【泡泡点云时空】基于弱监督学习的3D形状补全方法(CVPR2018-10)
泡泡点云时空,带你精读点云领域顶级会议文章
标题:Learning 3D Shape Completion from Laser Scan Data with Weak Supervision
作者:David Stutz, MPI for Intelligent Systems and University of Tubingen, Andreas Geiger, Computer Vision and Geometry Group, ETH Zurich
来源:CVPR2018 ( IEEE Conference on Computer Vision and Pattern Recognition)
编译:任乾
审核:郑英林
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

利用局部点云进行3D形状补全是计算机视觉和计算机图形学中的基本问题。最近这方面的研究可以分为数据驱动的和基于学习的两大类。数据驱动的方法依赖于形状模型,需要根据观察结果去优化参数。相反,基于学习的方法可以避免复杂的优化步骤,而是使用深度神经网络直接从不完整的观测中去估计完整的形状。但是,他们都需要完全监督,这在实践中是很难满足的。在这里,我们提出了一种弱监督学习方法来补全3D形状,这种方法既不需要耗时的优化过程,也不需要直接监督。为了在不使用合成数据时学习形状,我们设计了基于深度神经网络的分阶段最大似然估计方法,可以在不损失精度的前提下高效地完成形状补全。基于ShapeNet和KITTI数据集的3D形状补全结果显示,我们提出的方法可以跟完全监督的方法,以及先进的数据驱动的方法相媲美,而且速度更快。在ModelNet数据集上的测试结果显示,该方法还能够适用于其他对象类别。
实现流程
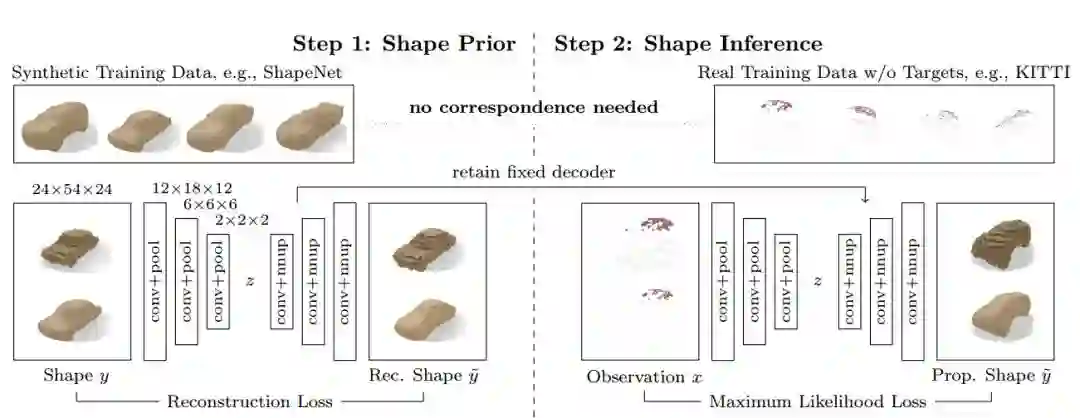
图1 我们结合KITTI数据集上的例子来说明算法实现的流程。一共分两个步骤,第一步使用ShapeNet上的汽车模型训练自动编码机(VAE),汽车模型是在一个24 × 54 × 24体素的方格中使用占用栅格和有符号度量函数(SDFs)进行描述的。第二步对预训练的解码器进行重新训练,并同时训练一个固定编码器。该网络可以在不需要更多监督数据的情况下使用最大似然损失函数完成训练。预训练的解码器将预测约束为汽车的形状,而最大似然损失估计使预测结果与观测保持一致。
实现效果

图2 给定一个3D边界框和部分点云数据(图上左),实现了物体完整形状的预测(图上右)。在KITTI数据集上的3D补全结果见图下

Abstract
3D shape completion from partial point clouds is a fundamental problem in computer vision and computer graphics. Recent approaches can be characterized as either data driven or learning-based. Data-driven approaches rely on a shape model whose parameters are optimized to fit the observations. Learning-based approaches, in contrast, avoid the expensive optimization step and instead directly predict the complete shape from the incomplete observations using deep neural networks. However, full supervision is required which is often not available in practice. In this work, we propose a weakly-supervised learning-based approach to 3D shape completion which neither requires slow optimization nor direct supervision. While we also learn a shape prior on synthetic data, we amortize, i.e., learn, maximum likelihood fitting using deep neural networks resulting in efficient shape completion without sacrificing accuracy. Tackling 3D shape completion of cars on ShapeNet and KITTI, we demonstrate that the proposed amortized maximum likelihood approach is able to compete with a fully supervised baseline and a state-of-the-art data-driven approach while being significantly faster. On ModelNet, we additionally show that the approach is able to generalize to other object categories as well.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com



