专栏 | CVPR 2017论文解读:Instance-Aware图像语义分割
机器之心专栏
作者:梁继
本届 CVPR 2017大会上出现了很多值得关注的精彩论文,国内自动驾驶创业公司 Momenta 联合机器之心推出 CVPR 2017 精彩论文解读专栏,本文是此系列专栏的第五篇,介绍了清华大学与微软的论文《Fully Convolutional Instance-aware Semantic Segmentation》,作者为 Momenta 高级研发工程师梁继。

论文链接:https://arxiv.org/pdf/1611.07709.pdf
自从 FCN(Fully Convolutional Networks for Semantic Segmentation)一文将全卷积,端到端的训练框架应用在了图像分割领域,这种高效的模式被广泛应用在了大多数的语义分割任务(semantic segment)中。它在网络结构中只使用卷积操作,输出结果的通道个数和待分类的类别个数相同。后接一个 softmax 操作来实现每个像素的类别训练。
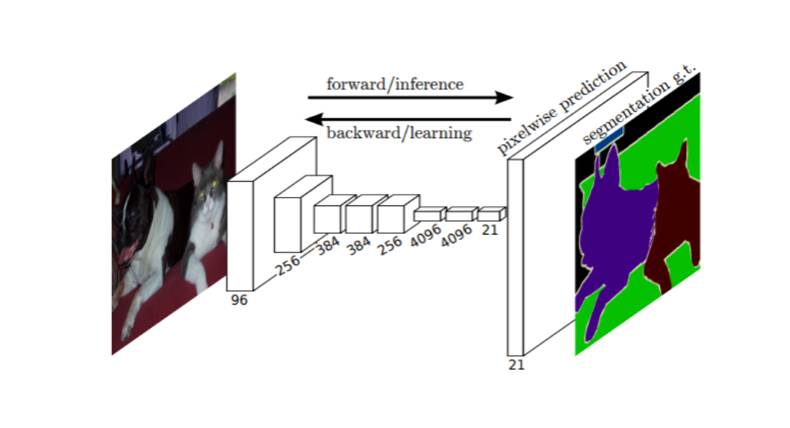
物体分割(instance aware segment)有别于语义分割。在语义分割中,同一类的物体并不区分彼此,而是统一标记为同一类。但物体分割需要区分每一个独立的个体。

上图的示例可以看出两个任务的区别。左图中的五只羊,在语义分割任务中(中图),被赋予了同一种类别标签。而在物体分割中(右图),每只羊都被赋予了不同的类别。
在一张图像中,待分割的物体个数是不定的,每个物体标记一个类别的话,这张图像的类别个数也是不定的,导致输出的通道个数也无法保持恒定,所以不能直接套用 FCN 的端到端训练框架。
因此,一个直接的想法是,先得到每个物体的检测框,在每个检测框内,再去提取物体的分割结果。这样可以避免类别个数不定的问题。比如,在 faster rcnn 的框架中,提取 ROI 之后,对每个 ROI 区域多加一路物体分割的分支。
这种方法虽然可行,但留有一个潜在的问题:label 的不稳定。想象一下有两个人(A,B)离得很近,以至于每个人的检测框都不得不包含一些另一个人的区域。当我们关注 A 时,B 被引入的部分会标记为背景;相反当我们关注 B 时,这部分会被标记为前景。
为了解决上述问题,本文引用了一种 Instance-sensitive score maps 的方法(首先在 Instance-sensitive Fully Convolutional Networks 一文中被提出),简单却有效的实现了端到端的物体分割训练。
具体的作法是:
将一个 object 的候选框分为 NxN 的格子,每个格子的 feature 来自不同通道的 feature map。
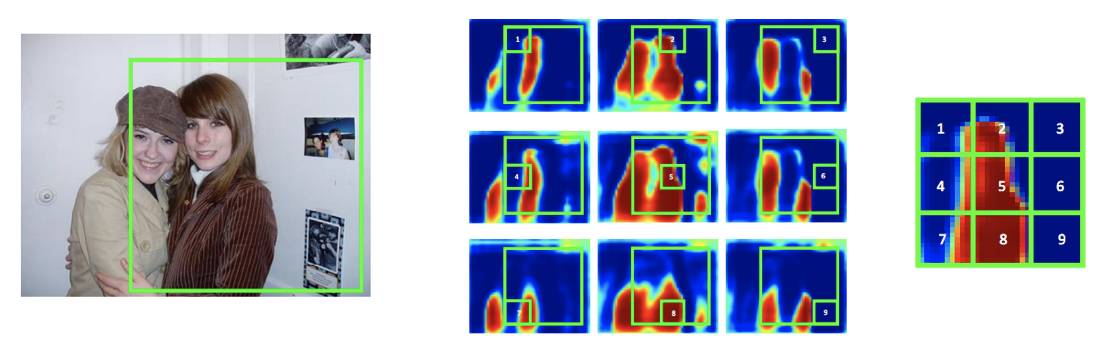
以上图为例,可以认为,将物体分割的输出分成了 9 个 channel,分别学习 object 的左上,上,右上,….. 右下等 9 个边界。
这种改变将物体从一个整体打散成为 9 个部分,从而在任何一张 feature map 上,两个相邻的物体的 label 不再连在一起(feature map 1 代表物体的左上边界,可以看到两个人的左上边界并没有连在一起),因此,在每张 feature map 上,两人都是可区分的。
打个比喻,假设本来我们只有一个 person 类别,两个人如果肩并肩紧挨着站在一起,则无法区分彼此。如果我们划分了左手,右手,中心躯干等三个类别,用三张独立的 feature map 代表。那么在每张 feature map 上两个人都是可区分的。当我们需要判断某个候选框内有没有人时,只需要对应的去左手,右手,中心躯干的 feature map 上分别去对应的区域拼在一起,看能不能拼成一个完整的人体即可。
借用这个方法,本文提出了一个物体分割端到端训练的框架,如上图所示,使用 region proposal 网络提供物体分割的 ROI,对每个 ROI 区域,应用上述方法,得到物体分割的结果。
文章中还有一些具体的训练细节,不过这里不再占用篇幅赘述。本文最大的价值在于,第一个提出了在物体分割中可以端到端训练的框架,是继 FCN 之后分割领域的又一个重要进展。
Q&A
1 文中将物体划分为 NxN 的格子,这种人为规则是否有不适用的情况?
A:目前还没有发现不适用的情况。对于硬性划分带来的潜在问题,可以考虑一些 soft 分格的方法。
2 是否考虑去掉 rpn 提取 proposal 的步骤,直接在整图上做 multi class 的 instance aware segment?
A:这也是我们要尝试实现的。
3 instance aware segment 目前主要的应用场景是什么?
A:不清楚。留给做应用开发的人去发掘。
Momenta CVPR 2017 系列专栏:
本文为机器之心专栏,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



