【泡泡点云时空】Hand PointNet:基于点集的三维手势估计(CVPR2018-15)
泡泡点云时空,带你精读点云领域顶级会议文章
标题:Hand PointNet: 3D Hand Pose Estimation Using Point Sets
作者:Liuhao Ge, Yujun Cai, Junwu Weng, Junsong Yuan
来源:CVPR 2018
播音员:林明
编译:陈林卓
审核:郑英林
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

卷积神经网络(CNN)在基于深度图像的手势估计任务中取得了惊人的效果,不同于现有的以2D图像或者3D体素为输入的基于CNN的方法,我们提出的Hand PointNet 网络直接处理3D点云信息来作手部姿态回归,以归一化后的点云作为输入,我们提出的手势回归网络可以捕获复杂的手部结构并准确的回归一个低维表示的手部姿态,为了提升指尖检测的准确性,我们设计了一个指尖修正网络,它直接将预测的指尖坐标周围的点作为输入来修正指尖的坐标,在三个手部姿态数据集上的实验说明我们的网络超过了当前的所有方法。
方法
我们首先将手部的深度图像转换为降采样到N个点的3D点云,随即将它们在一个具有方向性的标定框(oriented bounding box)内进行归一化。我们使用pointnet架构来作为我们的特征提取网络。在这个网络中,我们以三维坐标(x,y,z)与表面法线为输入。pointnet的架构如图1所示:
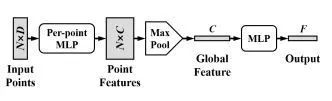
图1.pointnet的基本架构 。
在传统的点云识别任务中:如点云语义分割,输出对输入具有旋转不变性,我们可以使用空间变换网络来预测变换矩阵,然而在手势识别任务中,输出与输入的旋转相关,这使得网络端到端的训练变得困难,在这项工作中,我们提出了一种简单有效的方法来解决这个问题。我们使用主成分分析输入点云的坐标,得到的主成分方向作为标定框的朝向,标定框的x,y,z轴与输入点坐标的协方差矩阵的特征向量平行。具体公式如下所示:
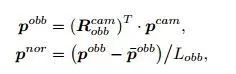
其中R为旋转矩阵,p为三维坐标,L为标定框的最大长度。
同时,我们设计了一个可以进行端到端训练的手势识别回归网络,该网络以pointnet网络为基础,输出一个3*M的矩阵,其中M为点的个数。我们使用下式来优化网络的参数,为了提升网络的精度,我们设计了指尖修正网络,具体的网络如下图所示:
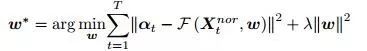
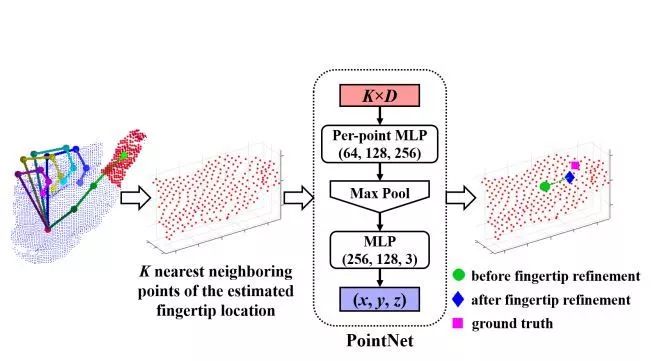
图2.修正网络的架构。
实验
我们将我们的方法在三个公开的手势数据集上进行了测试,这三个数据集分别是:NYU,MSRA和ICVL。我们同时也和其他的方法进行了对比,实验证明我们的方法超过了当前所有的方法。
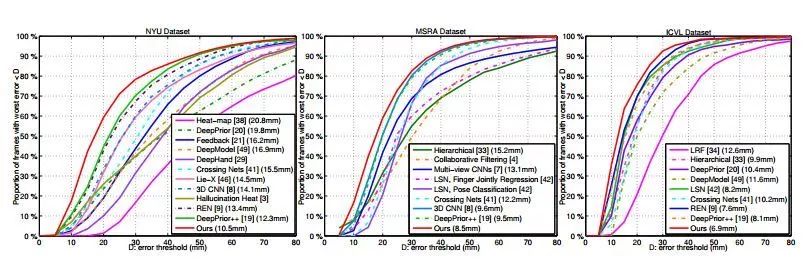
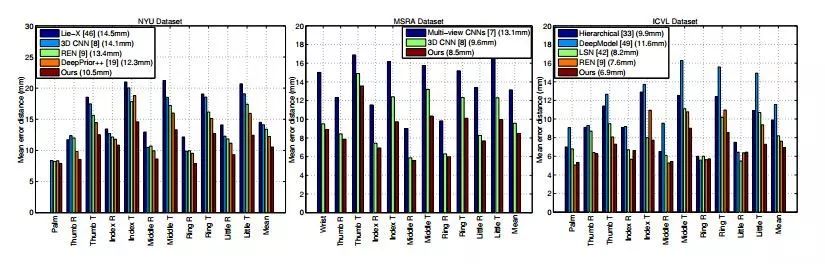
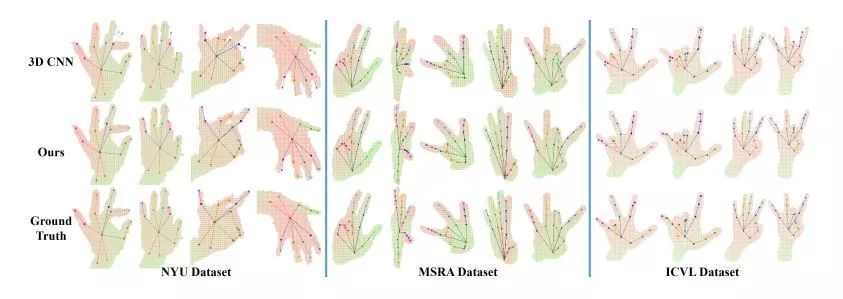
图3.在NYU, MSRA与ICVL数据集上的实验结果。

Abstract
Convolutional Neural Network (CNN) has shown promising results for 3D hand pose estimation in depth images. Different from existing CNN-based hand pose estimation methods that take either 2D images or 3D volumes as the input, our proposed Hand PointNet directly processes the 3D point cloud that models the visible surface of the hand for pose regression. Taking the normalized point cloud as the input, our proposed hand pose regression network is able to capture complex hand structures and accurately regress a low dimensional representation of the 3D hand
pose. In order to further improve the accuracy of fingertips, we design a fingertip refinement network that directly takes the neighboring points of the estimated fingertip location as input to refine the fingertip location. Experiments on three challenging hand pose datasets show that our proposed method outperforms state-of-the-art methods.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com




