【泡泡点云时空】PointPillars:点云物体检测的快速编码器
泡泡点云时空,带你精读点云领域顶级会议文章
标题:PointPillars: Fast Encoders for 3D Object Detection from Point Clouds
作者:Lang Alex H,Vora Sourabh,Caesar Holger,Zhou Lubing,Yang Jiong,Beijbom Oscar
来源:arxiv 2018
编译:陈贝章
审核:徐二帅
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

点云中的物体检测在许多机器人领域例如自动驾驶方面有重要的应用。在本文中,我们考虑将点云编码为适合下游检测流程的格式的问题。最近的文献提出了两种类型的编码器,固定编码器往往速度快但是以牺牲精度为前提,而从数据中学习的编码器更准确,但速度较慢。在这项工作中,我们提出了PointPillars,一种新颖的编码器,它利用PointNets来学习在垂直列柱体组织中的点云的特征。虽然编码特征可以与任何标准2D卷积检测架构一起使用,但我们进一步提出了精简的下游网络。大量实验表明PointPillars在速度和精度方面都大大优于以前的编码器。尽管只使用了激光雷达,但我们的完整的检测系统在3D和鸟瞰KITTI基准测试方面都显着优于现有技术,即使在融合方法中也是如此。该检测成功的在62 Hz频率下运行,时间效率提高了2-4倍。我们的方法的一个更快版本与105 Hz的现有技术相当。这些基准数据集测试表明,PointPillars在点云目标检测中是一个很好的编码方法。
主要贡献
1. 我们提出了PointPillars,一种新颖的点云编码器和网络,在点云上实现3D物体检测网络的端到端训练;
2. 我们展示了如何将柱体上的所有计算都设置为稠密的2D卷积,从而实现62 Hz的检测速率并比其他方法快2-4倍;
3. 我们对KITTI数据集进行实验,并在BEV和3D基准测试中展示了对汽车,行人和骑车人检测的最新结果;
4. 我们进行了几项模型简化测试,以检验能够实现强检测性能的关键因素。
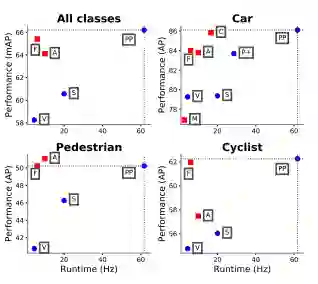
图1:显示了我们提出的PointPillars,在KITTI测试集的鸟瞰视图上的性能与速度。纯激光雷达的方法标记为蓝色圆圈; 激光雷达和视觉融合的方法标记为为红色方块。方框中大写的字母代表了KITTI排行榜前排的不同方法:M:MV3D,A:AVOD,C:ContFuse,V:VoxelNet ,F:Frustum PointNet ,S:SECOND ,P +:PIXOR ++ 。PointPillars在速度和准确度方面都大大优于所有其他纯激光雷达的方法。除了行人检测外,它还优于所有基于融合的方法。在3D标准上实现了类似的性能。
算法框架
PointPillars接受点云作为输入并输出对汽车,行人和骑车人检测的3D框。它由三个主要阶段组成(图2)
1. 将点云转换为稀疏伪图像的特征编码器网络;
2. 2D卷积基础网路(backbone),用于将伪图像处理成高维特征表示;
3.检测头部(detection head)对类别预测和对3D检测框的位置进行回归;
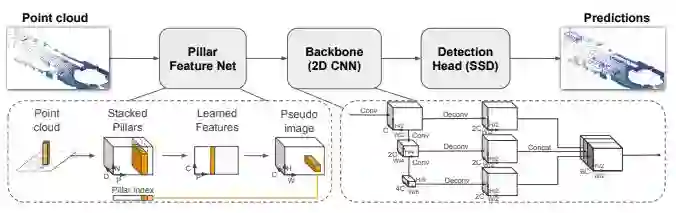
图2:网络框架概述。该网络的主要部分是柱体特征网络,基础网络(Backbone)和检测头部(SSD)。有关详细信息,请参阅第2节。原始点云被转换为堆叠柱张量和柱索引张量。编码器使用堆叠的柱来学习一组可以分散回到卷积神经网络的2D伪图像的特征。检测头部(SSD)使用基础网络(backbone)的特征来预测物体的3D边界框。
主要结果

图3: KITTI结果的定性分析。我们清晰地显示了激光雷达点云的鸟瞰图,以及投影到图像中的3D边界框。值得注意的是,我们的方法仅使用激光雷达。我们展示了汽车(橙色),骑车者(红色)和行人(蓝色)的预测框。真值框以灰色显示。边界框的方向由连接底部中心和检测框前部的线条表示。

图4: KITTI的失败案例。图3中的可视化设置相同,但侧重于几种常见的故障模式。
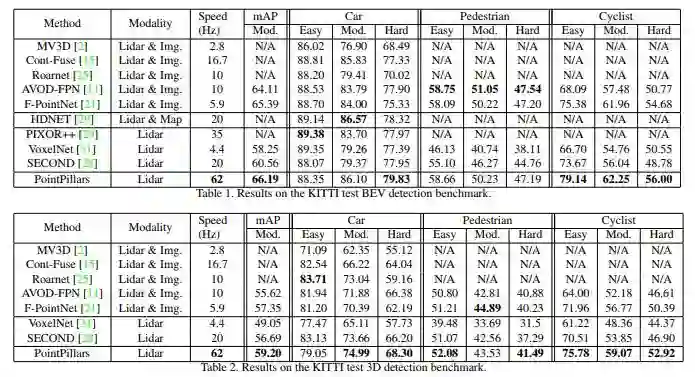
表1: KITTI数据集BEV检测基准的结果。KITTI数据集3D检测基准的结果。

表3: KITTI测试平均方向相似性(AOS)检测基准的结果。SubCNN 是性能最佳的仅图像方法,而AVOD-FPN,SECOND和PointPillars是包括方向预测的 3D物体检测器
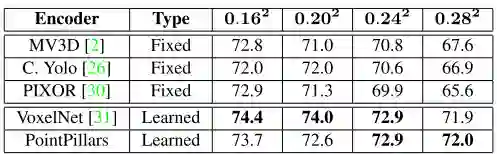
表 4: 编码器性能评估。为了公平地比较编码器,使用了相同的网络架构和训练过程,并且在实验之间仅改变了编码器和xy平面的分辨率。性能在KITTI 上测量为BEV mAP(平均精度值)。在较大分辨率下,基于学习的编码器明显优于固定编码器。
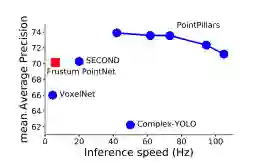
图5: 在行人,自行车和汽车上设置的KITTI 的BEV检测性能的平均检测精度(mAP)与速度(Hz)。蓝色圆圈表示仅激光雷达方法,红色方块表示使用激光雷达和视觉融合的方,通过使用不同大小的的柱体栅格尺寸实现了不同的操作。最大柱体的数量随分辨率而变化,分别设定为16000,12000,12000,8000,8000

Abstract
Object detection in point clouds is an important aspect of many robotics applications such as autonomous driving. In this paper we consider the problem of encoding a point cloud into a format appropriate for a downstream detection pipeline. Recent literature suggests two types of encoders; fixed encoders tend to be fast but sacrifice accuracy, while encoders that are learned from data are more accurate, but slower. In this work we propose PointPillars, a novel encoder which utilizes PointNets to learn a representation of point clouds organized in vertical columns (pillars). While the encoded features can be used with any standard 2D convolutional detection architecture, we further propose a lean downstream network. Extensive experimentation shows that PointPillars outperforms previous encoders with respect to both speed and accuracy by a large margin. Despite only using lidar, our full detection pipeline significantly outperforms the state of the art, even among fusion methods, with respect to both the 3D and bird’s eye view KITTI benchmarks. This detection performance is achieved while running at 62 Hz: a 2 - 4 fold runtime improvement. A faster version of our method matches the state of the art at 105 Hz. These benchmarks suggest that PointPillars is an appropriate encoding for object detection in point clouds.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com




