【论文导读】2022年论文导读第十一期


论文导读
2022年论文导读第十一期(总第五十一期)
目 录
|
1 |
Sub-Region Localized Hashing for Fine-Grained Image Retrieval |
|
2 |
Applications of knowledge graphs for the food science and industry |
|
3 |
Better Than Reference in Low-Light Image Enhancement: Conditional Re-Enhancement Network |
|
4 |
Spatio-Temporal Correlation Guided Geometric Partitioning for Versatile Video Coding |
|
5 |
M5L: Multi-Modal Multi-Margin Metric Learning for RGBT Tracking |
|
6 |
Big-Hypergraph Factorization Neural Network for Survival Prediction from Whole Slide Image |
01
Sub-Region Localized Hashing for Fine-Grained Image Retrieval
作者:项欣光,张亚杰,金露,李泽超,唐金辉
单位:南京理工大学
邮箱:
xgxiang@njust.edu.cn,
yajiezhang@njust.edu.cn,
lu.jin@njust.edu.cn,
zechao.li@njust.edu.cn,
jinhuitang@njust.edu.cn
论文:
https://ieeexplore.ieee.org/abstract/document/9638382
代码:
https://github.com/ZhangYajie-NJUST/sRLH.git
哈希由于在存储和计算等方面展示的高效性,被广泛地用于大规模的图像检索。大多数的哈希方法用于解决粗粒度图像的检索问题,这些图像具有较大的视觉差异,如图1(a)所示。不同地,细粒度图像是属于同一个大类,不同类别视觉高度相似,而同类别的局部特征又存在较大的差异,因此具有类间差异小、类内差异大的属性,如图1(b)所示。

图1 (a)粗粒度图像。不同类别的图像存在较大的视觉差异。(b)细粒度图像。同一行的图像属于同一类别,具有较大的类内差异,而同一列的图像又具有较小的类间差异。
实际上,这些不同类别的细粒度图像存在显著的局部细节差异。例如,图1(b)中的第二列的鸟的目标区域乍一看是相似的,然而,可以观察到,每种鸟类都有相当不同的局部特征,如喙、脚和腹部,这些不同的局部细节信息包含了有利于检索的必要信息。因此,在基于哈希的细粒度图像检索任务中有必要探索细粒度图像的这些多样化的局部细节。此外,类似的子类会导致较小的类间变化,如图1(b)每列中的图像。然而,不同姿态和视点下的物体会引起巨大的类内变化,如图1(b)每一行中的图像。考虑到细粒度图像的这种类间差异小、类内差异大的性质,学习类间可分离和类内紧凑的哈希码对于细粒度图像检索是至关重要的。
为此,本文提出了一种基于局部区域定位的细粒度哈希模型(简称为sRLH)通过捕获细粒度图像的多样化的局部信息来学习类间分离但类内紧凑的哈希码。该方法的流程图如图2所示,包括局部-全局关联表示学习和哈希码学习这两个模块。具体来说,局部-全局关联表示学习旨在同时学习全局特征和局部特征以进行哈希学习。为了区分细粒度图像之间的细微差异,本方法提出局部区域定位模块,通过定位不同区域来学习局部特征,从而揭示细粒度图像中细微的局部差异,捕获多样化的局部信息。为了定位不同的局部区域,网格特征图被均匀地划分为不重叠的块以生成可以估计图像中不同显着区域的峰值。此外,利用三元组损失,通过保留类内相似性和类间差异来学习局部特征。利用交叉熵损失来学习具有语义判别性的全局特征。通过对网格特征做全局平均池化得到图像表示来进行哈希学习。为了降低大的类内差异,该方法引入中心损失以强制同一类的哈希码接近它的哈希中心,哈希中心通过对每类样本的哈希码取均值得到。此外,为了增加类间变化,本方法利用 gram-schmidt 正交化使哈希中心足够分离,进而学到类间分离但类内紧凑的哈希码。
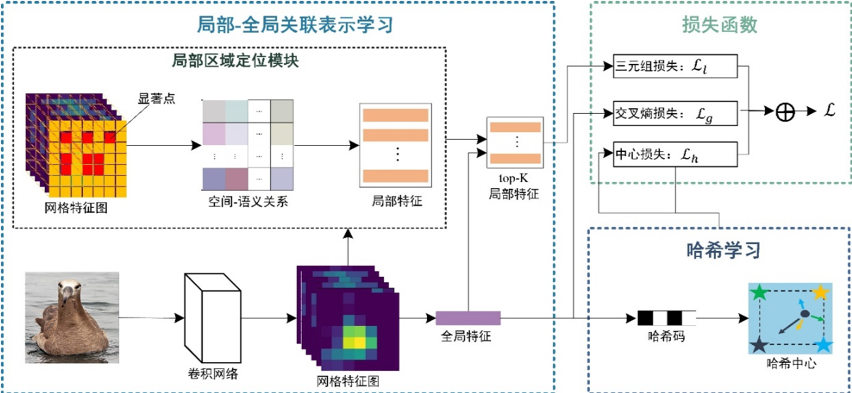
图2 sRLH方法的流程图
表1展示了所提方法和基准方法在四个细粒度数据集上的mAP结果。可以看到所提出的sRLH方法在四个数据集上均优于所有的对比方法。图3展示了top-10的检索结果,同样sRLH方法取得了优异表现。
表1 sRLH和对比方法在所有数据集上的 MAP (%) 结果
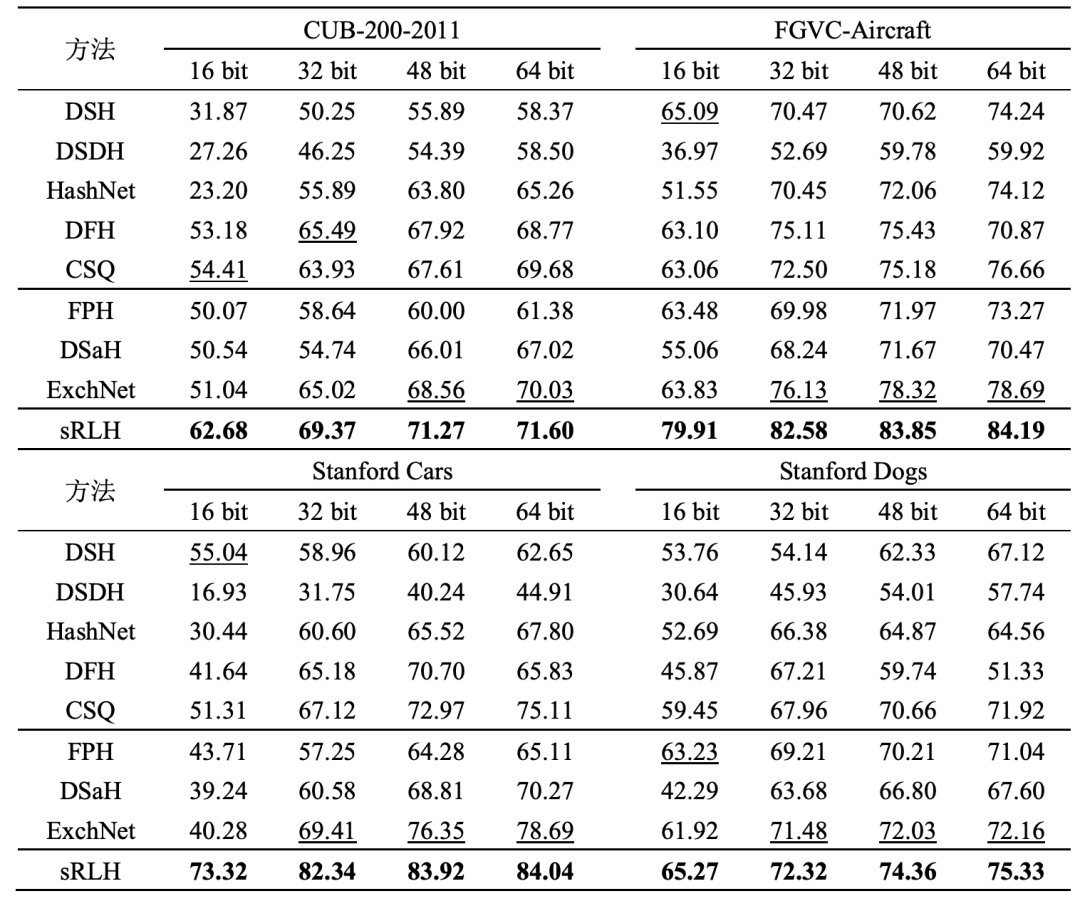

图3 两个细粒度对比方法(FPH和DSaH)和所提的sRLH方法在 CUB-200-2011 和Stanford Dogs数据集上返回的前 10 个检索示例。绿色框表示正确的检索结果,红色框表示错误的检索结果。

02
Applications of knowledge graphs for the food science and industry
作者:闵巍庆1,2,刘春霖1,2,徐乐怡3,蒋树强1,2,*
单位:1中国科学院计算技术研究所,2中国科学院大学,3苏州大学
邮箱:
minweiqing@ict.ac.cn;
liuchunlin20g@ict.ac.cn;
leahhhxu@gmail.com;
sqjiang@ict.ac.cn
论文:
https://www.sciencedirect.com/science/article/pii/S2666389922000691
*通讯作者
如今,各种网络(如物联网和移动网络)、数据库(如营养表和食品成分数据库)和社交媒体(如Instagram和Twitter)的快速发展产生了海量食品数据,这为研究人员通过数据驱动的计算方法研究食品科学和工业中的各种问题提供了前所未有的机遇。然而,这些多源异构的食品数据呈现信息孤岛特点,导致这些食品数据难以充分利用。知识图谱以结构化的形式提供了统一和标准化的概念体系,可以有效组织这些食品数据以便开展各种应用。本文简要介绍了知识图谱,以及食品知识组织形式从食物本体到食物知识图谱的演变。然后,本文详细介绍了食品知识图谱的代表性应用,最后讨论了食品知识图谱的未来发展方向。
表1 现有食品本体总结
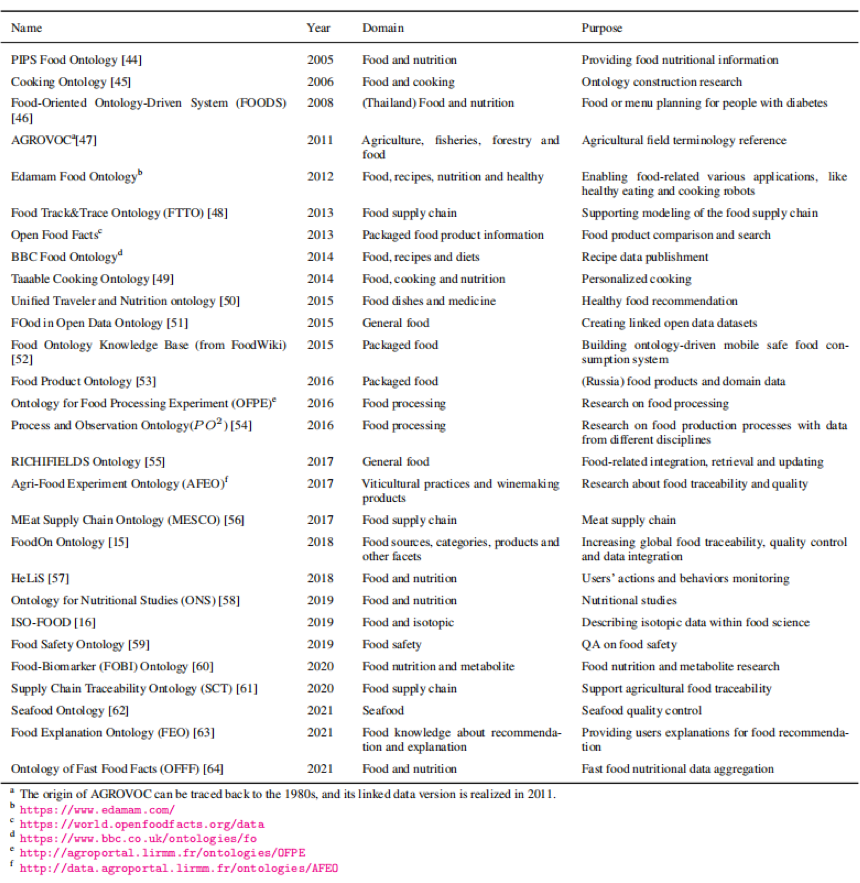
表2 现有食品知识图谱总结(“-”表示本体未知,“*”表示食品本体是专门为相应的食品知识图谱构建的)
食品知识图谱能够用于刻画不同领域实体之间的潜在关联。同为食品知识组织方法,食品本体在食品知识图谱的发展中也起到了非常重要的作用。食品本体使用食品类型、属性和关系的通用术语,能够解决跨食品领域的数据协调问题。食品本体可被分为烹饪和食谱本体,营养和健康本体等类型。食品知识图谱也可以划分为四种类型,食谱知识图谱,营养和健康知识图谱,食品安全知识图谱和一般食品知识图谱。表1、表2分别是现有食品本体和食品知识图谱的总结。
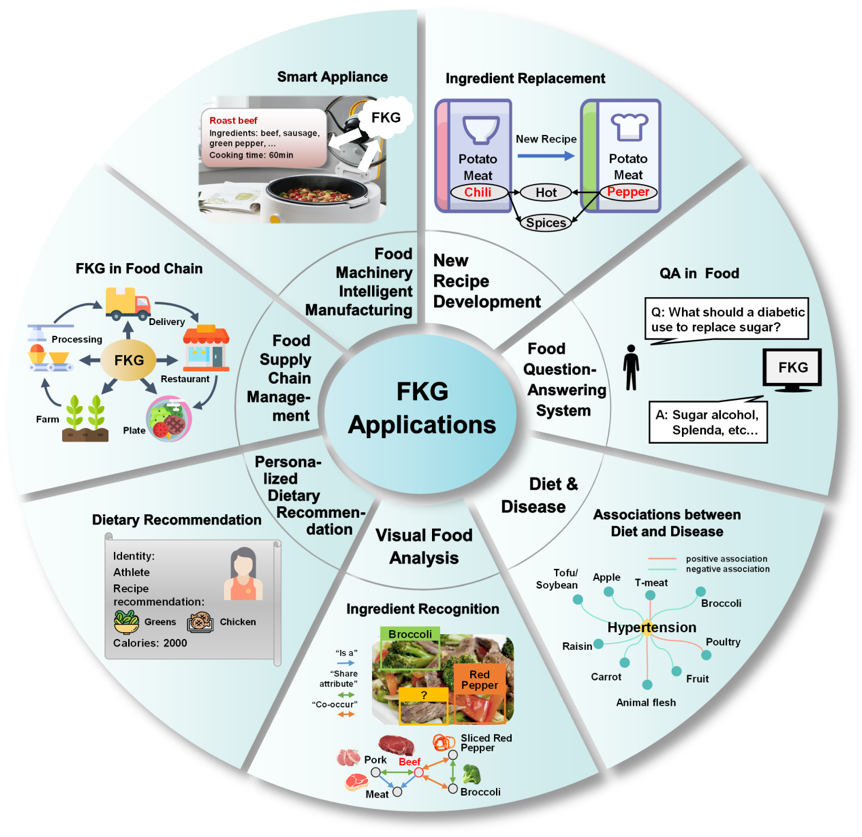
图1 食品知识图谱应用
图1从七个方面总结了食品知识图谱在食品科学和工业中的代表性应用,包括:(1)新食品研发,利用食品知识图谱的知识组织能力和推理能力开发基于现有产品的新式食品;(2)食品问答系统,食品知识图谱能够协助开发有关食谱和营养问题的问答系统,实现营养信息查询、营养成分比较和符合特定标准的食谱搜索;(3)饮食-疾病相关性研究,通过构建食品知识图谱,建立疾病、饮食、食物、原料和化学成分之间的联系,然后对其相关性进行深入分析;(4)视觉食品分析,一种食品无损分析方法是,通过机器学习算法将食品知识图谱中有关食材共存和食物-食材关系的知识转换为共生矩阵,进而辅助预测菜肴的类别,提高视觉食物识别性能;(5)个性化饮食推荐,使用食品知识图谱融合大量个人信息、营养和饮食数据,生成饮食建议或推荐;(6)食品供应链管理,在食品供应链管理中使用食品知识图谱对食品数据进行建模和融合;(7)食品装备智能制造,食品知识图谱能够对物联网传感器收集的数据进行融合和挖掘并用于进一步的智能决策,构建自动化食品工业生产线和面向消费者的智能终端设备。可以看出,食品知识图谱在挖掘不同食品间的特征与相似性上起到了多样的作用。
最后,本文阐明了食品知识图谱的关键挑战和未来研究方向,包括多模态食品知识图谱构建、基于食品知识图谱的推理、食品大数据组织与挖掘、食联网(IoF)开发、辅助人类健康监测和食品智能。食品知识图谱由于其在表示和推理方面的能力将推动食品互联网(Internet of Food)和食品智能的发展。从其未来的发展方向可以看出,食品知识图谱在解决食品工业和日常饮食情景中的关键问题上有着巨大潜力。尽管在多模态食品数据和复杂的计算技术上仍然存在挑战,不可否认的是,我们已经看到了食品知识图谱在食品领域的巨大应用前景,这将鼓励越来越多的学者将知识图谱应用于食品科学和工业领域。
更多食品计算相关的工作请访问如下网站:http://123.57.42.89/FoodComputing__Home.html
03
Better Than Reference in Low-Light Image Enhancement: Conditional Re-Enhancement Network
作者:张雨,遆晓光,张斌,季锐航,王春晖
单位:哈尔滨工业大学
邮箱:
zhangyuhit2@hit.edu.cn;
dixiaoguang@hit.edu.cn;
teamup@yeah.net;
jiruihang@hit.edu.cn;
wang2352@hit.edu.cn
论文:
https://ieeexplore.ieee.org/document/9656595
论文介绍:
https://zhuanlan.zhihu.com/p/439144010
1. 引言
低照度图像存在低对比度,低亮度,噪声,颜色退化等问题。在过去的研究中,研究人员提出了多种低照度图像增强方法,包括基于非学习的方法和基于学习的方法,并取得了很好的效果,但是这些方法大多无法很好地同时解决低照度图像存在的各类问题。在早期很多基于非学习的工作都致力于手动或者自动化的提高图像的对比度、亮度等,但是不能很好的解决增强过程中带来的噪声放大问题。近期基于深度学习的一些研究工作,在去噪和颜色恢复上取得了很好的效果,但是无法显式的调节图像的局部对比度和局部亮度等,进而使得增强结果不稳定。本文主要目的是提供一种可以同时解决低照度图像各类问题的增强框架。
2. 方法概述:
近期的很多方法都是基于简化的Retinex模型或者在HSV颜色空间下的,我们首先证明了这些方法的等价性,即它们都是保持单个像素点的{R,G,B}组成的3维向量的方向不变,仅改变HSV中V通道的值。因此将基于HSV或者Retinex模型的增强方法处理后的图像的V通道取出,就可以很好的表示增强操作,我们称之为Enhanced V channel。在此基础上,我们提出了重增强(Re-Enhancement)的概念,即以Enhanced V channel为输入条件,对低照度图像进行重新增强,在保留与Enhanced V channel一致的对比度和亮度基础上,实现噪声的去除和颜色校正。本文中,我们采用一个CNN网络(CRENet)来实现重增强,如下图所示。在训练中,可以以正常照度图像的V通道加噪声(图1左图中的红线),或者对低照度图像的V通道进行局部亮度映射(图1左图中的蓝线)得到训练用的enhanced V channel。
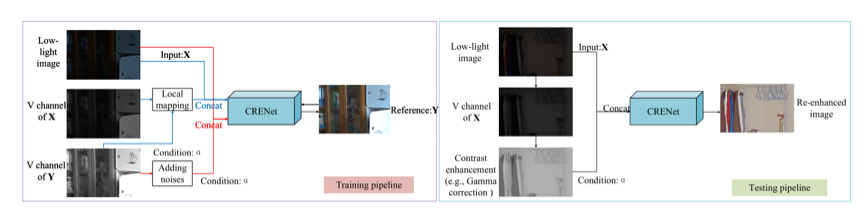
图1 训练和测试示意图。左:训练过程。右:测试过程。
3. 实验结果:
如表1所示,将现有的一些增强方法与我们提出的CRENet结合后,可以显著提高增强结果的SSIM和PSNR等指标,其提升也优于一些经典的去噪方法。图2显示了与CBM3D和DnCNN等去噪方法的视觉对比。可以看出,CRENet在实现去噪的同时,能够对图像颜色进行一定的恢复,使增强结果更加接近参考图像。
表1 与其它方法在LOL数据集上的定量比较。下标std表示标准的SSIM和PSNR;下标map表示对增强结果进行局部亮度映射后计算SSIM和PSNR。
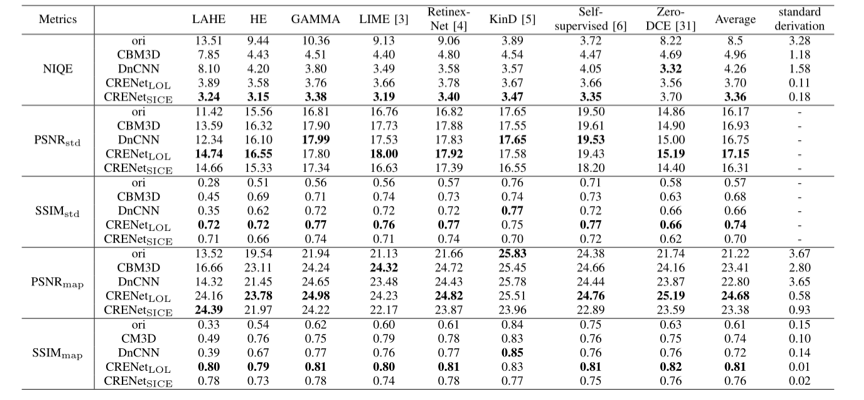

图2 在HSV和RGB颜色空间下,与CBM3D和DnCNN等去噪方法的比较。
04
Spatio-Temporal Correlation Guided Geometric Partitioning for Versatile Video Coding
作者:孟学苇1、贾川民1、张新峰2、王苫社1、马思伟1
单位:1北京大学、2中国科学院大学
邮箱:
xwmeng@pku.edu.cn
cmjia@pku.edu.cn
xfzhang@ucas.ac.cn
sswang@pku.edu.cn
swma@pku.edu.cn
论文:
https://ieeexplore.ieee.org/abstract/document/9619927/
1. 引言
编码单元划分决定了编码单元的尺寸和形状,是当前混合视频编码框架的核心技术。划分结果对于视频内容的刻画程度对压缩性能具有显著影响。现有的视频编码标准多采用矩形划分,然而其对于不规则运动物体边缘的表示能力不足,难以适应复杂的视频内容。而基于对象划分以及几何划分的非矩形划分方式,则受到了编码复杂度、编码信息表示代价的限制,难以实用。鉴于此,提出了一种时空域联合几何划分预测(Spatio-Temporal Correlation Guided Geometric Partitioning, STGEO),以有效地描述视频编码运动场中的运动信息。该方法一方面可以实现运动信息的高效建模,另一方面充分利用了像素及编码信息的时空相关性,对编码模式和运动信息进行预测,以节省编码信息表示所消耗的比特。
2. 方法概述
STGEO是一种编码单元(Coding Unit, CU)级的帧间预测方法,其将矩形CU划分为两个多边形子块,并对两个子块使用各自的运动矢量(Motion Vector, MV)进行运动补偿,以实现对于运动信息的高效捕捉。其中,CU的划分方式从预设的划分模式集合中进行选取,MV从已编码区域的MV中进行导出,我们使用已编码区域的MV组建MV候选列表,两个子块的MV从MV候选列表中选取。图1为STGEO的解码端框架图,其中虚线箭头代表编码信息的传递。STGEO主要包括运动矢量候选列表初始化,最可能划分模式预测,基于概率的运动矢量候选列表构建,以及运动补偿。首先,给定一个STGEO编码的CU,进行MV候选列表初始化的过程,即将空域或时域已编码块的MV按照特定的规则,放入MV候选列表中。然后,基于边缘信息、当前帧已编码CU的STGEO模式信息,预测最可能的STGEO模式,将STGEO模式集分为两个子集,即高概率子集 (High-Probability Subset, HPS)和低概率子集 (Low-Probability Subset, LPS)。如果当前CU选中高概率子集中的划分方式,则可以使用较少的比特表示划分模式索引。将这两个子集与解码得到的STGEO模式索引结合起来,可以导出ModeIdx。ModeIdx表示STGEO模式集中的划分模式索引,即划分方式。随后,使用ModeIdx和List1,结合离线训练的MV选中概率自适应地导出两个STGEO子块的MV候选列表。使用解码得到的MV索引,分别为两个子块导出MV0和MV1。最后,基于划分模式ModeIdx,以及MV0和MV1进行运动补偿。
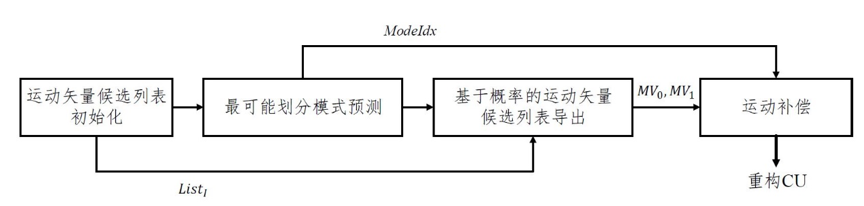
图1 时空域联合划分预测框架
3. 实验结果
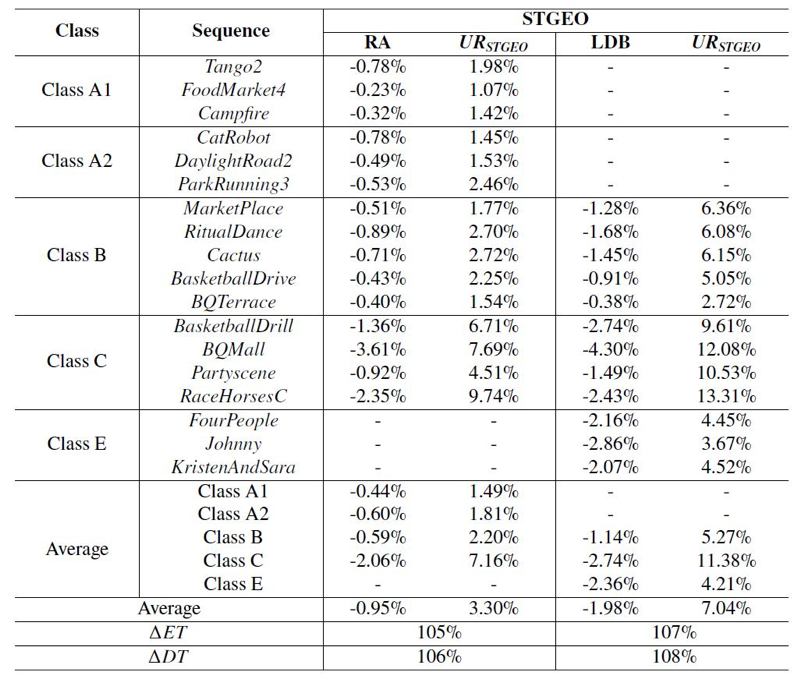
为了测试方法的有效性,我们将其实现在H.266/VVC (Versatile Video Coding) 参考软件VTM-8.0中,并且使用JVET中的通用测试序列进行测试。测试在随机访问 (Random Access, RA)和低延时 (Low Delay B, LDB)两种配置下完成,QP设置为{22, 27, 32, 37}。编码性能通过BD-rate进行衡量,BD-rate为负数代表性能增益。实验数据如表1所示,STGEO可以在RA和LDB配置下分别可以实现0.95%、1.98%的性能增益。其中,BQMall的性能增益最高,主要是由于这一序列包含清晰的运动物体边界。另外,STGEO的划分模式预测和运动矢量预测,对于Class E的序列具有较为明显的效果,主要原因在于Class E的序列是具有稳定运动和清晰边界的会议视频,其具有更可预测的编码模式。
表1 STGEO在VTM-8.0中的性能增益 (Anchor: VTM-8.0 with GEO off)
05
M5L: Multi-Modal Multi-Margin Metric Learning for RGBT Tracking
作者:涂铮铮,林春,赵伟,李成龙*,汤进
单位:安徽大学 计算机科学与技术学院 多模态认知计算安徽省重点实验室
邮箱:
zhengzhengahu@163.com;
lc20191001@163.com;
944258047@163.com;
lcl1314@foxmail.com;
tangjin@ahu.edu.cn;
论文:
https://doi.org/10.1109/TIP.2021.3125504
*通讯作者
1. 引言
可见光-热红外图像目标跟踪(RGBT跟踪)旨在利用可见光图像和热红外图像的互补信息来实现鲁棒的视觉跟踪,以完成在不同复杂背景下对目标进行精确定位的任务。在RGBT跟踪过程中,困难样本的分类是一个非常具有挑战性的问题。现有方法只注重扩大正样本和负样本之间的边界,而忽略了多层困难样本之间的关系,这对困难样本分类的稳健性至关重要。本工作基于深度度量学习,提出了一种新的深度度量学习框架,利用困难样本的结构信息来提高RGBT跟踪中困难样本分类的鲁棒性。其主要贡献如下:(1)提出了一种多模态多边界结构损失(multi-modal multi-margin structural loss)用以度量可见光模态和热红外模态中困难样本之间的结构关系。(2)集成了一个基于注意力的融合模块,在一个端到端训练的深度学习框架中实现不同模态图像的质量感知融合。
2. 方法概述
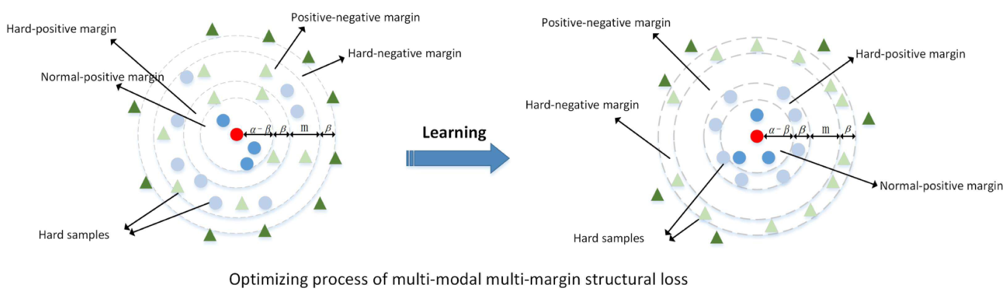
图1 多模态多边界结构损失优化
为了利用样本之间的结构关系,本文将所有样本分为四类:普通正样本、普通负样本、困难正样本、困难负样本。并为四类样本划分了边界,如图中所示,分别为α-β、β、m和β。图中红色圆圈是GT真实值,绿色三角形代表负样本,蓝色圆圈代表正样本。值得一提的是,浅蓝色的圆圈和浅绿色的三角形是很难区分的困难样本。箭头表示优化的梯度方向。多模态多边界结构损失的目的是使困难正样本进入困难正边缘所限制的区域(α区域),使困难负样本进入困难负边缘所限制的区域(β区域)。同时,所有正样本和负样本之间用正负边界m分隔,并利用它们的关系构建一个更鲁棒的特征嵌入。具体的公式以及推导请参阅原文。
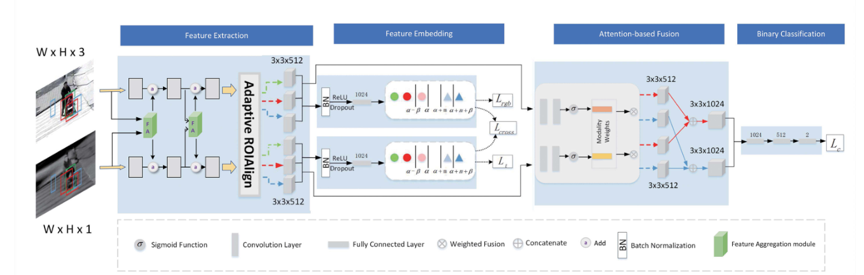
图 2 网络架构
图2为所提出网络的框架图。其中包含:(1)特征提取模块,由VGG-M以及特征聚合模块组成,目的是充分提取来自于可见光模态的热红外模态的特征。(2)特征嵌入模块,利用多模态多边界结构损失来指导网络对困难样本的优化方向。(3)注意力融合模块,利用一个轻量化的注意力机制来指导可见光和热红外模态自适应的融合,用以平衡不同挑战下两种模态对网络的贡献。
3. 实验结果
下图为样本的特征嵌入可视化。蓝点代表普通负样本,浅蓝色的是困难负样本。黄色点为普通正样本,橙色点为困难正样本。图3可视化结果说明了所提出损失的有效性。
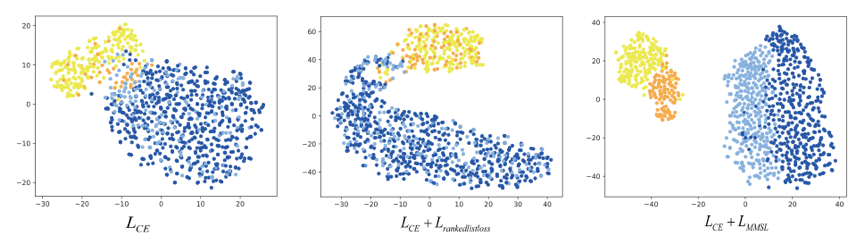
图3 样本特征嵌入可视化
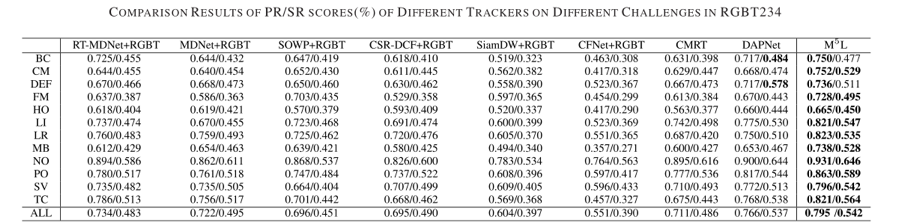
图 4 RGBT234挑战分析
本文在GTOT和RGBT234上进行实验分析,并且给出RGBT234中不同挑战序列下的对比分析,与其它先进的RGBT跟踪算法相比,本文方法取得了更准确的跟踪结果。

图 5 跟踪可视化
06
Big-Hypergraph Factorization Neural Network for Survival Prediction from Whole Slide Image
作者:狄东林, 张军,雷富强,田奇,高跃
单位:清华大学、华为云
邮箱:
donglin.ddl@gmail.com;
junejzhang@tencent.com;
lei@shiplinker.com;
tian.qi1@huawei.com;
gaoyue@tsinghua.edu.cn
论文:
https://ieeexplore.ieee.org/document/9667788
一、引言
基于千兆像素的全尺寸病理图(WSI)的生存预测成为近年来医学影像分析领域的重要任务,该任务主要由WSI图像采样与表示、危险程度预测两部分组成。在WSI图像采样与表示中,病理信息与特征主要体现于局部病理组织微环境和全局拓扑结构。但是,这种复杂的组织间的关联使用卷积神经网络或图神经网络进行建模是非常困难的。对于卷积神经网络,其挑战是难以有效地对全局拓扑结构进行建模。而图网络结构则无法在超大规模采样数据上对特征进行高效编码。因此,针对病理图的精确表示,一种可以对超大规模数据进行建模的、能够建模复杂关联结构的方法是非常重要的。为了解决以上问题,本文提出大超图(Big-Hypergraph)分解神经网络,其包含分解嵌入模块,用于将顶点和超边之间的相关性编码为两个低维潜在语义空间。其次在预测危险系数中,本文联合考虑单病人方法 (point-wise)、病人对方法 (pair-wise)、病人列表方法 (list-wise) ,提出了一种基于多级排序的回归,不仅考虑了排名顺序信息也降低了不确定性数据的有效性。
二、方法简述
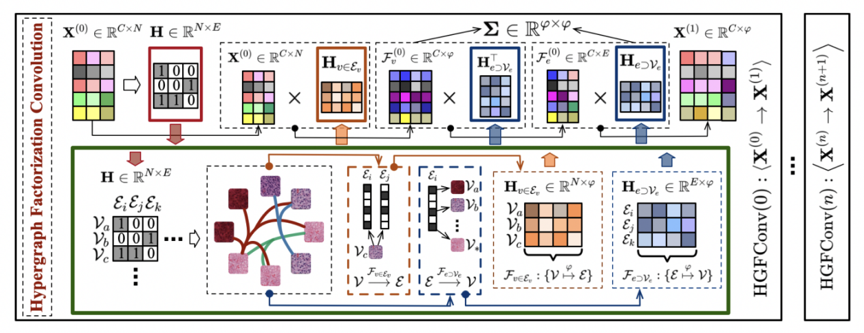
首先我们会在千兆像素的WSI随机选取采样区域,并通过OTSU算法筛选出有用区域,使用预训练网络(如ResNet、VGG)对每一个采样区域提取初始特征。进而将每一个采样区域视为节点,根据特征使用KNN建立超图结构。由于这样建立的超图的关联矩阵是稀疏的。本文提出了一个分解模块,使具有大规模顶点的大型超图能够成功训练。该分解模块如上图绿框所示,使模型能够将关联矩阵的维数降低到两个低维潜在相关嵌入空间,即“节点到所属超边”及“超边到所含节点”。经过大超图分解神经网络模块,最终可得到代表WSI的特征。在多级排序生存预测模块,首先使用MLP预测每一个病人的风险指数,然后使用Cox似然回归算出单病人方法的损失函数,并利用贝叶斯一致性调整损失函数优化病人对排序,使用Lambda Loss衍生出损失函数优化病人列表排序。通过上述介绍的方法,我们就可以对病理图进行密集地采样,并且有效地使用超图分解神经网络对大规模的病例数据进行建模,从而得到表征能力更好的编码,做出更准确的存活预测。
三、实验
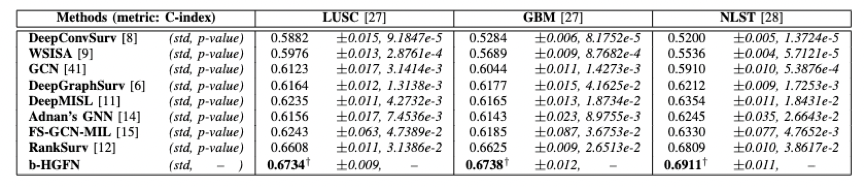
本文在三个公开数据集进行实验,包括两个肺癌数据集(LUSC、NLST)以及一个脑癌数据集(GBM)。上表说明本文提出的方法在广泛用于衡量逻辑回归模型中二元结果的拟合优度cindex指标优于其它所有的基准。从标准差和p值,我们可以观察到b-HGFN 在所有数据集上都比其他方法具有更稳定的性能。这表明,我们提出的大超图分解模型能够有效表示全尺寸病理图,从而能够更准确、更可靠地预测肺癌和脑癌。

编辑人:桑基韬、聂礼强
专委会责任副主任:徐常胜