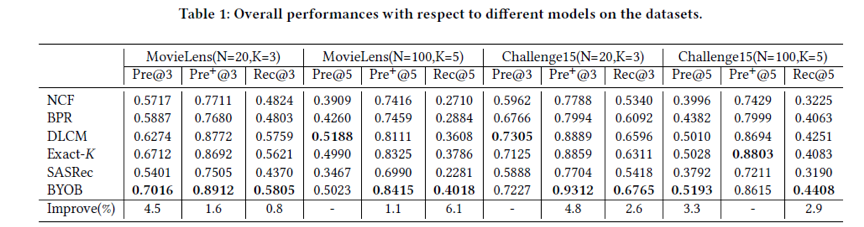
接着,我们对比了一些最新的基线方案,包括点级排序方案NCF,点对级排序方案BPR,列表级排序方案DLCM,以及序列推荐方案SASRec等。如下表所示,我们的方案显著地超过了上述基线方案,同时我们也可以看出列表排序方案比点以及点对排序方案效果更优。
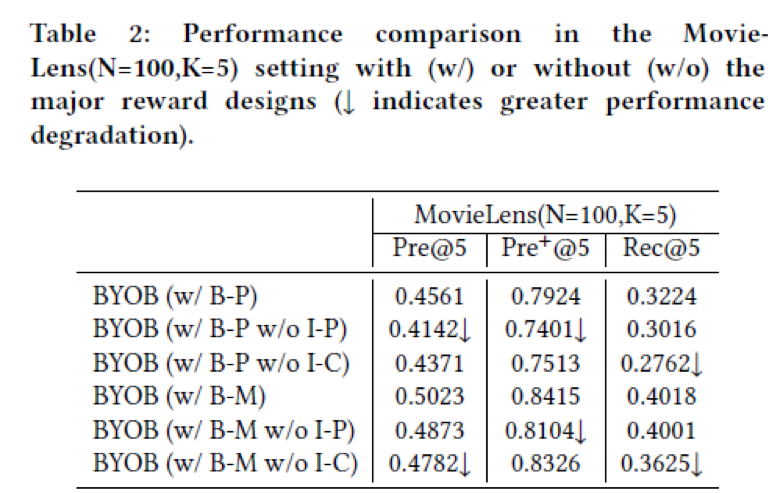
最后我们做了一些消融实验验证我们算法构成部分的有效性。实验结果表明,物品级偏好(I-P)以及物品相似度(I-C)都有利于提升模型的最终效果。同时,直接使用评价指标(B-M)作为背包级的代理奖励,效果要好于使用环境模型学出的礼包偏好奖励(B-P)。
05
Unsupervised Image Deraining: Optimization Model Driven Deep CNN
作者:喻长峰1^, 昌毅2^, 李祎1, 赵熙乐3, 颜露新1*
单位:1华中科技大学;2鹏城实验室;3电子科技大学
邮箱:
ycf@hust.edu.com;
owuchangyuo@gmail.com;
li_yi@hust.edu.cn;
xlzhao122003@163.com;
yanluxin@hust.edu.cn
论文:
https://dl.acm.org/doi/10.1145/3474085.3475441
代码:
https://github.com/ChangfengYu-Hust/UDGNet
*通讯作者
1. 引言
现阶段图像去雨工作主要分为两大类:基于模型驱动的优化方法和基于数据驱动的学习方法,如图1所示。前者核心思路在于挖掘领域知识手工设计先验知识,构建能量优化函数并通过最优化算法迭代求解,从而实现图像和雨条层的分离。此类方法无需成构造成对的训练样本数据,广泛适用于任意场景泛化性较好。然而,由于实际场景雨条复杂多样,手工设计先验表达能力不足以精确建模复杂雨条,因此去雨效果受限。后者主要利用神经网络强大的特征表达能力,通过从大样本数据中学习图像与雨条之间的判别性特征,进而将两者分离。学习方法在仿真数据集上取得了很好的效果,然而由于仿真数据与实测数据之间的差异,导致仿真数据训练的模型在实际场景泛化性能较差。鉴于模型驱动优化方法与数据驱动学习方法优缺点互补,本文核心动机在于取长补短,提出统一的无监督学习实测雨条去除框架,兼具模型泛化性好与网络表征能力强的优点。
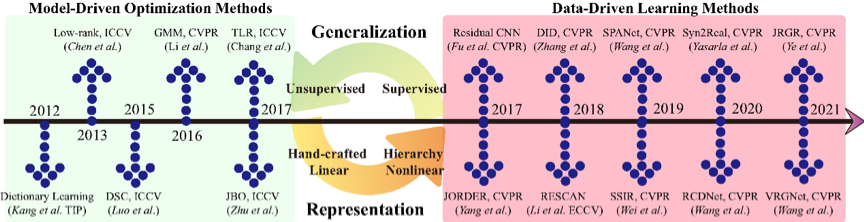
图1 模型驱动与数据驱动去雨方法发展脉络与关系
2. 方法概述
我们首先挖掘雨条层方向性和图像层平滑性的特性知识,且统计分布上前者各项同性后者各向异性,上述语义知识为二者有效区分提供了基础。我们提出方向性变分分解模型数学化表达建模,通过ADMM迭代优化求解。进而,我们将变分分解优化模型深度网络化,从网络结构和损失函数上模拟优化方法。网络结构包括学习角度估计子网络、雨条层估计子网络、图像估计子网络,分别模拟优化迭代过程中角度、雨层、图像层三个变量估计子问题,且在相应的子网络处施加对应的损失函数,具体无监督网络结构框架如图2所示,其具有可控、可解释、处理速度快等优点。
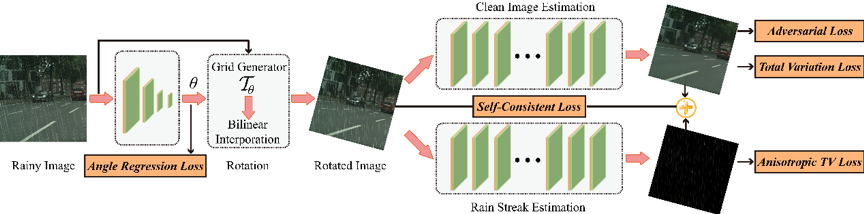
图2 优化启发去雨网络模型框架
3. 实验结果
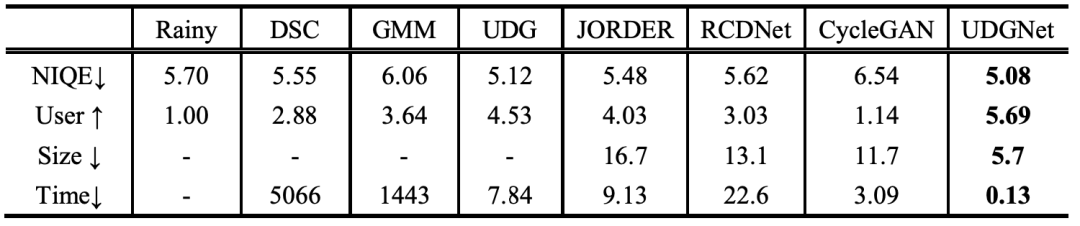
如图3所示,本文提出方法UDGNet对实测数据雨条抑制更加干净且图像结构清晰。表1展示无参考客观评价指标与打分结果,均表明本文方法在实测结果上均优于对比方法,且通过引入先验知识可有效减小模型尺寸,降低处理时间。对于1024*2048大小图像,仅需0.13s易于移动端部署。

图3 实测雨图去除可视化对比结果
表1 无参考质量、用户打分、模型大小(MB)、处理时间(s)指标对比
06
Loss Re-Scaling VQA: Revisiting the Language Prior Problem From a Class-Imbalance View
作者:郭洋洋1,聂礼强1*,程志勇2,田奇3,张民4
单位:1山东大学,2齐鲁工业大学(山东省科学院),3华为云,4哈尔滨工业大学(深圳)
邮箱:
guoyang.eric@gmail.com;
nieliqiang@gmail.com
论文:
https://ieeexplore.ieee.org/document/9629356
代码:
https://github.com/guoyang9/class-imbalance-VQA
引言:视觉问答旨在为关于给定图片的文本问题返回一个正确答案。诸多研究表明,当前视觉问答模型受制于语言先验问题,即模型仅根据问题与答案之间的简单匹配关系进行作答,而忽略了文本-图像的多模态推理过程。本文拟探索视觉问答中语言先验问题与传统类别不平衡问题之间的联系,并从以下两方面做出贡献。第一,分析导致语言先验问题的内因。本文提出从类别不平衡的角度重新审视该问题,并提出一种新观点对该问题进行解释。第二,本文提出了一种损失重放缩方法,其核心是根据相应的问题类型,为每个答案分配不同权重来重新计算损失值。
问题分析:本文指出,对于训练数据集中的统计样本而言,难错样本损失值相对较大,易错样本损失值较小。为验证该观点,本文利用混淆矩阵来分析模型预测结果。如图 1所示,对于How Many问题来说,从稀疏答案(即50、100)错误预测为稠密答案2所产生的损失值最高,这表示模型对此类难错样本的惩罚力度很大。另一方面,易错样本的损失值往往较小,表明该类样本几近被模型优化策略忽视。
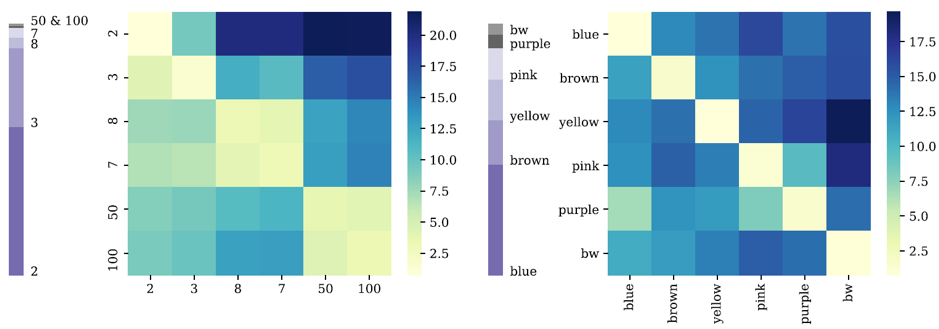
图 1 两种问题类型下的答案分布及对应损失函数。左:How Many;右:What Color
方法概述:如图 2所示,在计算损失函数时,本文为每个答案类引入一个固定权重,可以既防止难错样本对参数进行过度更新,又引导易错样本对模型参数进行有效学习。具体来说,权重ui由下式得到,
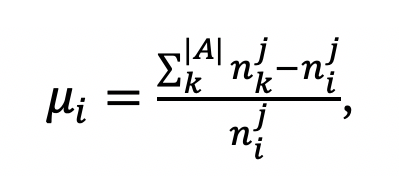
其中,nij表示问题类型qtj下的答案ai的数量(对于其它不在当前问题类型答案集中的样本,ui置为1)。其次,本文发现当损失值过大时,参数更新过程波动较大,因此借助平滑函数,将过大数值截断为100,使训练更加稳定,
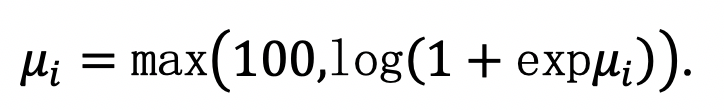
在测试阶段,损失重放缩模块不发挥作用,仅保留基线模型。这保证了本文方法与基线模型相比,在测试时未引入任何时间增量。
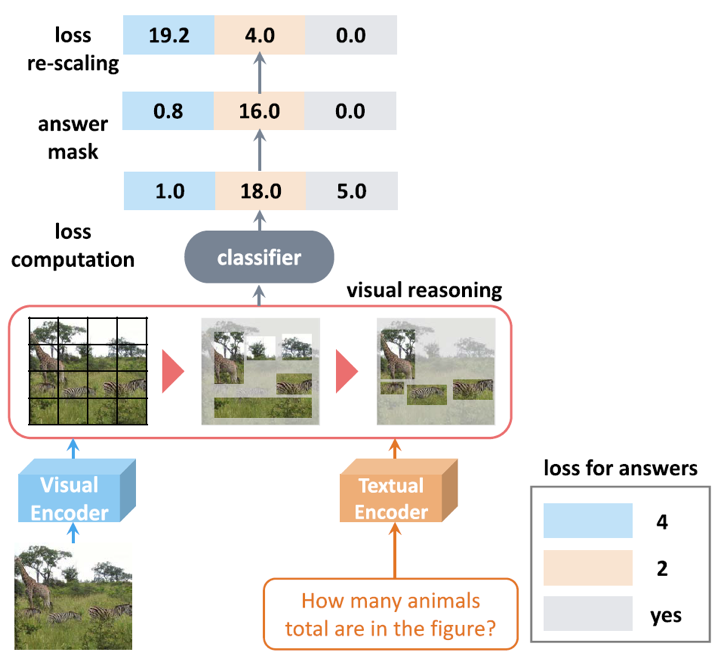
图 2 方法流程简图及损失值计算
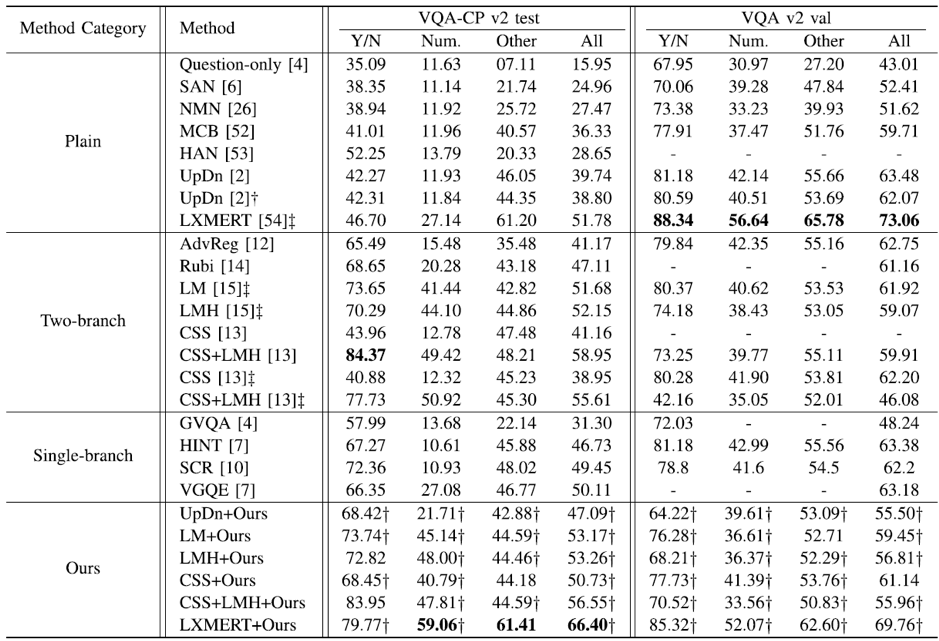
实验结果:本文在多个基准数据集上进行了实验,如表 1所示,将本文方法应用于6个基准方法上时,均可以取得显著性能提升,代码已开源。
表 1 基准数据集方法性能比较

编辑人:桑基韬、聂礼强
专委会责任副主任:徐常胜