比SOTA模型更全能!商汤科技和上海人工智能实验室联手打造统一模型架构UniFormer



“
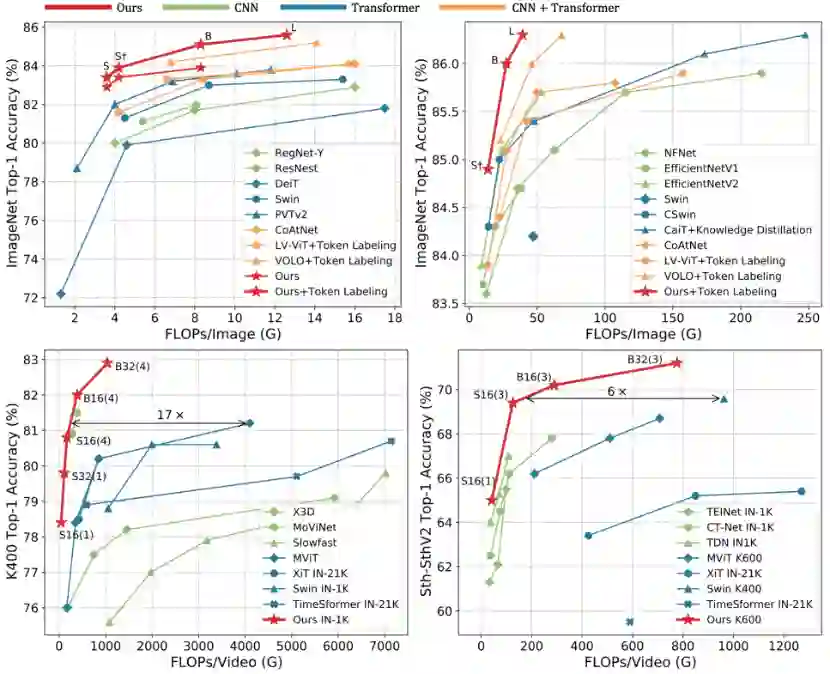
相对SOTA,UniFormer的性能提升


“
UniFormer设计灵感
-
local redundancy:
视觉数据在局部空间/时间/时空邻域具有相似性,这种局部性质容易引入大量低效的计算。
-
global dependency:
要实现准确的识别,需要动态地将不同区域中的目标关联,建模长时依赖。
Convolution只在局部小邻域聚合上下文,天然地避免了冗余的全局计算,但受限的感受也难以建模全局依赖。

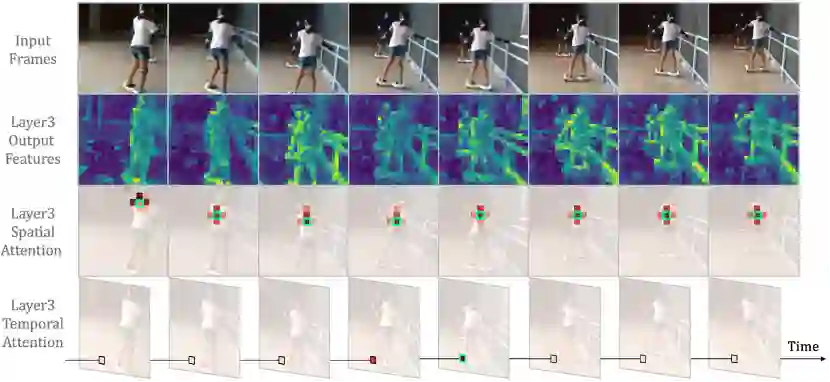
“
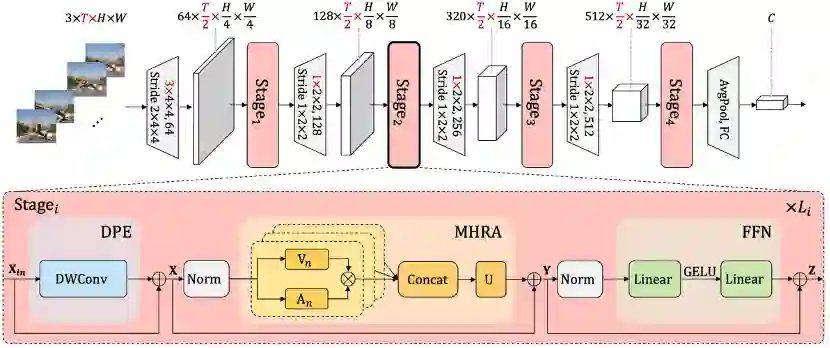
UniFormer模型架构
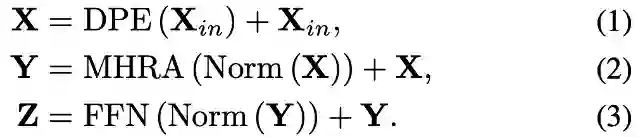
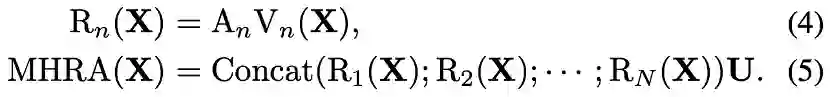
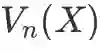 ,然后在token affinity
,然后在token affinity
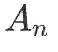 的作用下,对上下文进行有机聚合。
的作用下,对上下文进行有机聚合。
 设计为可学的参数矩阵:
设计为可学的参数矩阵:
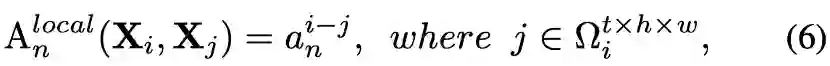
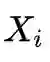 为anchor token,
为anchor token,
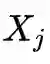 为局部邻域
为局部邻域
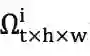 任一token,
任一token,
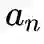 为可学参数矩阵,
为可学参数矩阵,
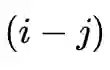 为二者相对位置,表明token affinity的值只与相对位置有关。
为二者相对位置,表明token affinity的值只与相对位置有关。
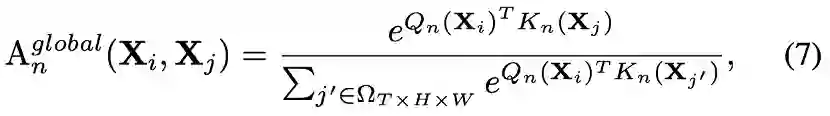
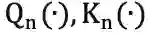 为不同的线性变换。先前的video transformer,往往采用时空分离的注意力机制 ,以减少video输入带来的过量点积运算,但这种分离的操作无疑割裂了token的时空关联。
为不同的线性变换。先前的video transformer,往往采用时空分离的注意力机制 ,以减少video输入带来的过量点积运算,但这种分离的操作无疑割裂了token的时空关联。
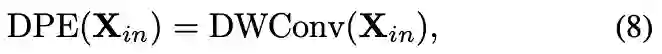
“
UniFormer整体框架

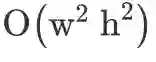 复杂度降至
复杂度降至
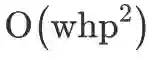 ,其中p为窗口大小。
,其中p为窗口大小。
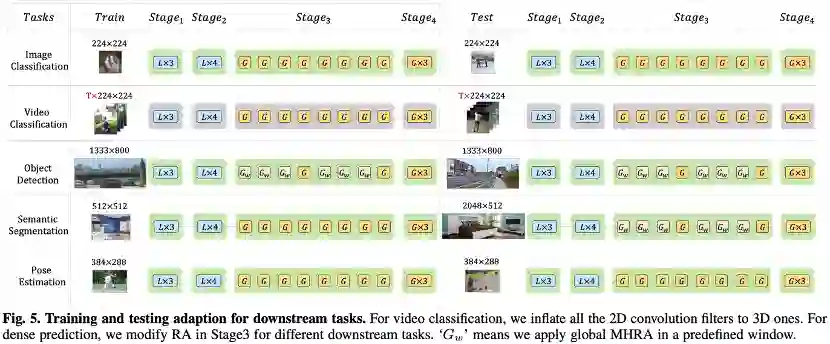
“
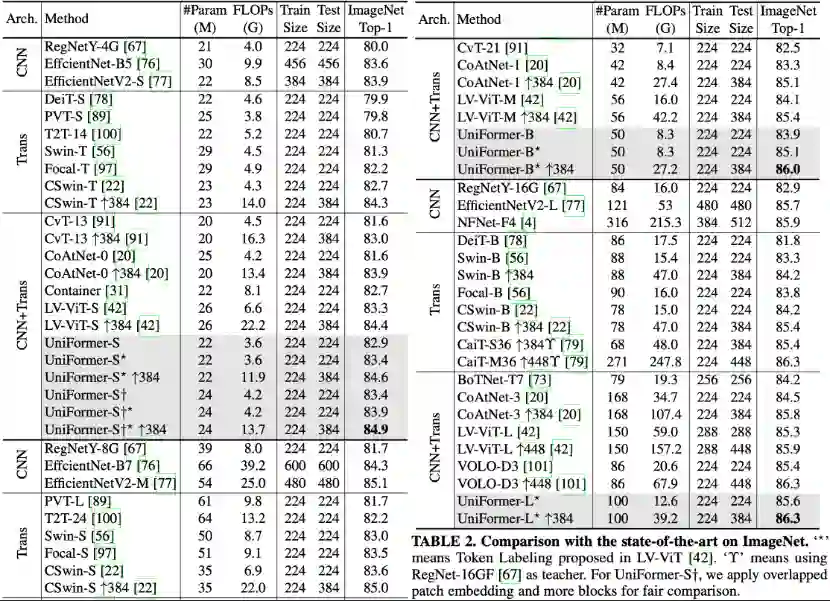
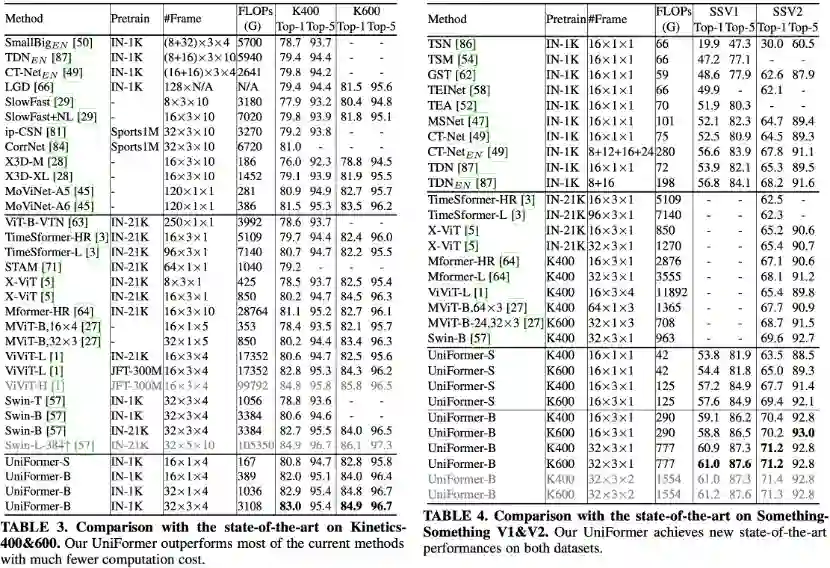
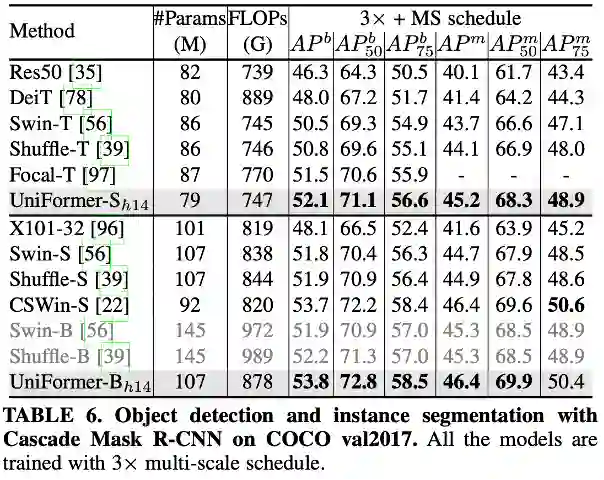
实验结果

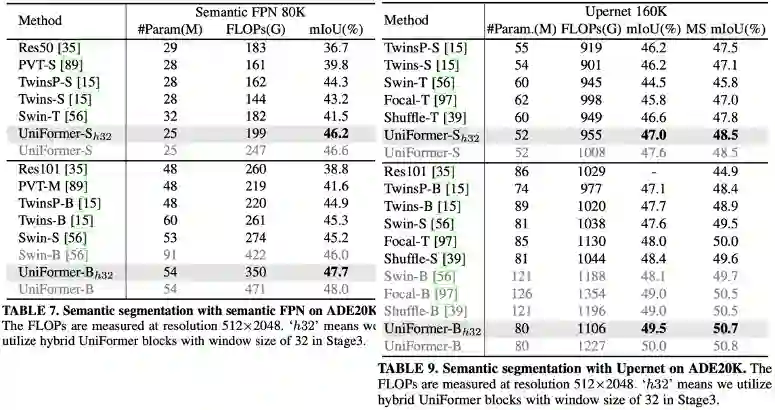
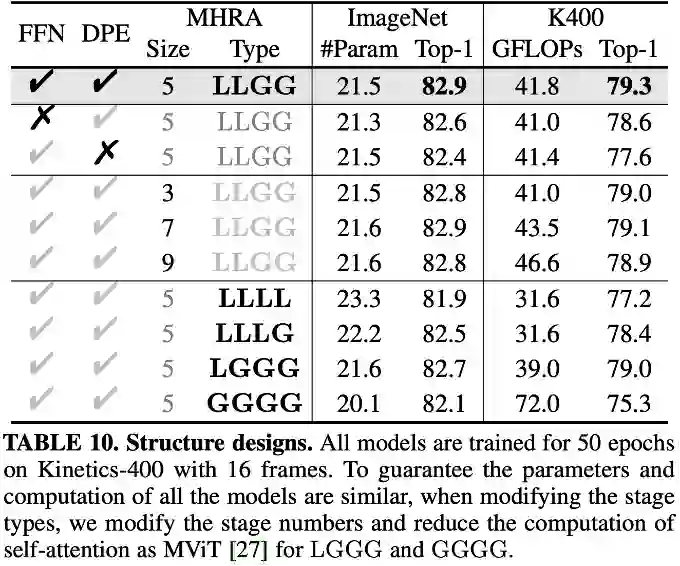
首先将local block替换为MobileNet block,其中ReLU替换为GeLU,expand ration设置为3保持计算量一致,保留动态编码以公平比较,可以发现local block在图像和视频分类任务上都会明显优于MobileNet block。由此可知transformer风格,以及其特有的FFN确实增强了token的特征表达。
将local MHRA的卷积核大小设置为3、5、7、9,性能差异并不大,最终采用大小为5的卷积核,以取得最好的计算量与准确率的权衡。
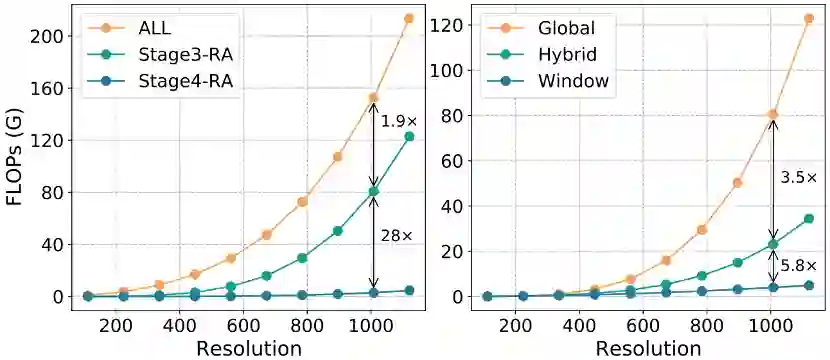
结果可以发现,仅使用local MHRA时,计算量很小,但性能下降明显。逐层替换global MHRA后,性能逐渐提升。
但全部替换为global MHRA后,视频分类准确率急剧下降,计算量急剧上升,这主要是因为网络缺失了提取细节特征的能力,冗余的attention在有限的video数据下导致了急剧的过拟合。
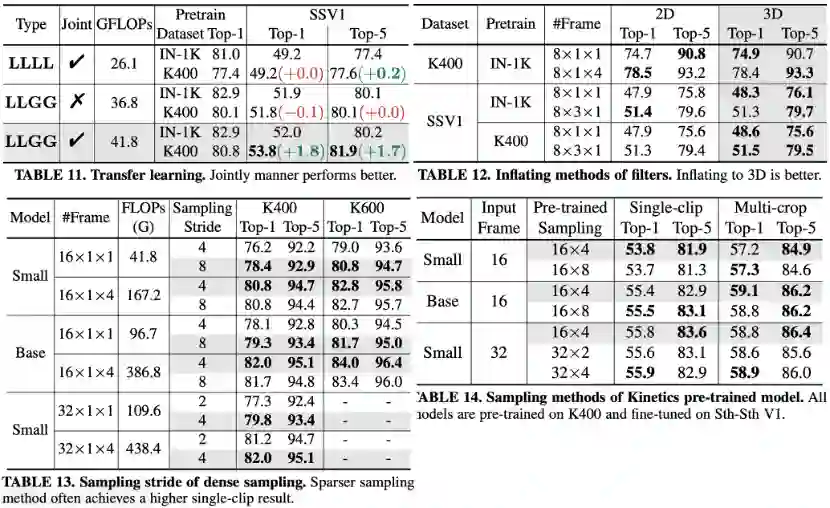
如上图所示,表11比较了不同结构的预训练性能以及小数据集上的迁移学习性能,可以发现,联合的时空学习方式,不仅在预训练模型上性能更好,在小数据集上的迁移学习性能提升明显。
而纯local MHRA以及时空分离的学习方式,迁移小数据训练未能带来提升。
如上图所示,表12中比较了是否对卷积核进行展开,可以发现,展开为3D卷积核,在场景相关的数据集Kinetics-400上性能接近,但在时序相关的数据集Sth-Sth V1上提升明显,尤其是在强的预训练的加持下,这表明3D卷积核对时空特征的学习能力更强。
如上图所示,表13中比较了我们在训练Kinetics时,使用不同间隔采样的结果。可以发现更稀疏的采样,在单clip测试上效果往往更好,但在多clip测试时,间隔4帧采样更好。
由于加载Kinetics预训练模型训练Sth-Sth,而Sth-Sth采用uniform采样,所以有必要知道预训练覆盖更多帧是否能带来提升。
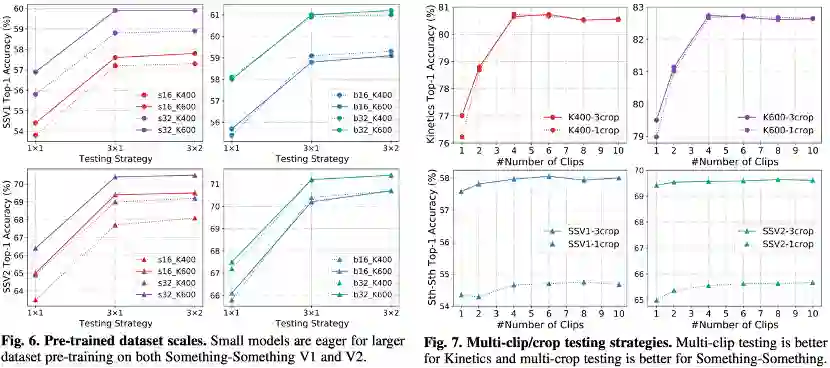
左:不同数据集预训练
右:不同测试策略
如上图所示,图7比较了不同的测试策略,可以发现对于使用dense采样方式训练的场景相关数据集Kinetics而言,多clip测试方案较好,且1x4综合性能最优。对于使用uniform采样方式训练的时序相关数据集Sth-Sth而言,多crop测试方案较好,且3x1综合性能最好。
🤖️
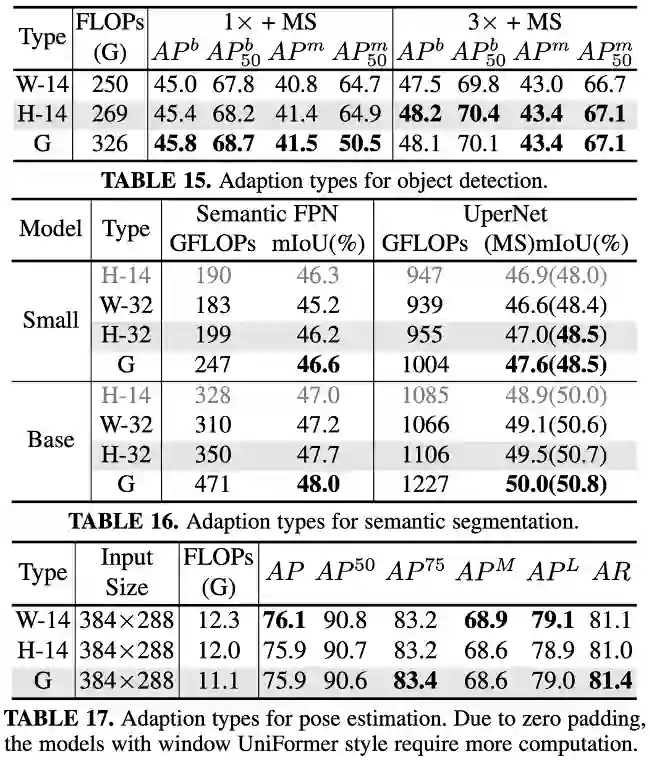
下游改进
semantic segmentation:
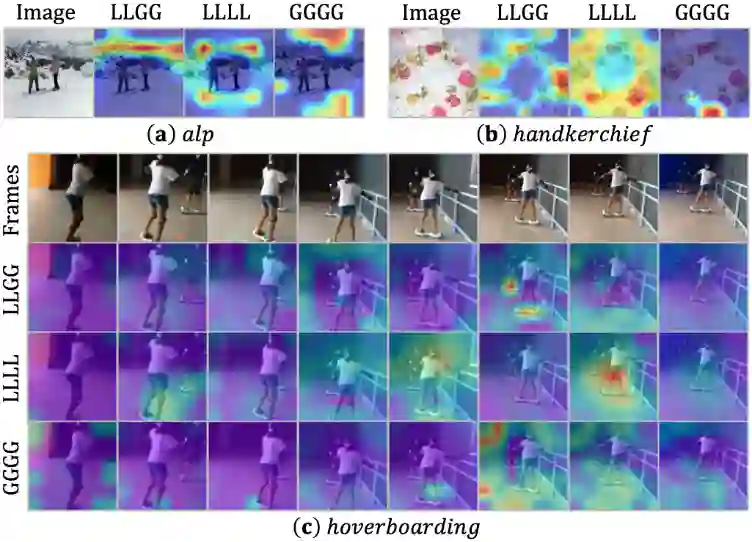
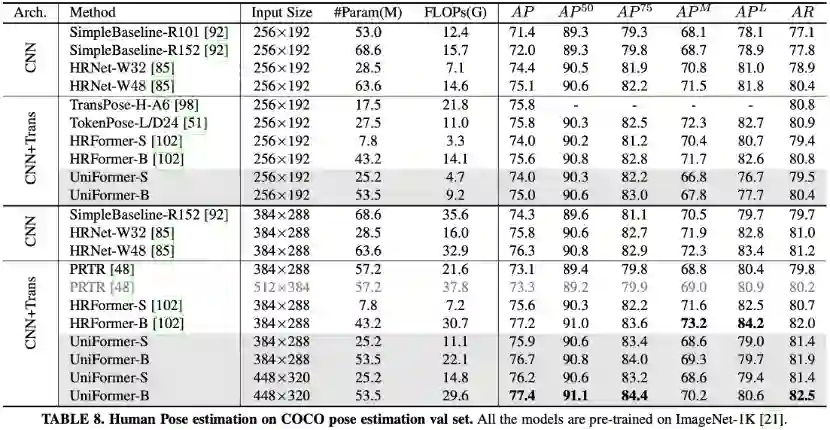
图像分类与视频分类

“
总结与思考
✨MorphMLP链接:
技术方向:
1. 超大模型设计与优化,大规模神经网络理解;
2. 基础研究与应用,包括但不限于:目标检测/识别/分割,知识蒸馏,基础模型结构设计等;
3. 无监督/半监督训练;
4. 大规模数据训练优化、通用表征学习;
5. 长尾任务,开集类别检测等;
6. 轻量化模型设计与优化;
7. AutoML相关技术研发;
团队优势:
1. 1000+独有GPU( V100+A100),5000+共享GPU;
2. 良好的研究氛围与技术指导,有足够的warm up周期;
3. 团队技术积累丰富,对解决具有挑战性的问题充满激情,获得多项著名竞赛冠军,如ImageNet2017、OpenImage2019、ActivityNet2020、NIST FRVT、MOT2016、MMIT2019, MFR等 。
岗位要求:
1. 熟练掌握机器学习(特别是深度学习)和计算机视觉的基本方法;
2. 具备以上一个或多个技术方向的研究经历,对该领域技术理解扎实;
3. 优秀的分析问题和解决问题的能力,对解决具有挑战性的问题充满激情,自我驱动力强;
4. 有较强的研究能力优先,如发表过第一作者CCF A类会议或期刊等论文。
联系方式(简历投递,请注明实习或全职):
songguanglu@sensetime.com
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧

登录查看更多
相关内容
Arxiv
0+阅读 · 2022年4月16日



相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月16日