本文介绍的是中科院深圳先进技术研究院、商汤和上海 AI Lab 的研究者合作完成的 UniFormer,包括 ICLR 2022 接收的视频 backbone,以及为下游密集预测任务设计的拓展版本,在各种任务上都能取得相较流行 SOTA 模型更好的性能。代码、模型、日志以及训练脚本都已开源。。
![]()
论文 V1 地址:https://arxiv.org/pdf/2201.04676.pdf
论文 V2 地址:https://arxiv.org/pdf/2201.09450.pdf
项目地址:https://github.com/Sense-X/UniFormer
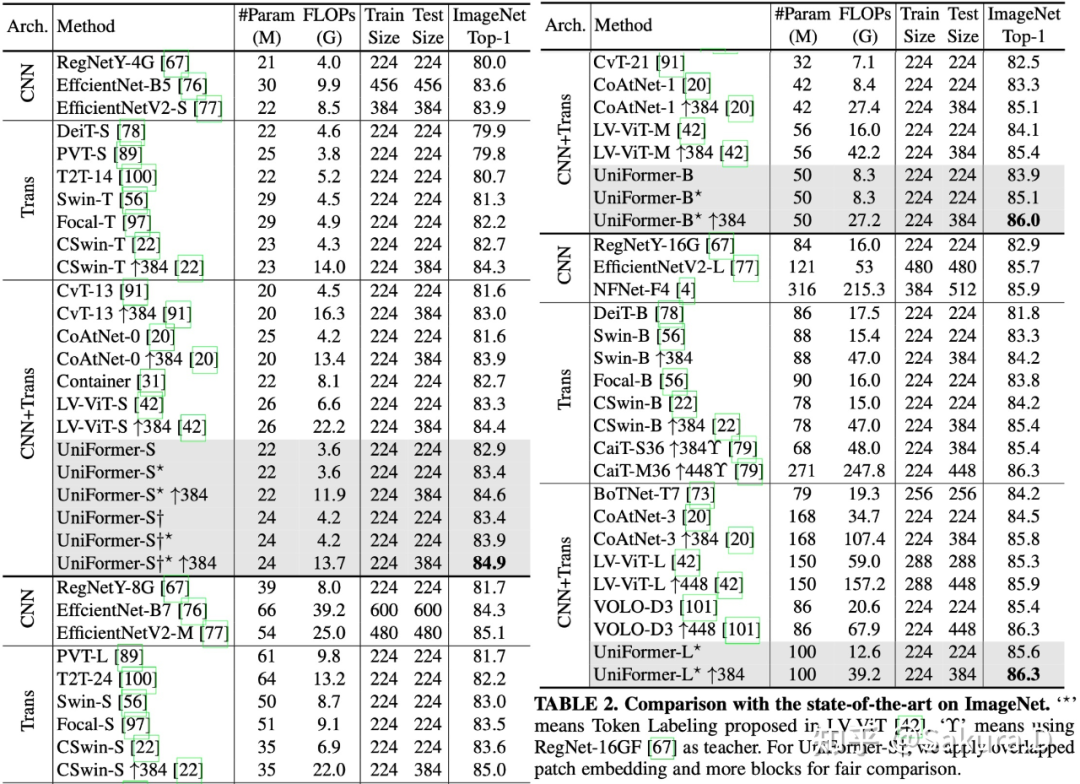
图像分类:在 Token Labeling [1] 的加持下,仅靠 ImageNet-1K 训练,39G 的 UniFormer-L-384 在 ImageNet 上实现 86.3% 的 top-1 精度;
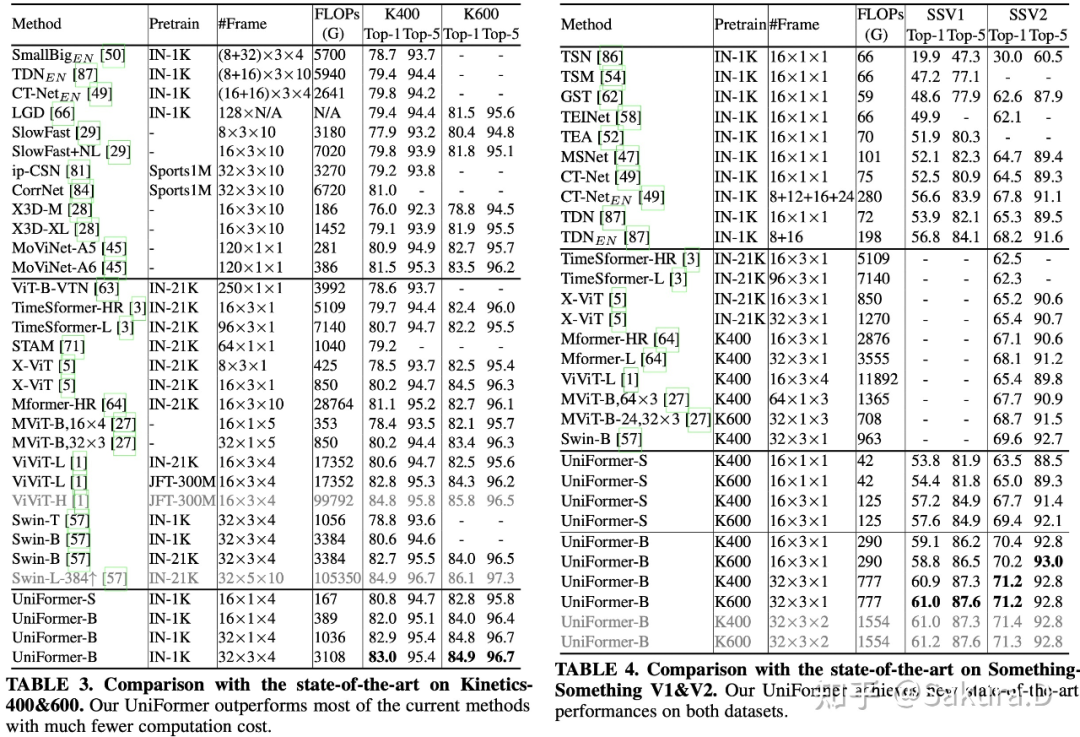
视频分类:仅用 ImageNet-1K 预训练,UniFormer-B 在 Kinetics-400 和 Kinetics-600 上分别取得了 82.9% 和 84.8% 的 top-1 精度(比使用 JFT-300M 预训练,相近性能的 ViViT [2] 的 GFLOPs 少 16 倍)。在 Something-Something V1 和 V2 上分别取得 60.9% 和 71.2% 的 top-1 精度,为同期模型的 SOTA;
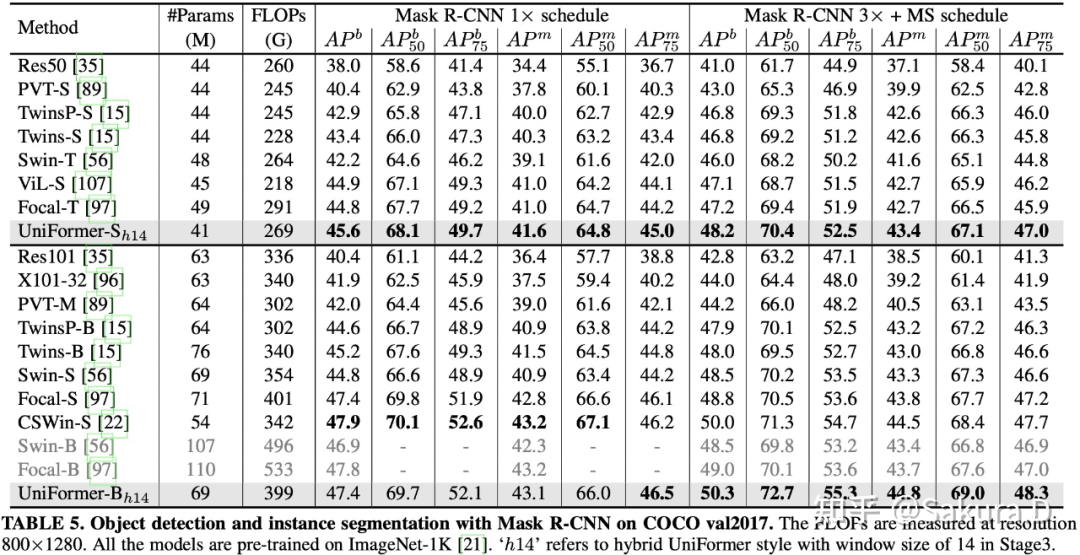
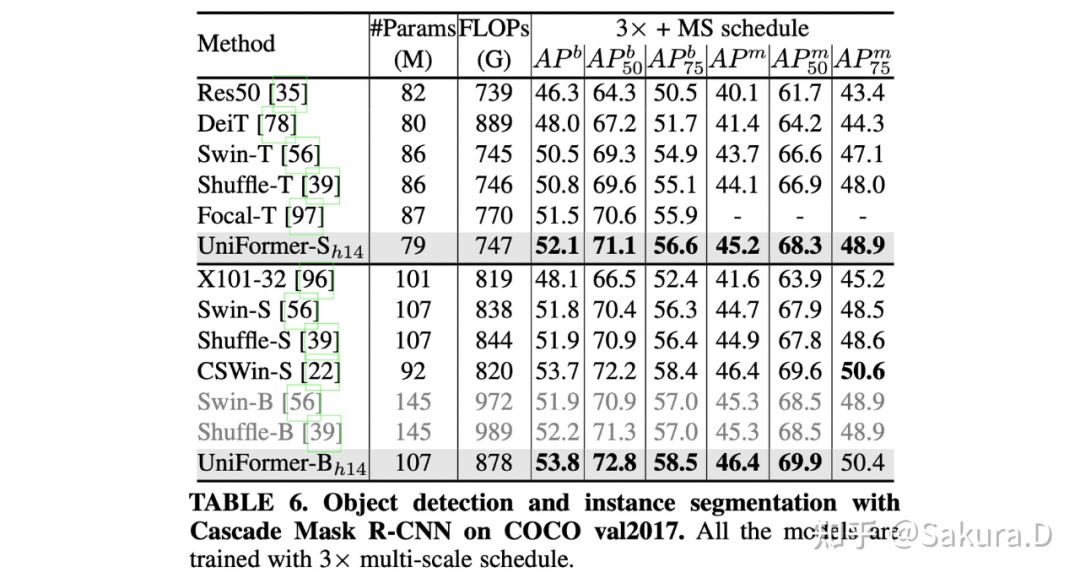
密集预测:仅用 ImageNet-1K 预训练,COCO 目标检测任务上取得 53.8 的 box AP 与 46.4 的 mask AP;ADE20K 予以分割任务上取得 50.8 的 mIoU;COCO 姿态估计任务上取得 77.4 的 AP。后面会介绍为下游任务设计的,训练和测试时模型适配。
![]()
图像分类与视频分类任务性能比较(上方为 ImageNet 上 224x224 与 384x384 分辨率输入)
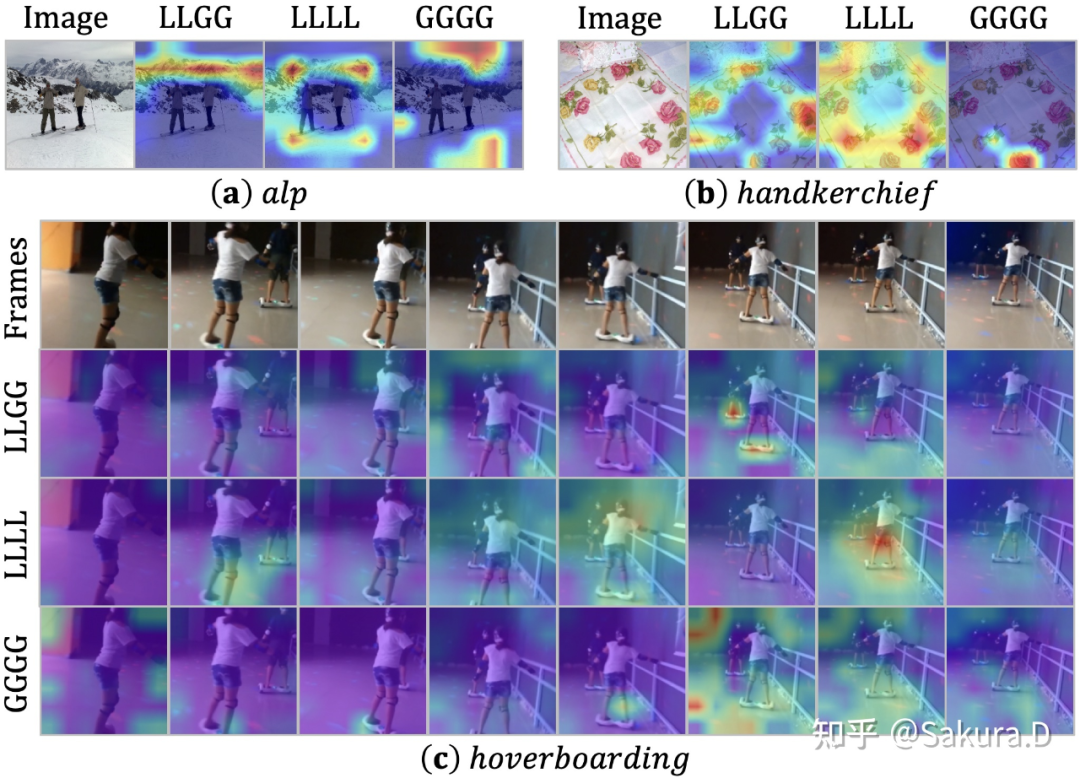
现有的两大主流模型 CNN 和 ViT,往往只关注解决问题之一。卷积只在局部小邻域聚合上下文,天然地避免了冗余的全局计算,但受限的感受野难以建模全局依赖。而自注意力通过比较全局相似度,自然将长距离目标关联,但如下可视化可以发现,ViT 在浅层编码局部特征十分低效。
DeiT 可视化,可以看到即便是经过了三层的自注意力,输出特征仍保留了较多的局部细节。我们任选一个 token 作为查询,可视化注意力矩阵可以发现,被关注的 token 集中在 3x3 邻域中(红色越深关注越多)。
![]()
TimeSformer 可视化,同样可以看到即便是经过了三层的自注意力,输出的每一帧特征仍保留了较多的局部细节。我们任选一个 token 作为查询,可视化空间注意力和时序注意力矩阵都可以发现,被关注的 token 都只在局部邻域中(红色越深关注越多)。
无论是空间注意力抑或时序注意力,在 ViT 的浅层,都仅会倾向于关注查询 token 的邻近 token。要知道注意力矩阵是通过全局 token 相似度计算得到的,这无疑带来了大量不必要的计算。相较而言,卷积在提取这些浅层特征时,无论是在效果上还是计算量上都具有显著的优势。那么为何不针对网络不同层特征的差异,设计不同的特征学习算子,将卷积和自注意力有机地结合物尽其用呢?
本文的 UniFormer (Unified transFormer),旨在
以 Transformer 的风格,有机地统一卷积和自注意力,发挥二者的优势,同时解决局部冗余和全局依赖两大问题,实现高效的特征学习
。
![]()
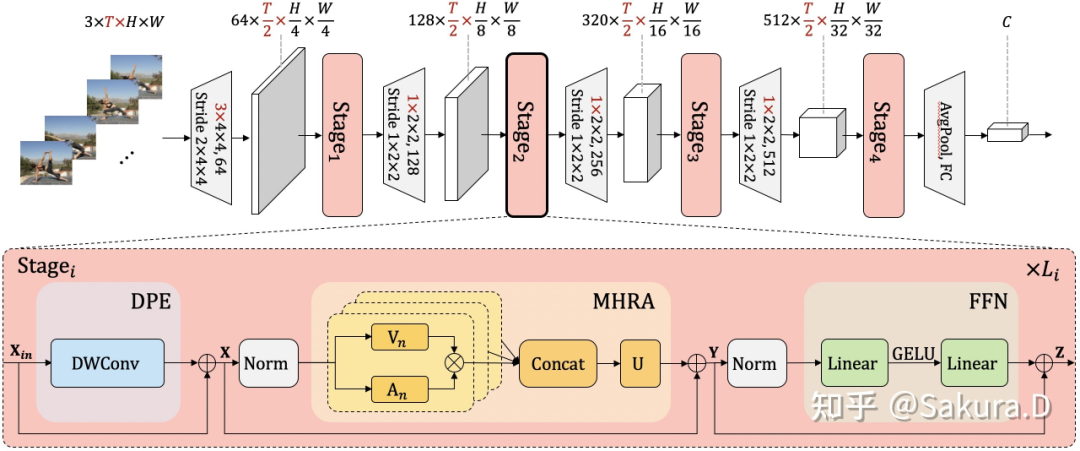
模型整体框架,标红维度仅对视频输入作用,对图像输入都可视作 1。
模型整体框架如上所示,借鉴了 CNN 的层次化设计,每层包含多个 Transformer 风格的 UniFormer block。
![]()
每个 UniFormer block 主要由三部分组成,动态位置编码 DPE、多头关系聚合器 MHRA 以及 Transformer 必备的前馈层 FFN,其中最关键的为多头关系聚合器:
![]()
与多头注意力相似,我们将关系聚合器设计为多头风格,每个头单独处理一组 channel 的信息。每组的 channel 先通过线性变换生成上下文 token
![]() ,然后在 token affinity
,然后在 token affinity
![]() 的作用下,对上下文进行有机聚合。
基于前面的可视化观察,研究者认为在网络的浅层,token affinity 应该仅关注局部邻域上下文,这与卷积的设计不谋而合。因此,他们将局部关系聚合
的作用下,对上下文进行有机聚合。
基于前面的可视化观察,研究者认为在网络的浅层,token affinity 应该仅关注局部邻域上下文,这与卷积的设计不谋而合。因此,他们将局部关系聚合
![]() 设计为可学的参数矩阵:
设计为可学的参数矩阵:
![]()
其中
![]() 为 anchor token,
为 anchor token,
![]() 为局部邻域
为局部邻域
![]() 任一 token,
任一 token,
![]() 为可学参数矩阵,
为可学参数矩阵,
![]() 为二者相对位置,表明 token affinity 的值只与相对位置有关。这样一来,local UniFormer block 实际与 MobileNet block [3] 的风格相似,都是 PWConv-DWConv-PWConv(见原论文解析),
不同的是研究者引入额外的位置编码以前前馈层,这种特别的结合形式有效地增强了 token 的特征表达
。
在网络的深层,研究者需要对整个特征空间建立长时关系,这与自注意力的思想一致,因此通过比较全局上下文相似度建立 token affinity:
为二者相对位置,表明 token affinity 的值只与相对位置有关。这样一来,local UniFormer block 实际与 MobileNet block [3] 的风格相似,都是 PWConv-DWConv-PWConv(见原论文解析),
不同的是研究者引入额外的位置编码以前前馈层,这种特别的结合形式有效地增强了 token 的特征表达
。
在网络的深层,研究者需要对整个特征空间建立长时关系,这与自注意力的思想一致,因此通过比较全局上下文相似度建立 token affinity:
![]()
其中
![]() 为不同的线性变换。
先前的视频 transformer 往往采用时空分离的注意力机制 [4],以减少视频输入带来的过量点积运算,但这种分离的操作无疑割裂了 token 的时空关联。
相反,UniFormer 在网络的浅层采用 local MHRA,节省了冗余计算量,使得网络在深层可以轻松使用联合时空注意力,从而可以得到更具辨别性的视频特征表达。
再者,与以往 ViT 中使用绝对位置编码不同,这里采用卷积风格的动态位置编码,使得网络可以克服排列不变形(permutation-invariance)的同时,对不同长度的输入更友好。
流行的 ViT 往往采用绝对或者相对位置编码 [5],但绝对位置编码在面对更大分辨率的输入时,需要进行线性插值以及额外的参数微调,而相对位置编码对自注意力的形式进行了修改。为了适配不同分辨率输入的需要,研究者采用了最近流行的卷积位置编码 [6] 设计动态位置编码:
为不同的线性变换。
先前的视频 transformer 往往采用时空分离的注意力机制 [4],以减少视频输入带来的过量点积运算,但这种分离的操作无疑割裂了 token 的时空关联。
相反,UniFormer 在网络的浅层采用 local MHRA,节省了冗余计算量,使得网络在深层可以轻松使用联合时空注意力,从而可以得到更具辨别性的视频特征表达。
再者,与以往 ViT 中使用绝对位置编码不同,这里采用卷积风格的动态位置编码,使得网络可以克服排列不变形(permutation-invariance)的同时,对不同长度的输入更友好。
流行的 ViT 往往采用绝对或者相对位置编码 [5],但绝对位置编码在面对更大分辨率的输入时,需要进行线性插值以及额外的参数微调,而相对位置编码对自注意力的形式进行了修改。为了适配不同分辨率输入的需要,研究者采用了最近流行的卷积位置编码 [6] 设计动态位置编码:
![]()
其中 DWConv 为零填充的的深度可分离卷积。一方面,卷积对任何输入形式都很友好,也很容易拓展到空间维度统一编码时空位置信息。另一方面,深度可分离卷积十分轻量,额外的零填充可以帮助每个 token 确定自己的绝对位置。
![]()
研究者设计了三种不同规模的模型,每个模型包含 4 层,前两层使用 local MHRA,后两层使用 global MHRA。对于 local MHRA,卷积核大小为 5x5,归一化使用 BN(使用 LN 性能较差)。对于 global MHRA,每个 head 的 channel 数为 64,归一化使用 LN。动态位置编码卷积核大小为 3x3,FFN 的拓展倍数为 4。
对于特征下采样,研究者采用非重叠卷积,其中第一次下采样卷积核大小为 4x4、步长为 4x4,其余三次下采样卷积核大小为 2x2、步长为 2x2。在每次下采样卷积之后,他们额外增加 LN 归一化。网络最后接平均池化层与线性分类层,输出最终预测。当使用 Token Labeling 时,研究者额外加入一个线性分类层以及辅助损失函数。
对于 UniFormer-S,研究者设计了增强版本,每层 block 数量为 [3, 5, 9, 3],下采样使用重叠卷积,FLOPs 控制为 4.2G,保证与其他 SOTA 模型可比。
对于视频使用的 3D backbone,研究者加载 ImageNet-1K 预训练的 UniFormer-S 和 UniFormer-B,并进行卷积核展开。具体地,动态位置编码和 local MHRA 分别展开为 3x3x3 和 5x5x5 卷积。对于下采样层,他们只在第一次下采样同时压缩时间和空间维度,而在其余三次下采样仅压缩空间维度,也即是第一次下采样卷积核大小为 3x4x4、步长为 2x4x4,其余卷积核大小为 1x2x2、步长为 1x2x2。这样可以减少计算量的同时,保证模型的高性能。对于 global MHRA,研究者直接继承相应参数,将时空 token 序列化进行统一处理。
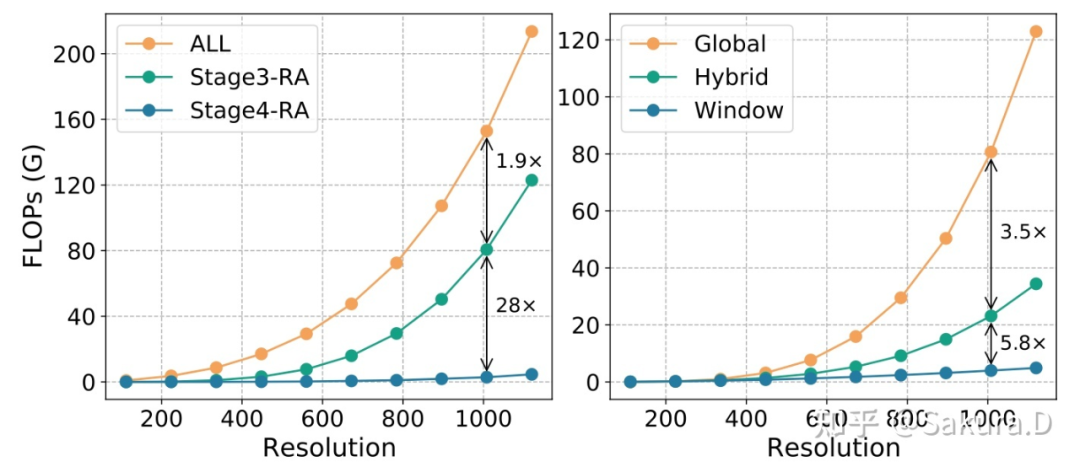
对于下游密集预测任务,直接使用原始网络作为主干并不合适。因为这些任务往往输入大分辨率图像,比如目标检测中输入 1333x800 的图像,使用 global MHRA 会带来过多的计算量。研究者以 UniFormer-S 为例,统计不同分辨率输入下,不同操作所需的计算量。
![]()
左:模型整体计算量与第三 / 四层中 MatMul 运算所需计算量。右:第三层采用不同风格的 MHRA 所需的 MatMul 计算量。
从上图中可以看到,第三层中 MHRA 所需的 MatMul 运算随着分辨率的增加急剧上升,在输入分辨率为 1008x1008 时,甚至占了总运算量 50% 以上,而第四层仅为第三层的 1/28。因此,研究者仅对第三层的 MHRA 进行改进。
受先前工作 [7] 的启发,他们将 global MHRA 应用在限制的窗口内,这样会把原本
![]() 的复杂度降至
的复杂度降至
![]() ,其中 p 为窗口大小。
然而直接应用纯 window 化操作,不可避免地会带来性能下降,为此研究者将 window 和 global 操作结合。
每个 hybrid 分组中包含 4 个 block,前 3 个为 window block,最后 1 个为 global block。
UniFormer-S 和 UniFormer-B 分别包含 2 个和 5 个分组。
,其中 p 为窗口大小。
然而直接应用纯 window 化操作,不可避免地会带来性能下降,为此研究者将 window 和 global 操作结合。
每个 hybrid 分组中包含 4 个 block,前 3 个为 window block,最后 1 个为 global block。
UniFormer-S 和 UniFormer-B 分别包含 2 个和 5 个分组。
![]()
如上为研究者在五种任务上,训练和测试采用的特定改进。对于目标检测任务,由于训练和测试时输入分辨率都很大(如 1333x800),他们在第三层都采用 hybrid block。对姿态估计任务,输入分辨率相对较小(如 384x288),在第三层采用原本的 gloabl block。
而对于语义分割任务,往往在测试时使用几倍于训练输入的分辨率(如 2048x512 vs. 512x512),因此在训练时,对第三层采用 global block,而在测试时采用 hybrid block,但需要注意测试时 hybrid block 中 window size 需要与训练时 global block 的感受野一致(如 32x32),感受野不一致会导致急剧性能下降。这种设计可以保证训练高效的同时,提高测试的性能。
研究者在 ImageNet-1K 进行图像分类实验,采用了 DeiT [8] 的代码与训练策略,UniFormer-S/B/L 使用 droppath 比例为 0.1/0.3/0.4,对大模型额外加入 Layer Scale 防止网络训练崩溃 [9]。对于 Token Labeling,沿用其代码训练框架与超参。
![]()
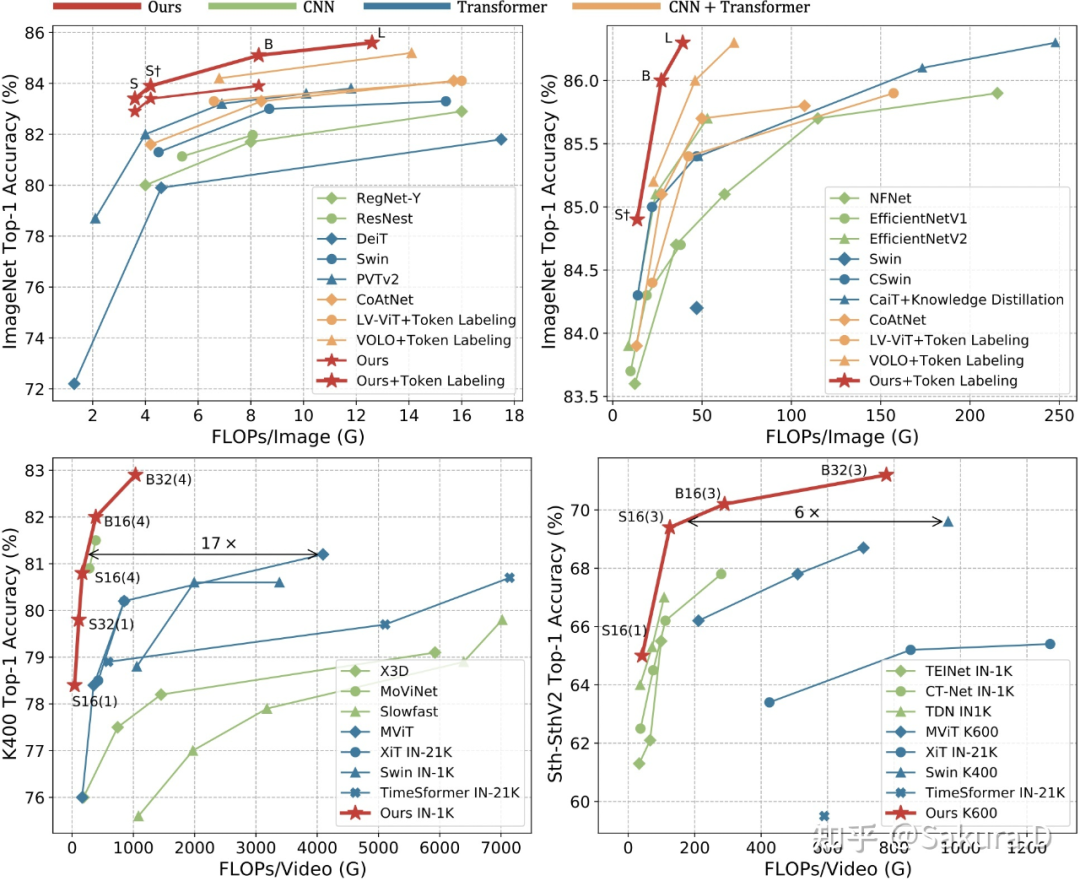
结果如上所示,其中带 * 为加入 Token Labaleing 进行训练,UniFormer-B 为前述 UniFormer-B 的增强版本。从中可以看到 UniFormer 在不同规模下都取得了 SOTA 性能,UniFormer-L-384 仅需 39G 的 FLOPs,即可取得 86.3% 的 top-1 精度。
研究者在 Kinetics-400/600 以及 Something-Something V1/V2 上进行了视频分类实验,沿用 MViT 的代码和训练策略。对 Kinetics 采用 dense 采样方式,加载了 ImageNet-1K 的预训练模型加速训练,droppath 比例保持与前述一致。对 Sth-Sth 采用 uniform 采样方式,加载了 Kinetics 的预训练,droppath 设置为前述两倍,并不进行水平翻转。
![]()
结果如上图所示,仅使用 ImageNet-1K 预训练,研究者在 Kinetics 上取得与使用 JFT-300M 预训练的 ViViT-L、使用 ImageNet-21K 预训练的 Swin-B 相近的性能,计算量大幅减小。而在 Sth-Sth 上,大幅高于先前 CNN 和 ViT 的结果,取得了新的 SOTA,在 Sth-Sth V1 上 61.2%,V2 上 71.4%。
研究者在 COCO2017 上进行了目标检测和实例分割实验,沿用了 mmdetection [10] 的代码框架,配置了 Mask R-CNN 与 Cascade Mask R-CNN 框架,使用 Swin Transformer 的训练参数,均取得了 SOTA 性能。
![]()
![]()
COCO 目标检测,Cascade Mask R-CNN
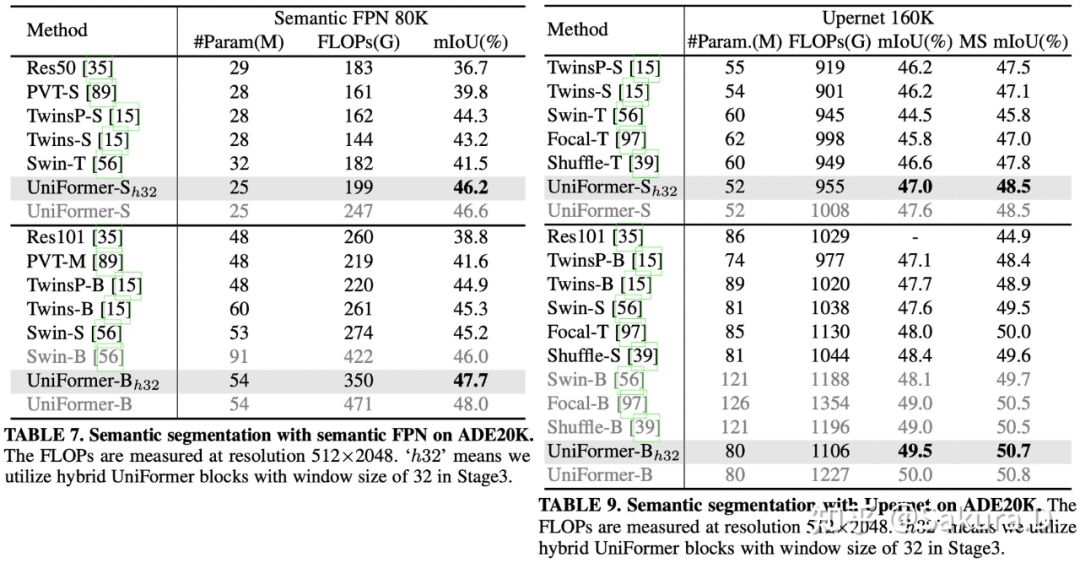
研究者在 ADE20K 上进行了语义分割实验,沿用了 mmsegmentation [11] 的代码框架,配置了 Semantic FPN 与 UperNet 两种框架,分别使用了 PVT 和 Swin 的训练参数,均取得了 SOTA 性能。
![]()
ADE20K 语义分割,左:Semantic FPN。右:UperNet。
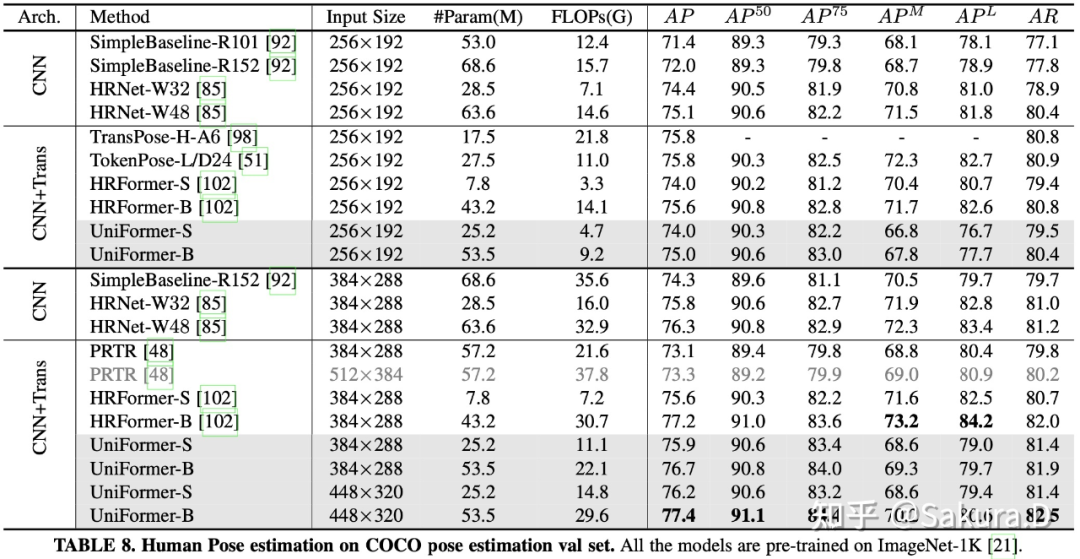
研究者在 COCO2017 上进行了姿态估计实验,沿用了 mmpose [12] 的代码框架,配置了简单的 Top-down 框架,使用了 HRFormer 的训练参数,取得了 SOTA 性能。
![]()
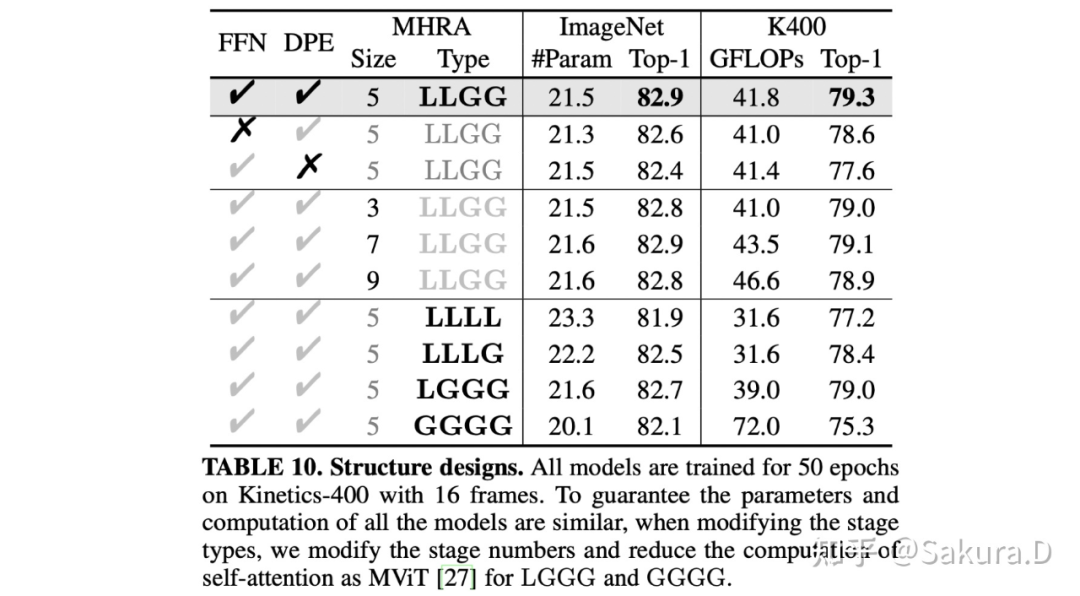
研究者进行了详尽的消融实验,首先在图像和视频分类任务上验证了 backbone 的结构设计。其次,他们对视频 backbone 的预训练、训练以及测试策略进行了探究。最后,我们验证了下游密集预测任务上改进的有效性。
![]()
FFN:首先将 local block 替换为 MobileNet block,其中 ReLU 替换为 GeLU,expand ration 设置为 3 保持计算量一致,保留动态编码以公平比较,可以看到 local block 在图像和视频分类任务上都要明显优于 MobileNet block。由此可知 transformer 风格,以及其特有的 FFN 确实增强了 token 的特征表达;
DPE:将动态位置编码去掉,在图像和视频任务上性能均下降,视频任务上更是掉了 1.7%,由此可知位置编码有助于更好的时空特征学习;
Local MHRA size:将 local MHRA 的卷积核大小设置为 3、5、7、9,性能差异并不大,最终采用大小为 5 的卷积核,以取得最好的计算量与准确率的权衡;
MHRA configuration:由纯 local MHRA(LLLL)出发,逐层替换使用 global MHRA。结果可以发现,仅使用 local MHRA 时,计算量很小,但性能下降明显。逐层替换 global MHRA 后,性能逐渐提升。但全部替换为 global MHRA 后,视频分类准确率急剧下降,计算量急剧上升,这主要是因为网络缺失了提取细节特征的能力,冗余的 attention 在有限的 video 数据下导致了急剧的过拟合。
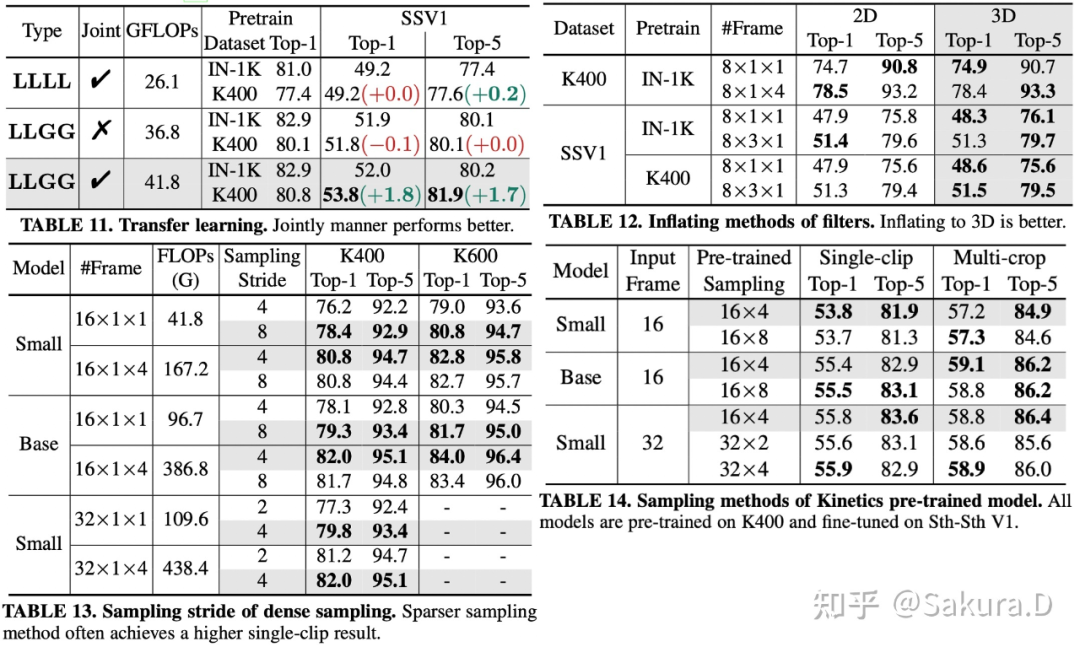
![]()
Transfer learning:表 11 中比较了不同结构的预训练性能以及小数据集上的迁移学习性能,可以发现,联合的时空学习方式,不仅在预训练模型上性能更好,在小数据集上的迁移学习性能提升明显。而纯 local MHRA 以及时空分离的学习方式,迁移小数据训练未能带来提升;
Infalting methods:表 12 中比较了是否对卷积核进行展开,可以发现,展开为 3D 卷积核,在场景相关的数据集 Kinetics-400 上性能接近,但在时序相关的数据集 Sth-Sth V1 上提升明显,尤其是在强与训练的加持下,这表明 3D 卷积核对时空特征的学习能力更强;
Sampling strides of dense sampling:表 13 中比较了研究者在训练 Kinetics 时,使用不同间隔采样的结果。可以发现更稀疏的采样,在单 clip 测试上效果往往更好,但在多 clip 测试时,间隔 4 帧采样更好;
Sampling methods of Kinetics pre-trained model:由于加载 Kinetics 预训练模型训练 Sth-Sth,而 Sth-Sth 采用 uniform 采样,有必要知道预训练覆盖更多帧是否能带来提升。表 14 的结果表明,预训练的不同采样方式差别并不大,16x4 采样在大部分条件下性能都较好。
![]()
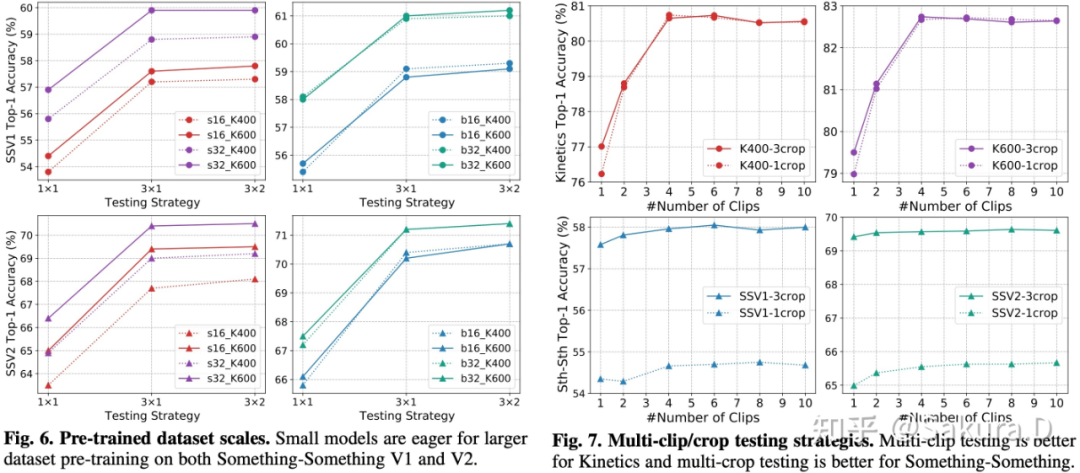
Pre-trained dataset scales:图 6 比较了不同规模数据预训练的结果,可以发现对于小模型,大数据集预训练的提升非常明显,而对于大模型则相差无几;
Testing strategies:图 7 比较了不同的测试策略,可以发现对于使用 dense 采样方式训练的场景相关数据集 Kinetics 而言,多 clip 测试方案较好,且 1x4 综合性能最优。对于使用 uniform 采样方式训练的时序相关数据集 Sth-Sth 而言,多 crop 测试方案较好,且 3x1 综合性能最好。
![]()
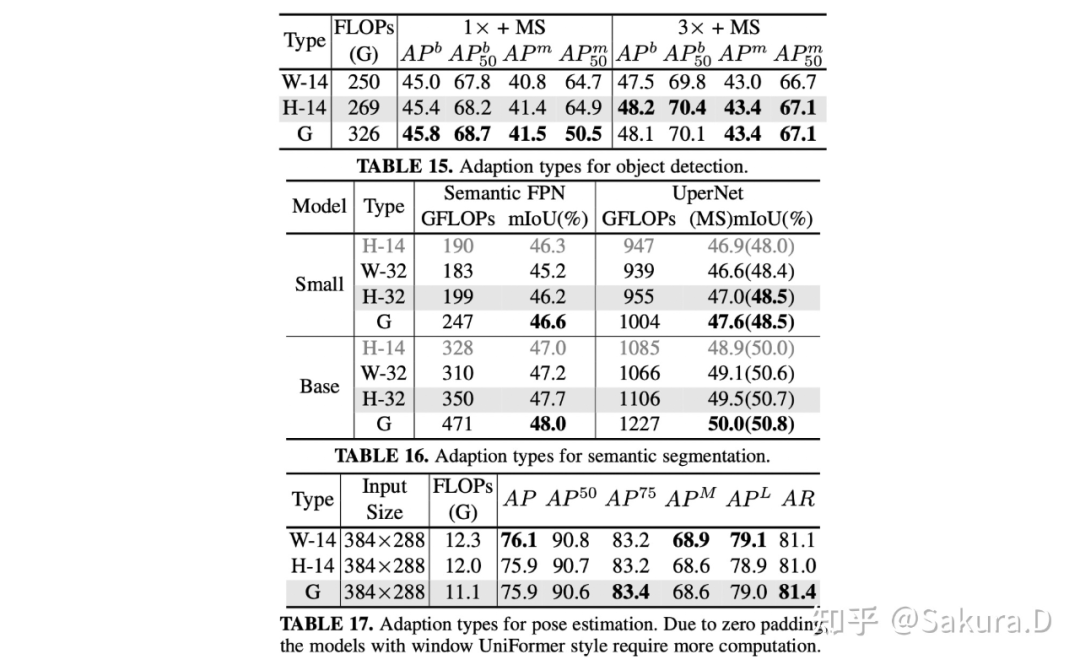
目标检测:表 15 比较了目标检测任务上,第三层采用不同类型 block 的结果。尽管在 1x 训练时,hybrid block 的性能比纯 global block 性能略差,但经过 3x 的充分训练后,hybrid block 的性能已经能和纯 global block 持平;
语义分割:表 16 比较了了语义分割任务上,第三层采用不同类型 block 的结果。可以发现更大的窗口大小,以及 global block 的使用都能明显提升性能,由于纯 global block 计算量较大,我们采用性能相近的 hybrid block;
姿态估计:表 17 分别比较了姿态估计任务上,第三层采用不同类型 block 的结果。由于图像分辨率较小,zero padding 消耗了更多的计算量。
![]()
![]()
过去一年多,研究者在视频模型设计上尝试了 CNN(CTNet,ICLR2021)、ViT(UniFormer,ICLR2022)以及 MLP(MorphMLP,arxiv)三大主流架构。总的来说,Transformer 风格的模块 + CNN 的层次化架构 + convolution 的局部建模 + DeiT 强大的训练策略,保证了模型的下限不会太低。但相比卷积以及线性层而言,自注意力的性价比仍是最高的,同等计算量尤其是小模型下,自注意力带来的性能提升明显,并且对大数据集预训练的迁移效果更好。
但传统 ViT 对不同分辨率输入并不友好,并且对大分辨率输入的计算量难以承受,这在 UniFormer 中都尽可能以简洁的方式解决,DWConv 有限制地引入,也并不会导致过多的显存开销与速度延迟,最后在不同的任务上都能取得很好地性能权衡。
本文 UniFormer 提供了一个尽可能简单的框架,研究者也希望后面的工作能在这个框架的基础上,去考虑视频中的运动信息、时空维度的冗余性、帧间的长时关系建模等等更复杂的问题,实现更大的突破。
1. Token Labeling https://github.com/zihangJiang/TokenLabeling
2. ViViT https://arxiv.org/abs/2103.15691
3. MobileNetV2 https://arxiv.org/abs/1801.04381
4. TimeSformer https://arxiv.org/abs/2102.05095
5. Swin Transformer https://arxiv.org/abs/2103.14030
6. CPE https://arxiv.org/abs/2102.10882
7. stand-alone https://arxiv.org/abs/1906.05909
8. DeiT https://github.com/facebookresearch/deit
9. Layer Scale https://arxiv.org/abs/2103.17239
10. mmdetection https://github.com/open-mmlab/mmdetection
11. mmsegmentation https://github.com/open-mmlab/mmsegmentation
12. mmpose https://github.com/open-mmlab/mmpose
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com



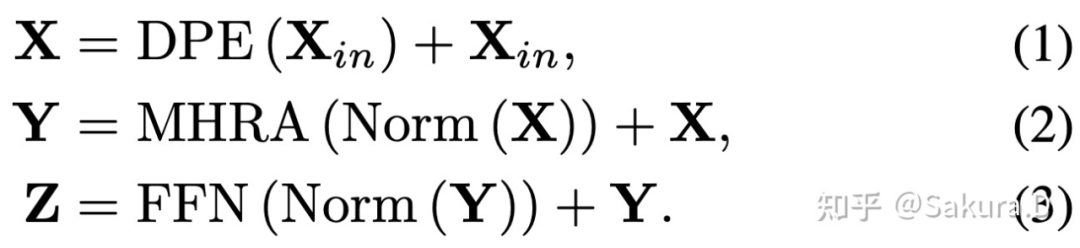
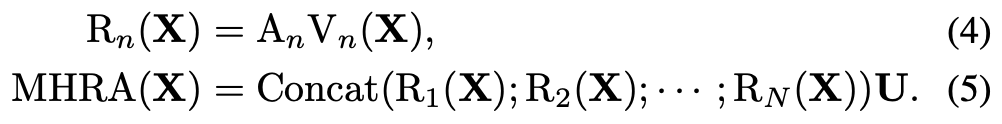
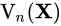 ,然后在 token affinity
,然后在 token affinity
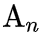 的作用下,对上下文进行有机聚合。
的作用下,对上下文进行有机聚合。
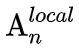 设计为可学的参数矩阵:
设计为可学的参数矩阵:
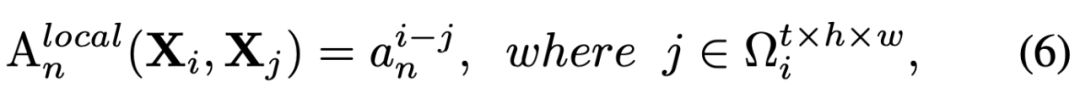
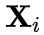 为 anchor token,
为 anchor token,
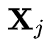 为局部邻域
为局部邻域
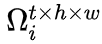 任一 token,
任一 token,
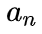 为可学参数矩阵,
为可学参数矩阵,
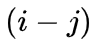 为二者相对位置,表明 token affinity 的值只与相对位置有关。这样一来,local UniFormer block 实际与 MobileNet block [3] 的风格相似,都是 PWConv-DWConv-PWConv(见原论文解析),
不同的是研究者引入额外的位置编码以前前馈层,这种特别的结合形式有效地增强了 token 的特征表达
。
为二者相对位置,表明 token affinity 的值只与相对位置有关。这样一来,local UniFormer block 实际与 MobileNet block [3] 的风格相似,都是 PWConv-DWConv-PWConv(见原论文解析),
不同的是研究者引入额外的位置编码以前前馈层,这种特别的结合形式有效地增强了 token 的特征表达
。
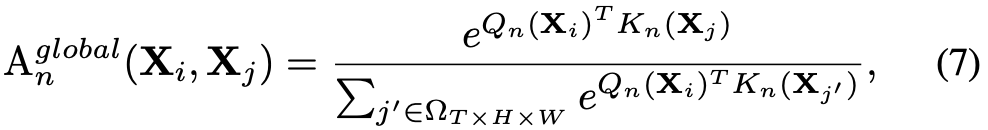
 为不同的线性变换。
先前的视频 transformer 往往采用时空分离的注意力机制 [4],以减少视频输入带来的过量点积运算,但这种分离的操作无疑割裂了 token 的时空关联。
相反,UniFormer 在网络的浅层采用 local MHRA,节省了冗余计算量,使得网络在深层可以轻松使用联合时空注意力,从而可以得到更具辨别性的视频特征表达。
再者,与以往 ViT 中使用绝对位置编码不同,这里采用卷积风格的动态位置编码,使得网络可以克服排列不变形(permutation-invariance)的同时,对不同长度的输入更友好。
为不同的线性变换。
先前的视频 transformer 往往采用时空分离的注意力机制 [4],以减少视频输入带来的过量点积运算,但这种分离的操作无疑割裂了 token 的时空关联。
相反,UniFormer 在网络的浅层采用 local MHRA,节省了冗余计算量,使得网络在深层可以轻松使用联合时空注意力,从而可以得到更具辨别性的视频特征表达。
再者,与以往 ViT 中使用绝对位置编码不同,这里采用卷积风格的动态位置编码,使得网络可以克服排列不变形(permutation-invariance)的同时,对不同长度的输入更友好。
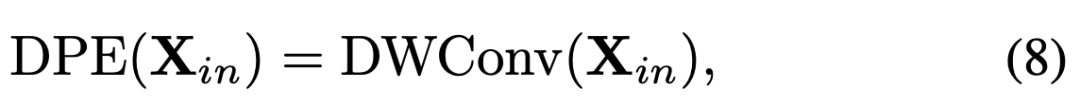

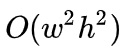 的复杂度降至
的复杂度降至
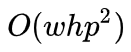 ,其中 p 为窗口大小。
然而直接应用纯 window 化操作,不可避免地会带来性能下降,为此研究者将 window 和 global 操作结合。
每个 hybrid 分组中包含 4 个 block,前 3 个为 window block,最后 1 个为 global block。
UniFormer-S 和 UniFormer-B 分别包含 2 个和 5 个分组。
,其中 p 为窗口大小。
然而直接应用纯 window 化操作,不可避免地会带来性能下降,为此研究者将 window 和 global 操作结合。
每个 hybrid 分组中包含 4 个 block,前 3 个为 window block,最后 1 个为 global block。
UniFormer-S 和 UniFormer-B 分别包含 2 个和 5 个分组。