

近期提出的诸多Vision Transformer (ViT) 模型在各种计算机视觉任务中展示了令人鼓舞的结果,这要归功于它们可以通过自注意力对图像块或标记的远程依赖关系进行建模。然而,这些模型通常为每一层内每个标记特征指定相似的感受野。这种做法不可避免地限制了每个自注意力层捕获多尺度特征的能力,从而导致在处理具有不同尺度多对象的图像时性能下降。为了解决这个问题,本文提出了一种新颖的通用策略,称为分流自我注意 (SSA),它允许 ViT 在每个自注意力层的混合尺度上对感受野进行抽象建模。SSA 的关键思想是将异构感受野的大小注入到Token中,在计算自注意力权重之前选择性地合并Token以得到更大尺度的对象特征,同时保留部分Token细粒度的特征。这种新颖的合并方案使自注意力层能够学习不同尺度大小对象之间的关系,同时减少Token数量和计算成本。各种任务的广泛实验证明了 SSA 的优越性。具体来说,基于 SSA 的 Transformer 实现了 84.0% 的 Top-1 准确率,并在 ImageNet 上以只有一半的模型大
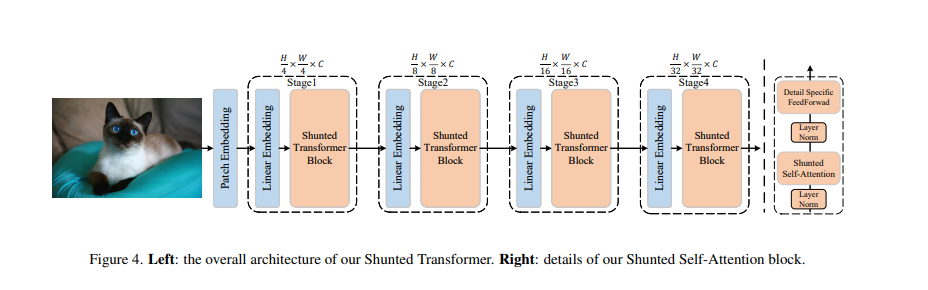
小和计算成本超过了最先进的 Focal Transformer,在 COCO 上超过了local Transformer 1.3 mAP ,在ADE20K 上取得了2.9 mIOU的性能提升。
https://www.zhuanzhi.ai/paper/ab30facc56c74d663d26c07283b044ee
成为VIP会员查看完整内容
相关内容


相关VIP内容
相关资讯
相关论文