选自arXiv
作者:Valerii Likhosherstov等
Transformers 是一个灵活的神经端到端模型族(family),最开始是为自然语言处理任务设计的。近来,Transformers 已经在图像分类、视频和音频等一系列感知任务上得到应用。虽然近来在不同领域和任务上取得了进展,但当前 SOTA 方法只能为手头的每个任务训练具有不同参数的单一模型。
近日,谷歌研究院、剑桥大学和阿兰 · 图灵研究所的几位研究者在其论文《 PolyViT: Co-training Vision Transformers on Images, Videos and Audio 》提出了一种简单高效的训练单个统一模型的方法,他们将该模型命名为 PolyViT,它实现了有竞争力或 SOTA 的图像、视频和音频分类结果。
在设计上,研究者不仅为不同的模态使用一个通用架构,还在不同的任务和模态中共享模型参数,从而实现了潜在协同作用。从技术上来讲,他们的方法受到了「transformer 是能够在任何可以 tokenized 的模态上运行的通用架构」这一事实的启发;从直觉上来讲,是由于人类感知在本质上是多模态的,并由单个大脑执行。
![]()
论文地址:https://arxiv.org/abs/2111.12993
![]()
研究者主要使用的方法是协同训练(co-training)
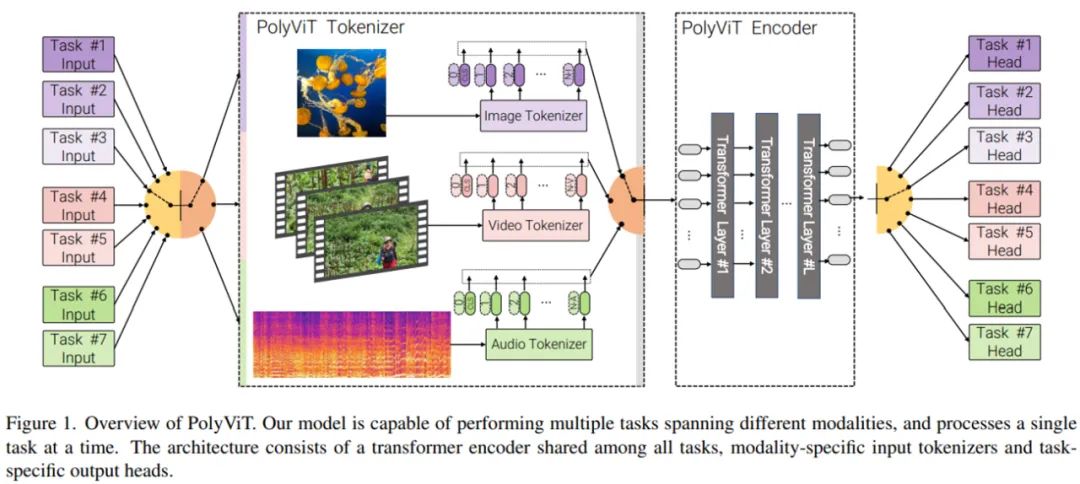
,即同时在多个分类任务(可能跨多个模态)上训练单个模型。他们考虑了不同的设置,同时解决多达 9 个不同的图像、视频和音频分类任务。如上图 1 所示,PolyViT 模型能够执行多个任务,但对于给定的输入一次只能执行一个任务。虽然计算机视觉和自然语言领域探索过类似的方法,但研究者不清楚以往的工作是否考虑了多种模态以及是否使用这种方法实现了 SOTA 结果。
我们的协同训练设置简单实用。它不需要对协同训练数据集的每个组合进行超参数调整,因为我们可以很容易地调整标准单任务训练的设置。此外,协同训练也不会增加整体训练成本,因为训练步骤的总数不超过每个单任务基线的总和。
图像、音频和视频上的 Co-training ViT
PolyViT 是一个能够处理来自多种模态的输入的单一架构。如上图 1 所示,研究者在不同的任务和模态中共享一个 transformer 编码器,使得参数随任务数量呈线性减少。注意,在处理图像时,具有 L 个层的 PolyViT 表现得像 L 层的 ViT,处理音频时表现得像 L 层的 AST,处理视频时表现得像 L 层的未因式分解(unfactorized)的 ViViT。虽然 PolyViT 能够处理多种模态,但在给定前向传递时只能基于一种模态执行一个任务。
PolyViT 部署模态特定的类 token,即
![]() 、输入嵌入算子
、输入嵌入算子
![]() 和位置嵌入
和位置嵌入
![]() 。
这使得网络可以编码模态特定的信息,这些信息又可以被随后的、共享 transformer 主干所利用。
。
这使得网络可以编码模态特定的信息,这些信息又可以被随后的、共享 transformer 主干所利用。
为了实现大量任务和模态协同训练的同时增加模型容量,研究者可以选择性地纳入 L_adapt ≥ 0 模态特定 transformer 层(他们表示为模态 - 适配器层),这些 transformer 层在 tokenization 之后直接应用。在这种情况下,所有模态和任务中会共享 L_=shared = L − L_adapt 层。
在使用随机梯度下降(SGD)协同训练的所有任务中,研究者同时优化所有的 PolyViT 模型参数 θ。因此,在决定如何构建训练 batch、计算梯度以更新模型参数以及使用哪些训练超参数时有很多设计上的选择。
在所有情况下,研究者使用来自单个任务中的示例来构建自己的训练 minibatch。这一设计选择使得他们在使用相同的训练超参数(如学习率、batch 大小和动量)作为传统单一任务基线时,可以评估梯度和更新参数。这样一来,与单一任务基线相比,研究者无需任何额外的超参数就可以执行多个任务上的协同训练,从而使得协同训练在实践中易于执行,并减少执行大规模超参数扫描(sweep)的需求以实现具有竞争力的准确性。
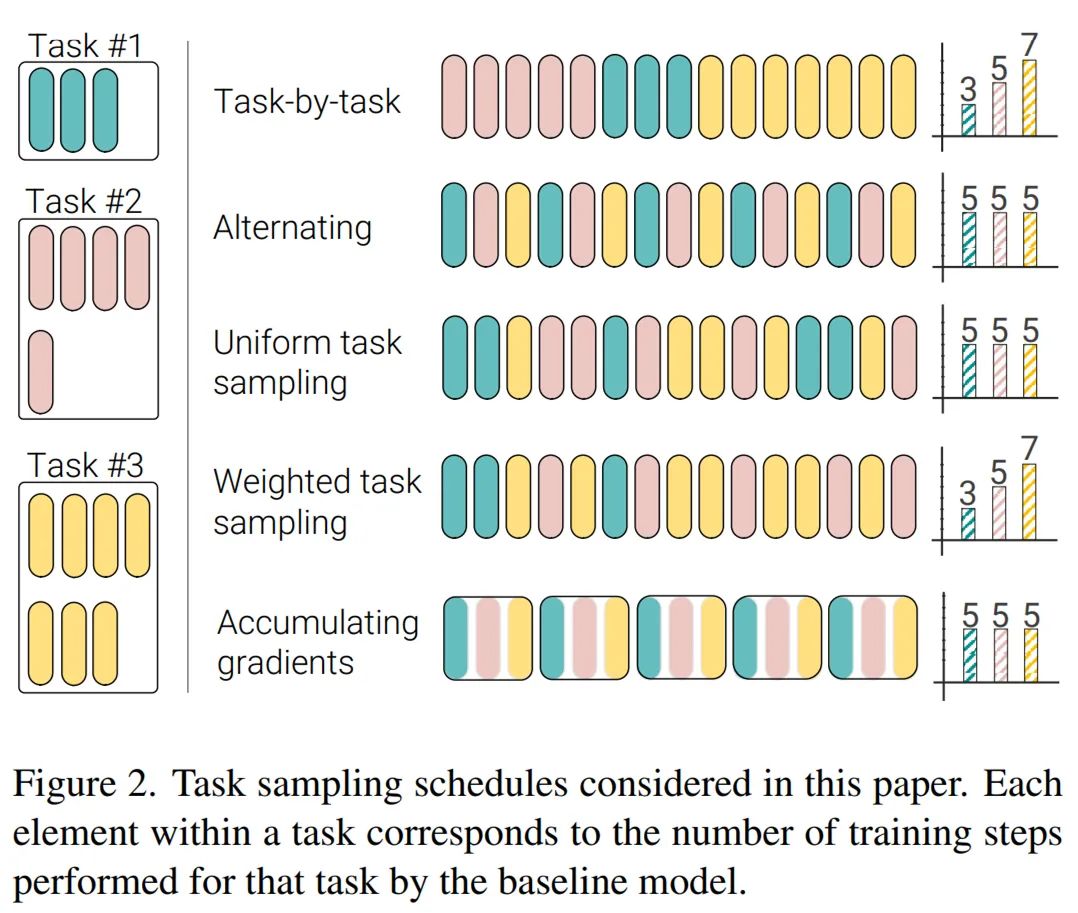
在协同训练过程中,对于每个 SGD 步,研究者采样一个任务(或数据集),然后采样来自这个任务中的 minibatch,评估梯度并随后执行参数更新。需要着重考虑的是采样任务的顺序以及是否在不同的 minibatch 和任务上累积梯度。研究者在下图 2 中描述了几个任务采样计划,包括如下:
任务 1:逐任务(Task-by-task)
任务 2:交替(Alternating)
任务 3:统一任务采样(Uniform task sampling)
任务 4:加权任务采样(Weighted task sampling)
任务 5:累积梯度(Accumulating gradients)
![]()
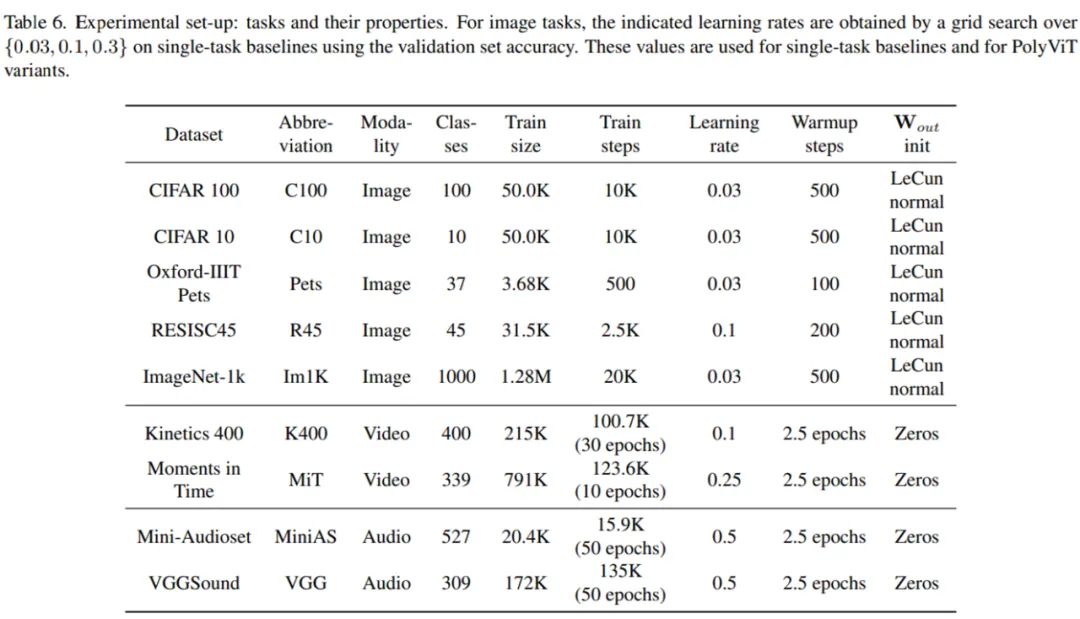
研究者在图像、音频和视频三种模态的 9 个不同分类任务上同时训练了 PolyViT。在图像分类协同训练时,他们使用了 ImageNet-1K、 CIFAR-10/100、Oxford-IIIT Pets 和 RESISC45 数据集;对于视频任务,他们使用了 Kinetics 400 和 Moments in Time 数据集;对于音频任务,他们使用了 AudioSet 和 VGGSound 数据集。
![]()
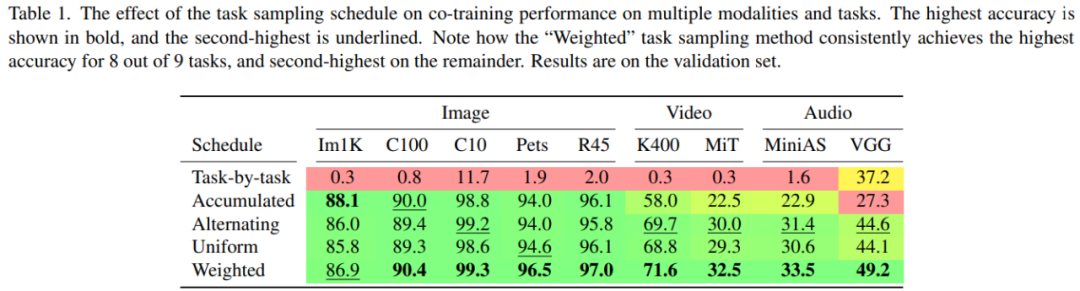
下表 1 展示了不同任务采样计划在不同模态和任务上对协同训练性能的影响,粗体表示最高准确率,下划线表示次最高准确率。其中,「Task-by-task」采样计划表现糟糕,仅在一项任务上实现了不错的性能,这是灾难性遗忘(catastrophic forgetting)造成的。
「Accumulated」采样计划需要在所有任务上使用单一的学习率,这是由于所有任务上的累积梯度被用于执行参数更新。因此,该计划仅在图像数据集上表现良好。
「Alternating」、「Uniform」和「Weighted」采样计划表现最好,表明任务特定的学习率以及不同任务的梯度更新之间的转换对于准确率至关重要。
![]()
下表 2 展示了用于解决跨图像、音频和视频三种模态的 9 个不同任务的模型训练方法,包括 ViT-Im21K Linear probe、Single-task baseline 和本文的 PolyViT 及变体(分别是 PolyViT L_adapt = 0 和 PolyViT Ladapt = L/2)。
结果显示,在单模态上训练的 PolyViT 在 9 个数据集的 7 个上实现了 SOTA 性能,其余 2 个数据集上的准确率差异可以忽略不计,不超过 0.3%。此外,参数的总数量比单个任务基线少了 2/3。同时,在使用参数大大减少的情况下,多模态 PolyViT 也实现了有竞争力的性能。
![]()
通过为一个新任务仅仅添加和训练一个新的线性头(linear head),研究者对 PolyViT 学习到的特征表示进行评估。下表 3 展示了多种模态上训练的 PolyViT 如何学习「在跨图像、音频和视频三种模态的 11 个线性评估任务上均表现良好的」跨模态特征表示。同时,表 3 还展示了多种模态上的协同训练如何有益于学习强大、可迁移且可用于多个下游任务的特征表示。
![]()
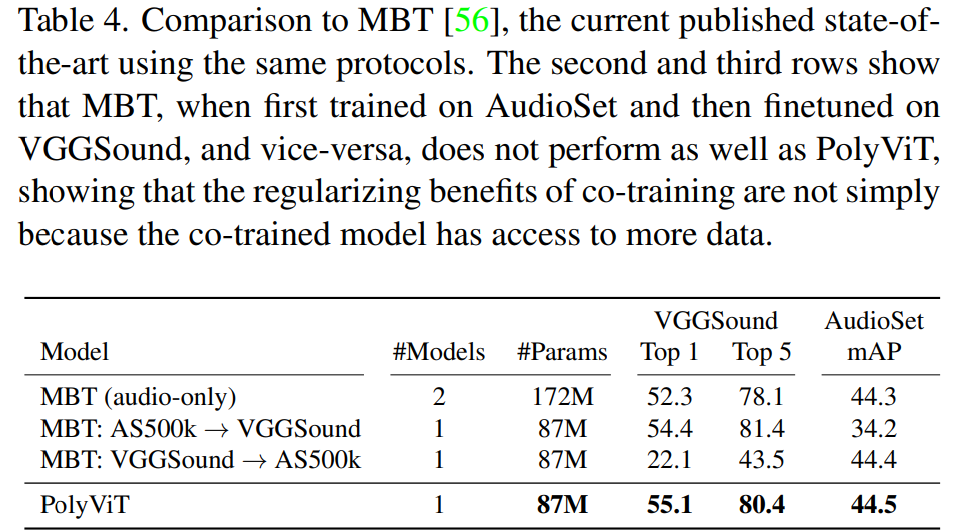
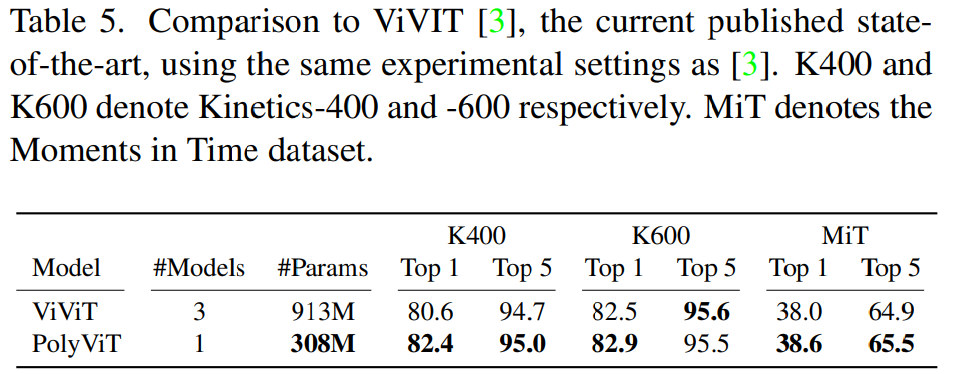
受到上表 2 中单模态协同训练性能的启发,研究者使用这种方法在音频和视频分类任务上执行了大规模协同训练实验。下表 4 和表 5 显示,在使用的参数明显更少的同时,他们实现了 SOTA 结果。
如下表 4 所示,对于音频分类,研究者将 PolyViT 与当前 SOTA 方法 MBT(audio-only) 及相关变体 MBT: AS-500k→VGGSound 和 MBT: VGGSound→AS-500k。结果表明,PolyViT 在两个数据集上超越了 SOTA 方法,同时使用的参数大约是 MBT(audio-only) 的一半。此外,PolyViT 在更小的数据集 VGGSound 上实现了 2.8% 的 Top 1 准确率提升。
![]()
对于视频分类,研究者在 Kinetics-400、Kinetics-600 和 Moments in Time 数据集上协同训练了具有较小 tubelet size 的 PolyViT-Large 模型,并与当前 SOTA 模型 ViViT(使用相同的初始化、主干和 token 数量)进行了比较。结果如下表 5 所示,表明 PolyViT 在三个数据集上均超越了 ViViT。
![]()
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

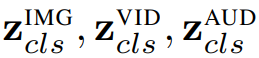 、输入嵌入算子
、输入嵌入算子
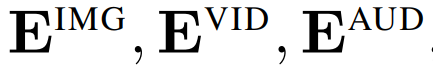 和位置嵌入
和位置嵌入
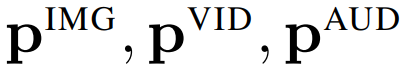 。
这使得网络可以编码模态特定的信息,这些信息又可以被随后的、共享 transformer 主干所利用。
。
这使得网络可以编码模态特定的信息,这些信息又可以被随后的、共享 transformer 主干所利用。