【泡泡点云时空】基于分割方法的物体六维姿态估计
泡泡点云时空,带你精读点云领域顶级会议文章
标题:Segmentation-driven 6D Object Pose Estimation
作者:Yinlin Hu, Joachim Hugonot, Pascal Fua, Mathieu Salzmann
来源:CVPR 2019
编辑:鹦鹉
审核:Lionheart
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

估计物体的6D姿态的最新趋势是训练深度网络以直接从图像中恢复位姿或预测3D关键点的2D位置,从中可以使用PnP算法获得位姿。在这两种情况下,对象都被视为全局实体,并且计算单个姿态估计。因此,它们的结果对于较大的遮挡是非常敏感的。
本文提出了基于分段的6D姿态估计框架,其中对象的每个可见部分以2D关键点位置的形式贡献局部姿态估计。然后,我们使用预测的置信度来将这些姿态候选者组合成一组强大的3D到2D对应关系,从中可以获得可靠的姿势估计。我们在具有挑战性的Occluded-LINEMOD和YCB-Video数据集方面表现优于最先进的技术,这证明我们的方法可以处理多个被遮挡的纹理缺失的对象,此外,它架构简单容易提高系统实时性。
代码地址:https://github.com/cvlab epfl/segmentation-driven-pose
主要贡献
提出一种用于姿态估计预测网络。
即使在存在多个纹理不良的遮挡对象时,也可以生成准确的6D对象姿态估计。
通过Occluded-LINEMOD和YCB-Video数据集的测试结果展示该新框架的优势。
网络结构
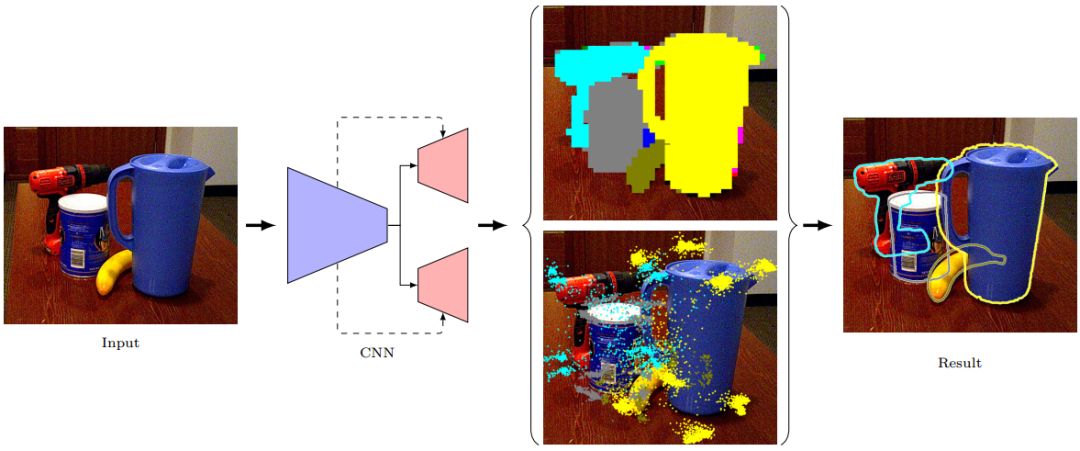
网络架构有两个分支流:一个用于对象分割,另一个用于2D关键点检测。这两个流共享一个公共编码器(encoder),但解码器是分开的。分割流(Segment pipeline)预测在每个网格位置处观察到的对象的语义标签。关键点检测流(Keypoint pipeline)预测该对象的2D关键点位置。
分割网络与关键点检测网络
双流网络的输出:
(a)分割流为叠加在图像上的虚拟网格的每个单元分配标签。
(b)在关键点检测流中,每个网格单元预测它所属对象的2D关键点位置。在这里,我们将8个边界框角作为我们的关键点。
分割网络,在训练期间,我们可以访问3D对象模型及其真实的姿势。因此,我们可以通过在图像中投影3D模型来生成真实语义标签,同时考虑每个对象的深度来处理遮挡。
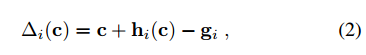
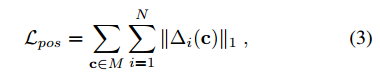
关键点预测网络,并不直接预测关键点的位置,而是预测相对于相应网格单元中心的偏移矢量,通过定义残差项(2)和损失函数(3),逼近2D真值数据。
如上所述,回归流还输出每个预测关键点的置信度值si(c),其通过网络输出上的S形函数获得。置信度值反映预测的2D投影与真值的接近度。描述如下:
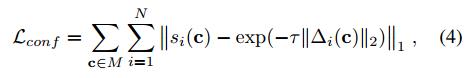
最后结合位置和置信度的损失函数,得到关键点预测回归网络的损失函数。
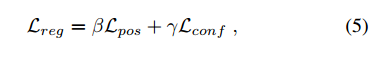
3.姿态估计与索引
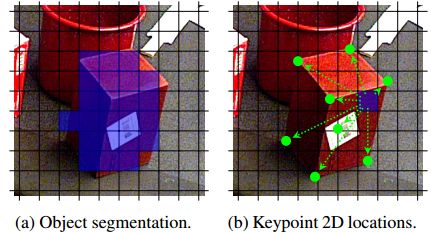
(a)预测覆盖在图像上属于杯子的网格单元。
(b)每个预测相应关键点的2D位置,如绿点所示。
(c)对于每个3D关键点,选择网络最有信心的n = 10个2D位置。
(d)针对2D-3D关键点对,利用基于RANSAC的PnP产生准确的姿势估计,如图上绘制的轮廓。
实验
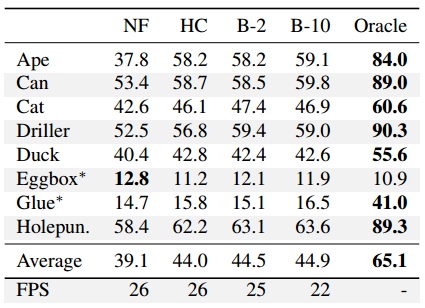
在Occluded-LINEMOD数据集上实验
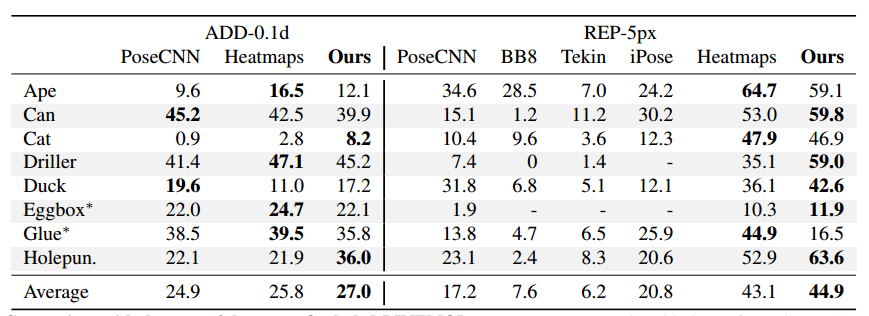
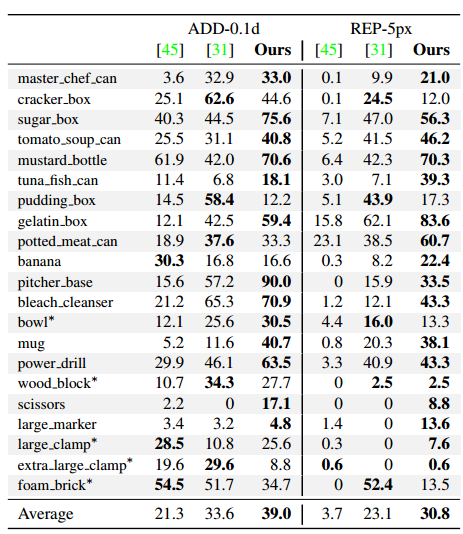
在具有挑战性的OccludedLINEMOD和YCB-Video数据集上评估提出的多物体6D姿态估计方法。REP error它反应了二维重投影误差,由估计的3D模型点的二维投影点与groundtruth之间的平均误差构成,单位是像素。

ADD误差是三维位姿误差。由估计的三维位置和姿态与groundtruth间的误差。在每列中,我们从上到下显示:前景分割mask,所有2D重投影候选,所选2D重投影和最终姿势结果。即使存在大的遮挡,我们的方法也能生成准确的姿态估计。此外,它可以实时处理多个对象。
我们将这些不同策略的结果与无融合方法进行比较,本方法总是使用由中心网格预测的2D重投影,我们将其称为无融合(NF)方法。这些结果证明所有融合方案都优于无融合方案。我们还展示了通过使用真实2D重投影为每个3D关键点选择最佳预测2D位置而获得的结果。这表明我们的方法由于改善置信度获得了性能提升甚至还可以设计更好的融合方案。在最后一行,我们还展示了这些不同策略的平均运行时间。

在YCB-Video数据集上实验
与YCB-Video上的PoseCNN比较。第一行、第二行分别为PoseCNN的结果和我们的方法的结果。证明了特别是在存在大的遮挡时,使用局部对象部分的好处。
结论
虽然我们的方法在大多数情况下表现良好,但它仍然不能处理最极端的遮挡和微小的物体。在这种情况下,我们依赖的网格难于表示这些。然而,这可以通过使用更精细的网格来解决,或者,为了限制计算负担,可以自适应地细分网格以更好地处理每个图像区域。此外,我们还没有测试为每个3D关键点选择最佳预测2D位置的的性能。这表明算法在提高预测置信度分数质量以及融合过程还有提升空间。这将是我们未来研究的主题。

Abstract
The most recent trend in estimating the 6D pose of rigid objects has been to train deep networks to either directly regress the pose from the image or to predict the 2D locations of 3D keypoints, from which the pose can be obtained using a PnP algorithm. In both cases, the object is treated as a global entity, and a single pose estimate is computed. As a consequence, the resulting techniques can be vulnerable to large occlusions.
In this paper, we introduce a segmentation-driven 6D pose estimation framework where each visible part of the objects contributes a local pose prediction in the form of 2D keypoint locations. We then use a predicted measure of confidence to combine these pose candidates into a robust set of 3D-to-2D correspondences, from which a reliable pose estimate can be obtained. We outperform the state-of-the-art on the challenging Occluded-LINEMOD and YCB-Video datasets, which is evidence that our approach deals well with multiple poorly-textured objects occluding each other. Furthermore, it relies on a simple enough architecture to achieve real-time performance. Our source code is publicly available at : https://github.com/cvlab-epfl/segmentation-driven-pose
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com



