PSPNet ——语义分割及场景分析

原标题 | Review: PSPNet — Winner in ILSVRC 2016 (Semantic Segmentation / Scene Parsing)
作者 | Sik-Ho Tsang
翻译 | had_in(电子科技大学)、FlyingMoonLF
编辑 | Pita
语义分割的目标仅仅是获知已知对象的每个像素的类别标签。
场景解析是基于语义分割的,它的目标是获知图像内所有像素的类别标签。
场景解析
通过使用金字塔池化模块(Pyramid Pooling Module),在整合基于不同区域的上下文后,PSPNet在效果上超过了FCN、DeepLab和DilatedNet等时下最佳的方法。PSPNet最终:
获得2016年ImageNet场景解析挑战的冠军
在PASCAL VOC 2012和Cityscapes数据集上取得当时的最佳效果
工作已发表于2017年CVPR,被引量超过600次。(SH Tsang @ Medium )
本文提纲
1. 对全局信息的需要
2.金字塔池化模块
3. 一些细节
4. 模型简化研究
5. 与时下最佳方法的比较
1. 对全局信息的需要
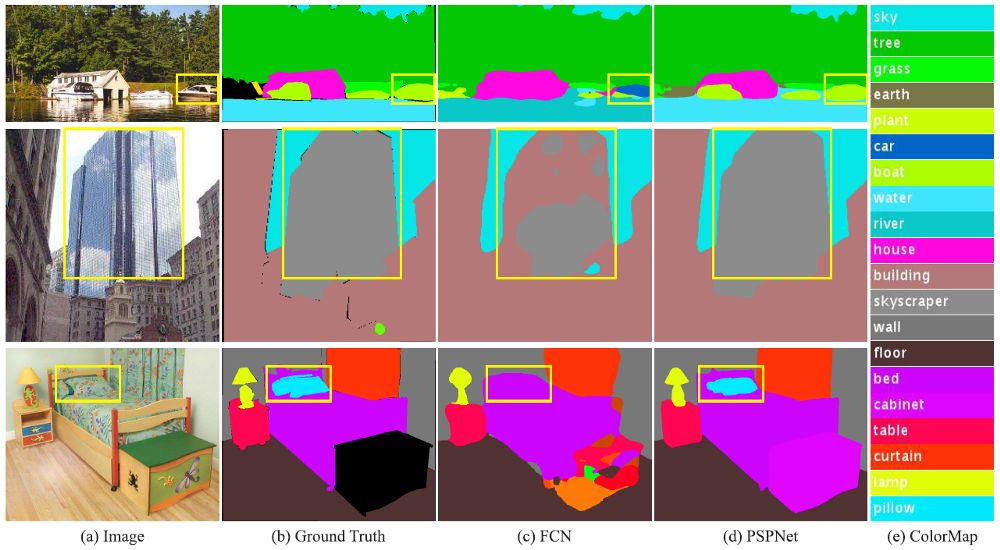
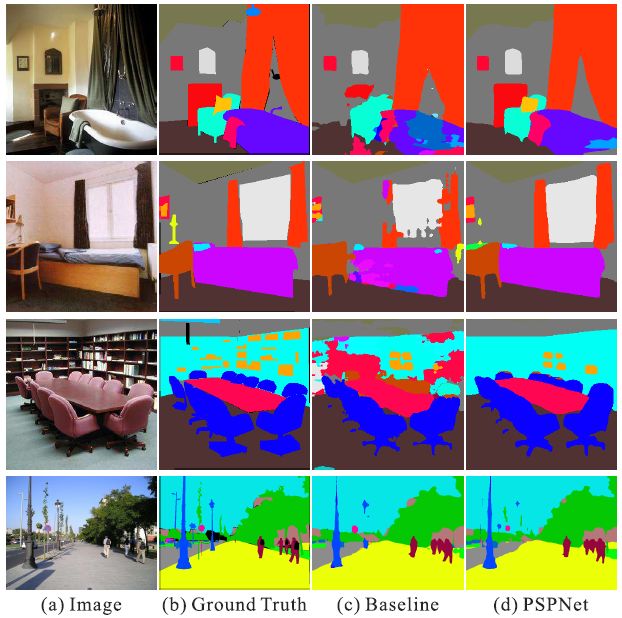
(c) 原有的未经上下文整合的FCN,(d) 经上下文整合的PSPNet
关系错误匹配:FCN基于外观将黄色框内的船预测为“汽车”。但根据常识,汽车很少会出现在河面上。
类别混淆:FCN将框内的对象一部分预测为“摩天楼”,一部分预测为“建筑物”。这些结果应当被排除,这样对象整体就会被分在“摩天楼”或“建筑物”其中一类中,而不会分属于两类。
细小对象的类别:枕头与床单的外观相似。忽略全局场景类别可能对导致解析“枕头”一类失败。
因此,我们需要图像的一些全局特征。
2.金字塔池化模块
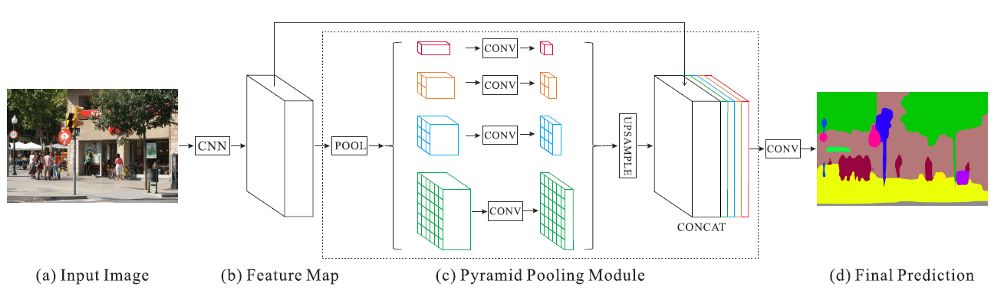
特征提取后的金字塔池模块(颜色在本图中很重要!)
红色:这是在每个特征map上执行全局平均池的最粗略层次,用于生成单个bin输出。
橙色:这是第二层,将特征map划分为2×2个子区域,然后对每个子区域进行平均池化。
蓝色:这是第三层,将特征 map划分为3×3个子区域,然后对每个子区域进行平均池化。
绿色:这是将特征map划分为6×6个子区域的最细层次,然后对每个子区域执行池化。
(c).2. 1×1 卷积用于降维
(c).3. 双线性插值用于上采样
(c).4. 连接上下文聚合特征
所有不同级别的上采样特征map都与原始特征map(黑色)连接在一起。这些特征映射融合为全局先验。这就是金字塔池模块(c)的终止。
(d)
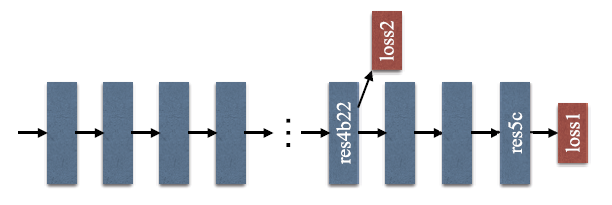
验证集用于模型简化测试。
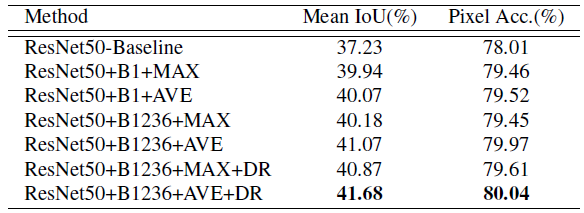
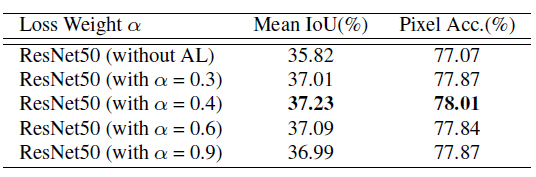
ResNet50-Baseline: 基于ResNet50的扩张FCN。
‘B1’和‘B1236’: bin大小分别为{1×1}和{1×1,2×2,3×3,6×6}的池化特征map。
‘MAX’和‘AVE’: 最大池操作和平均池操作
‘DR’: 降维.
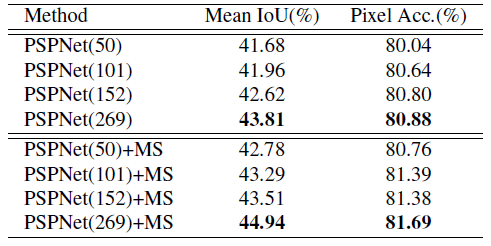
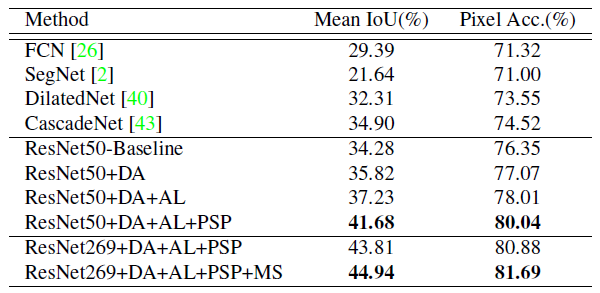
5. 与最先进方法的比较
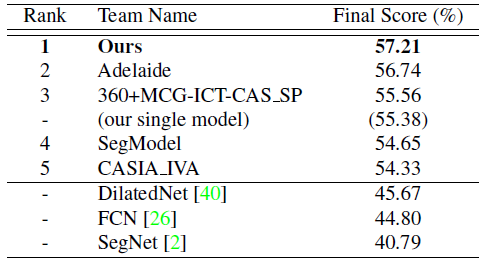
5.1. ADE2K - ImageNet场景解析挑战赛2016
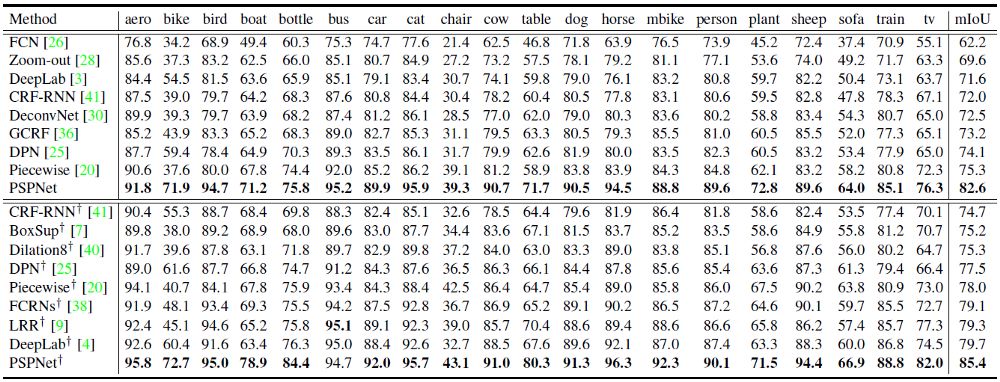
5.2. PASCAL VOC 2012

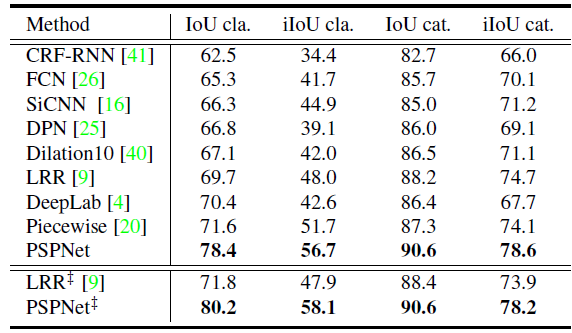
5.3. Cityscapes


相关参考内容,请点击 阅读原文 访问查看。


From 电子科技大学

此人太懒,啥也没填





