PaperWeekly 第28期 | 图像语义分割之特征整合和结构预测
余昌黔
华中科技大学硕士
研究方向为图像语义分割
知乎专栏
https://zhuanlan.zhihu.com/semantic-segmentation
前言
近来阅读了 PASCAL VOC 2012 排行榜上前几的文章,包括 PSPNet 和林国省老师的几篇论文,觉得现在在 semantic segmentation 领域对于 Multi-scale Features ensembling 的关注又多起来了(当然其实一直都应用的挺多),然后林国省老师对 CRF 有一些新的认识和解读。这些都将总结于此。
两个发展方向
特征整合(Feature Ensembling)
又分为:多尺度(multi-scale) 特征整合
多级(multi-level)特征整合
结构预测(Structure Prediction)
比如之前经常使用的条件随机场
特征整合
多尺度整合
PSPNet
这个方法在前一段时间是 PASCAL VOC 2012 排行榜上的第一,现在的第二。
语义分割中常见问题
关系不匹配(Mismatched Relationship)
场景中存在着可视模式的共现。比如,飞机更可能在天上或者在跑道上,而不是公路上。易混淆的类别(Confusion Categories)
许多类别具有高度相似的外表。不显眼的类别(Inconspicuous Classes)
场景中包括任意尺寸的物体,小尺寸的物体难以被识别但是有时候对于场景理解很重要。
Note: 这些大多数错误都部分或者完全和上下文关系以及全局信息有关系,而 PSPNet 就是为了整合不同区域的 context 来获取全局的 context 信息。
网络结构
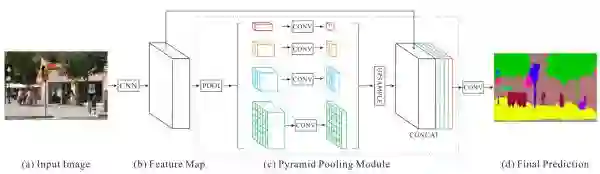
其中的一些 tricks:
图片输入的 CNN 是 ResNet,使用了 dilated convolution
Pyramid Pooling Module 中的 conv 是1×1的卷积层,为了减小维度和维持全局特征的权重
Pyramid Pooling Module 中的 pooling 的数量以及尺寸都是可以调节的
上采样使用的双线性插值
poly learning rate policy
数据扩增用了:random mirror, random resize(0.5-2), random rotation(-10 到 10 度), random Gaussian blur
选取合适的 batchsize
结构还是很清晰明确的,没太多可说的。
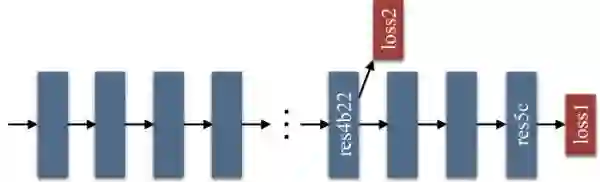
此外,文中还提到了为了训练使用了一个辅助的 loss,并不在我们讨论内容之内,仅展示一下示意图:
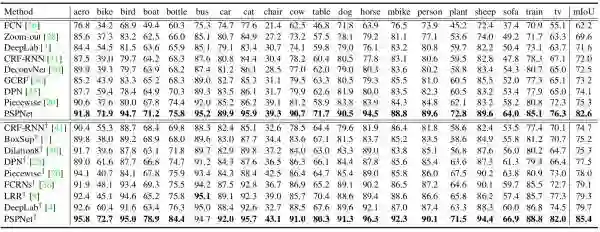
PSPNet 在 PASCAL VOC 2012 上测试的结果如下:
FeatMap-Net
这是林国省老师两篇论文中提到的网络结构的前面一部分,我把它抽取出来在此讨论特征整合,这部分网络结构利用多尺度 CNN 和 sliding pyramid pooling 来获取 patch-background 的上下文信息。
网络结构
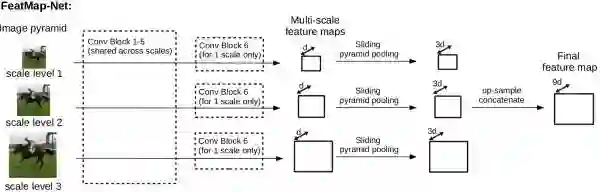
其中:
图片进来先进行 0.4, 0.8, 1.2 的放缩
前 1-5 conv block 是共享参数的
向上采样还是我们熟悉的双线性插值
Sliding Pyramid Pooling

其中使用的是滑动的 pooling,即 stride 为 1,所以不降低 feature map 的尺寸。不同尺寸的窗口有利于获得不同大小的背景信息,而且增加了 field-of-view,这样 feature vector 能编码更大范围的信息(feature vector 会在之后的结构中使用,下文会介绍到)。
多级整合
RefineNet
这个方法在前一段时间是 PASCAL VOC 2012 排行榜上的第三,现在的第四。本方法主要想解决的限制是:多阶段的卷积池化会降低最后预测结果图片的尺寸,从而损失很多精细结构信息。
现有方法的解决办法:
反卷积作为上采样的操作
反卷积不能恢复低层的特征,毕竟已经丢失了Atrous Convolution (Deeplab提出的)
带孔卷积的提出就是为了生成高分辨率的 feature map,但是计算代价和存储代价较高利用中间层的特征
最早的 FCN-8S 就是这样做的,但是始终还是缺少强的空间信息
以上所说方法在我之前的文章中都有提到,感兴趣的同学可以猛戳以下链接,这里就不赘述了。
图像语义分割之FCN和CRF: https://zhuanlan.zhihu.com/p/22308032?group_id=820586814145458176
作者主张所有层的特征都是有用的,高层特征有助于类别识别,低层特征有助于生成精细的边界。所以有了接下来的网络结构,说实话我是觉得有点复杂。
网络结构
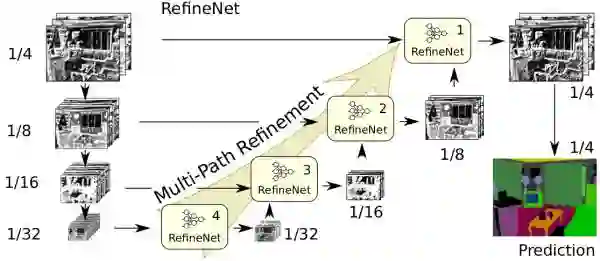
可以看见,整个结构其实是类似于 FCN-8S 的结构的,只是抽出特征更早,而且经过了 RefineNet 进行处理。
整个流程就是,1/32 的 feature map 输入 RefineNet 处理后和 1/16 的 feature map 再一起又输入一个 RefineNet 优化,后面的过程类似。
RefineNet
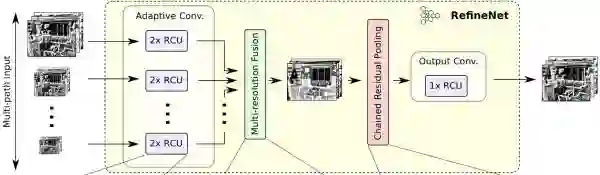
可以看出,每个 RefineNet 的输入是可以调整的,所以整个网络的连接也是可以修改的,当然作者做实验说明在他提出的其他变体中这种连接的效果最好。
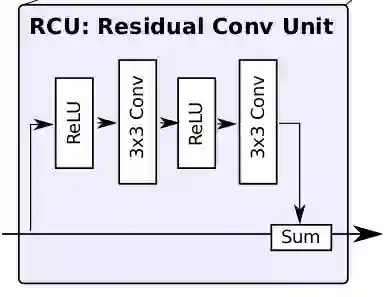
Residual Convolution Unit (RCU)
Multi-resolution Fusion
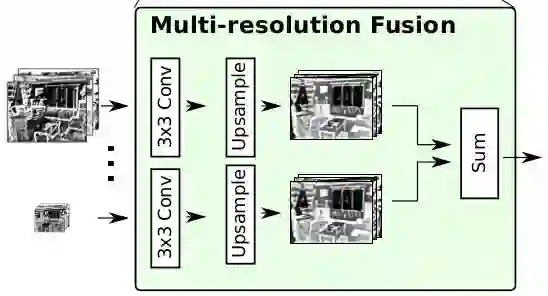
这里将输入的不同分辨率的 feature map 上采样到和最大 feature map 等尺寸然后叠加,此处的 conv 用于输入的参数自适应。
Chained Residual Pooling
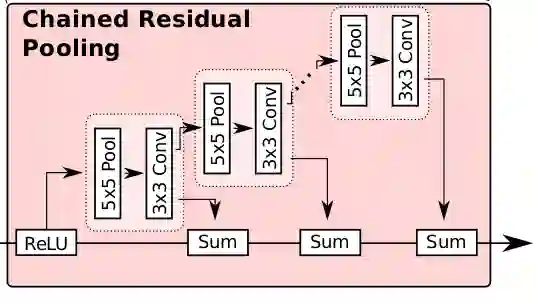
文中提到:
conv 作为之后加和的权重
relu 对接下来 pooling 的有效性很重要,而且使得模型对学习率的变化没这么敏感
这个链式结构能从大范围区域上获取背景 context
此处不得不提到,这个结构中大量使用了 identity mapping 这样的连接,无论长距离或者短距离的,这样的结构允许梯度从一个 block 直接向其他任一 block 传播。
现在回过头来看看 RefineNet 整个网络结构还是有些复杂的,但是确实还是有一些效果,这种直接将低层特征抽取来优化高层特征的措施可以想象能对结果进行一些优化。但是始终还是觉得这样的处理有点太复杂了。
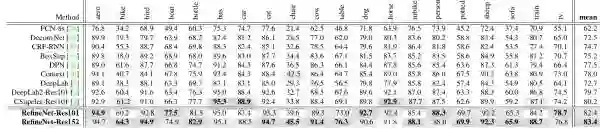
接下来看一下 RefineNet 在 PASCAL VOC 2012 上测试的结果:
结构预测 (CRF)
其实在语义分割这个领域很早就开始使用 CRF 或者 MRF 等对语义信息进行建模,在深度学习火起来之前就有不少这样的方法了。所以后来大家很自然地想到了深度学习和条件随机场的结合。但是,林国省老师指出现在利用条件随机场的方法都不太“地道”。
现有方法:
dense CRF 作为 FCN 输出的后处理,并没有真正地结合进 CNN
CRFasRNN 中将二者真正结合了,但是只有其中一元势函数的输入来自 CNN,二元势函数的输入来自于一元以及迭代,而且这里的二元势函数被强制考虑为局部平滑度
以上所说方法在我之前的文章中都有提到,感兴趣的同学可以猛戳以下链接,这里就不赘述了。
图像语义分割之FCN和CRF: https://zhuanlan.zhihu.com/p/22308032?group_id=820586814145458176
Contextual CRF
此处提到的结构是和前文所述 FeatMap-Net 为统一网络结构
整体结构
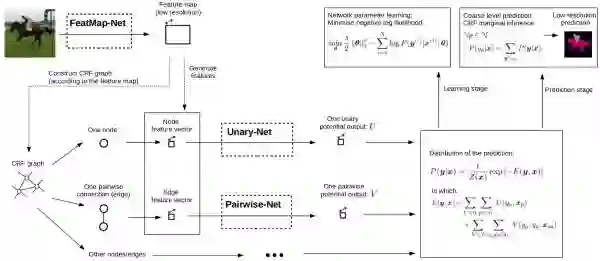
此处我们主要讨论 FeatMap-Net 之后的 CRF 的处理。林老师提出的这个方法对一元势函数和二元势函数都用 CNN 来直接进行处理,而且二元势函数是直接对空间语义建模更精确。
feature map 中的每个空间位置(即每个像素点)对应 CRF 图中的一个节点
Pairwise connection 就是通过每个节点与预定义的 spatial range box 中其他节点连接来体现的
不同的空间关系通过定义不同类型的 range box 来实现的,每种空间关系通过特定的 pairwise potential function 来建模
不同空间关系:
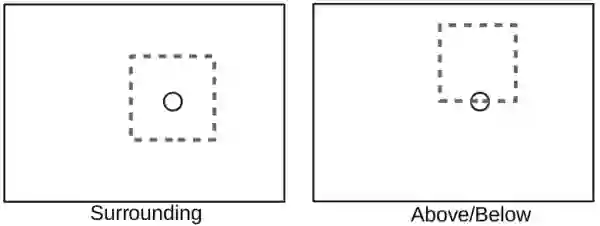
Surrounding 这样的关系就在对应节点的周围画框,Above/Below 这样的关系就让节点在一条边的中间然后在其上方或者下方画框,此处的框是原图最短边的 0.4.
此处我们回顾一下 CRF 的公式:
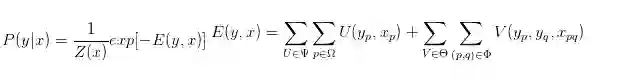
其中,Ψω 是不同类型一元势函数的集合,Ω 是一元势函数对应的节点集合;θ 是不同类型二元势函数的集合,Φ 是二元势函数对应的边的集合。
Unary Potential Functions
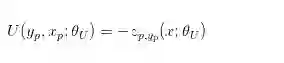
这里,Zp,yp 对应与第 P 个节点和第 Yp 个类别

一元势函数对应的处理就是从 Feature map 上的一个节点提取出 feature vector,然后连接几层全连接层,输出K个值,这个K就是需要预测的类别数。
Pairwise Potential Functions
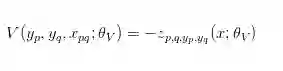

我觉得这里对二元势函数的处理很巧妙,将两个节点对应的 feature vector 提取出来然后连接到一起来学习两个节点之间的边,很棒!之后自然也是连接几层全连接层输出的是k² 个值,为了将所有类别之间的配对关系都考虑进去,但是这里产生的值应该有很多冗余。
Asymmetric Pairwise Functions
对于不对称的关系比如 Above\Below 就需要这样的不对称二元势函数进行学习,而这种势函数主要依赖于两个节点输入的顺序,这个可以通过两个 feature vector 连接的顺序来体现,所以我说这样的处理很巧妙啊。
至此,这种对 CRF 的解读讲完了~但是这篇文章中的有一些内容还不得不提一下:
这些 CRF 是用于 coarse prediciton stage 的,为了提升低分辨率的预测;文中提到在最后的输出的时候还是使用来的 dense crf 进行细化输出的(这就比较尴尬了,最开始还说人家不好,现在还是要使用……)
文中提到 Piecewise Learning 作为新的一种对 CRF 的训练方法,这里就没有阐述了,感兴趣的同学可以看看原文。
参考文献
1. Zhao H, Shi J, Qi X, et al. Pyramid Scene Parsing Network[J]. 2016.
2. Lin G, Shen C, Hengel A V D, et al. Efficient Piecewise Training of Deep Structured Models for Semantic Segmentation[C]// IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2016:3194-3203.
3. Lin G, Shen C, Hengel A V D, et al. Exploring Context with Deep Structured models for Semantic Segmentation[J]. 2016.
4. Lin G, Milan A, Shen C, et al. RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation[J]. 2016.
关于PaperWeekly
PaperWeekly 是一个分享知识和交流学问的学术组织,关注的领域是 NLP 的各个方向。如果你也经常读 paper,喜欢分享知识,喜欢和大家一起讨论和学习的话,请速速来加入我们吧。

关注微博: @PaperWeekly
微信交流群: 后台回复“加群”



