来源:“上海人工智能实验室”
对图像和视频上的表征学习而言,有两大痛点:局部冗余——视觉数据在局部空间、时间、时空邻域具有相似性,这种局部性质容易引入大量低效的计算;全局依赖——要实现准确的识别,需要动态地将不同区域中的目标关联,建模长时依赖。而现在的两大主流模型 CNN 和 ViT,往往只能解决部分问题。CNN 通过卷积有效降低了局部冗余,但受限的感受野难以建模全局依赖;而 ViT 凭借自注意力可捕获长距离依赖,但在浅层编码局部特征十分低效,导致过高冗余。
为能同时解决上述两大痛点,上海人工智能实验室联合商汤科技共同提出一种新的 UniFormer(Unified Transformer)框架, 它能够将卷积与自注意力的优点通过 Transformer 进行无缝集成。与经典的 Transformer 模块不同,UniFormer 模块的相关性聚合在浅层与深层分别配备了局部全局token,能够同时解决冗余与依赖问题,实现了高效的特征学习。包括 ICLR2022 接受的 video backbone,以及为下游密集预测任务设计的拓展版本,UniFormer 整套框架在各种任务上都能表现出比现有 SOTA 模型更好的性能。
论文标题:
UniFormer: Unified Transformer for Efficient Spatiotemporal Representation Learning
论文链接: https://arxiv.org/abs/2201.04676
扩展版本: https://www.zhuanzhi.ai/paper/8ee119122de9ee20679ec23ce65b230b
代码链接: https://github.com/Sense-X/UniFormer
UniFormer 性能提升
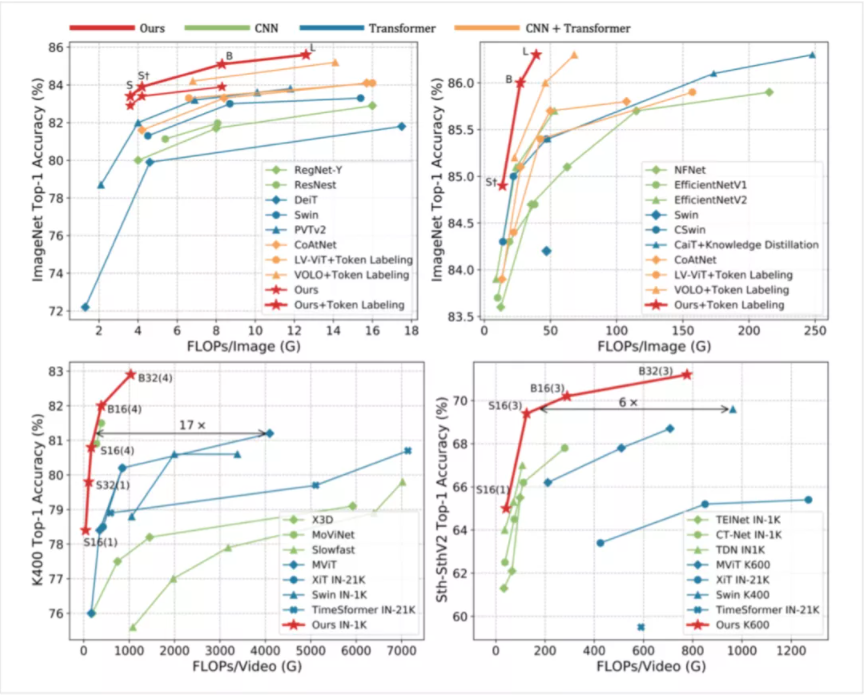
1、图像分类:在 Token Labeling 的加持下,仅靠 ImageNet-1K 训练,39GFLOPs 的 UniFormer-L-384 在 ImageNet 上实现了 86.3% 的 top-1 精度。
2、视频分类:仅用 ImageNet-1K 预训练,UniFormer-B 在 Kinetics-400 和 Kinetics-600 上分别取得了 82.9% 和 84.8% 的 top-1 精度(比使用 JFT-300M 预训练,相近性能的 ViViT 的 GFLOPs 少 16 倍)。在 Something-Something V1 和 V2 上分别取得 60.9%和 71.2% 的 top-1 精度,为同期模型的 SOTA。
3、密集预测:仅用 ImageNet-1K 预训练,COCO 目标检测任务上取得了 53.8 的 box AP 与 46.4 的 mask AP;ADE20K 语义分割任务上取得了 50.8 的 mIoU;COCO 姿态估计任务上取得了 77.4 的 AP。后文将会介绍为下游任务设计的训练和测试时模型适配。
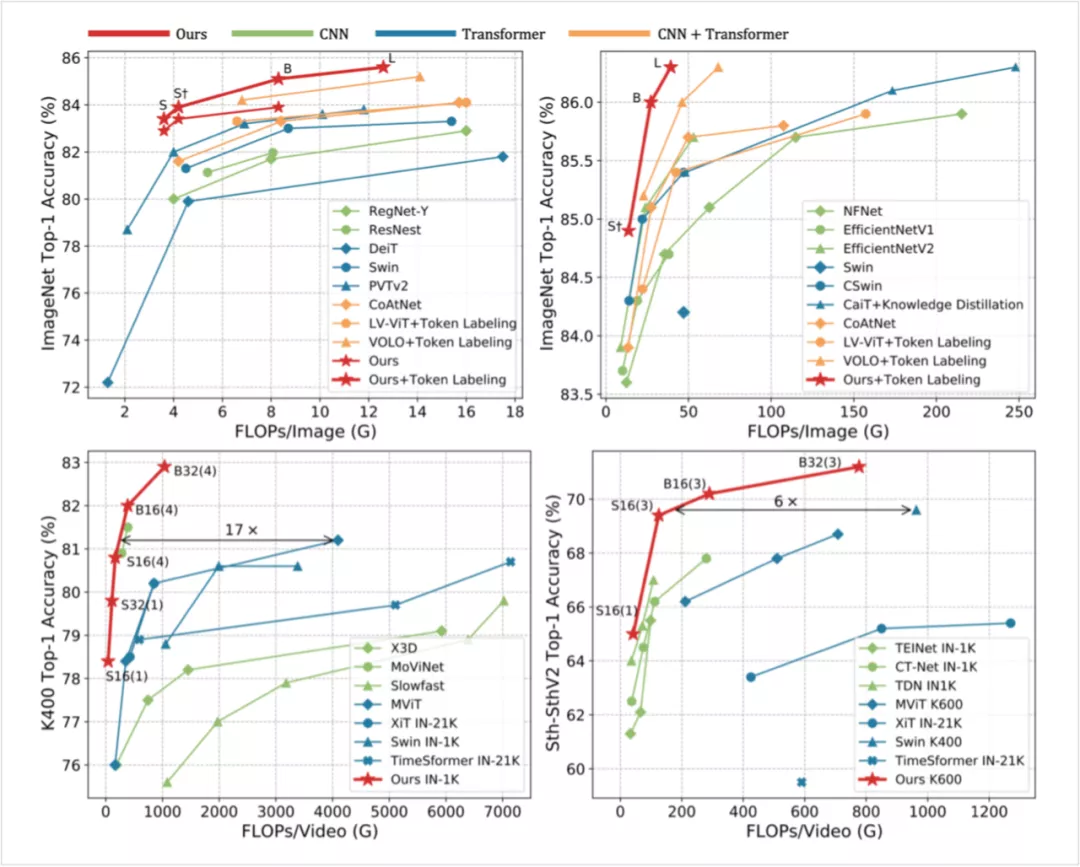
图1:图像分类与视频分类任务性能比较(上方为 ImageNet 上 224x224 与 384x384 分辨率输入)
设计灵感
对图像和视频上的 representation learning 而言,目前存在两大痛点: • Local Redundancy: 视觉数据在局部空间/时间/时空邻域具有相似性,这种局部性质容易引入大量低效的计算。
• Global Dependency: 要实现准确的识别,需要动态地将不同区域中的目标关联,建模长时依赖。
现有的两大主流模型 CNN 和 ViT,往往只关注解决以上部分问题。Convolution 只在局部小邻域聚合上下文,天然地避免了冗余的全局计算,但受限的感受也难以建模全局依赖。而 self-attention 通过比较全局相似度,自然将长距离目标关联,但通过如下可视化可以发现,ViT 在浅层编码局部特征十分低效。
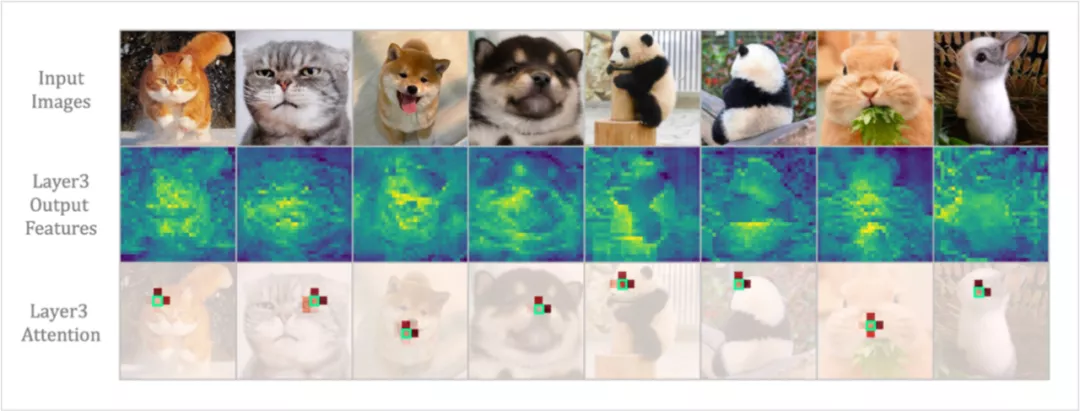
图2:DeiT 可视化后,可以发现即便经过三层 self-attention,输出特征仍保留了较多的局部细节。任选一个 token 作为 query,可视化 attention 矩阵可以发现,被关注的 token 集中在 3x3 邻域中(红色越深表示关注越多)

图3:TimeSformer 可视化后,同样可以发现即便是经过三层 self-attention,输出的每一帧特征仍保留了较多的局部细节。任选一个 token 作为 query,可视化 spatial attention 和 temporal attention 矩阵都可以发现,被关注的 token 都只在局部邻域中(红色越深表示关注越多)。 无论是 spatial attention 抑或是 temporal attention,在 ViT 的浅层,都仅会倾向于关注 query token 的邻近 token。但是 attention 矩阵是通过全局 token 相似度计算得到的,这无疑带来了大量不必要的计算。相较而言,convolution 在提取这些浅层特征时,无论是在效果上还是计算量上都具有显著的优势。那么为何不针对网络不同层特征的差异,设计不同的特征学习算子,从而将 convolution 和 self-attention 有机地结合物尽其用呢? 本论文中提出的UniFormer (Unified transFormer),旨在以 Transformer 的风格,有机地统一 convolution 和 self-attention,发挥二者的优势,同时解决 local redundancy 和 global dependency 两大问题,从而实现高效的特征学习。