全新轻量级ViT!LVT:具有增强自注意力的Lite视觉Transformer
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:集智书童

尽管 Vision Transformer 的表示能力令人叹服,但目前的轻量级 Vision Transformer 模型仍然存在局部区域密集预测不一致和不正确的问题。作者怀疑Self-Attention机制的效果在比较浅的网络中是有限的。
因此,本文提出了Lite Vision Transformer (LVT),这是一种新型的轻量级Transformer网络,具有两种增强的Self-Attention机制,以改善边缘部署模型的性能。
对于Low-level特征,引入了卷积自注意力(Convolutional Self-Attention, CSA)。与以往融合卷积和自注意力的方法不同,CSA将局部自注意力引入到大小为3×3卷积中,以丰富LVT第一阶段的Low-level特征。
对于High-level特征,提出了递归Atrous自注意力(RASA),利用多尺度上下文计算相似性映射,并采用递归机制以增加额外的边际参数代价的表示能力。
LVT在ImageNet识别、ADE20K语义分割、COCO全景分割等方面的优势得到了验证。
1介绍
基于Transformer的架构最近取得了显著的成功,它们在各种视觉任务中表现出了卓越的性能,包括视觉识别、目标检测、语义分割等。
Dosovitskiy受到自然语言处理中Self-Attention的启发,首次提出了一种基于Transformer的计算机视觉网络,其关键思想是将图像分割成小块,从而通过位置嵌入实现线性嵌入。
为了降低 Self-Attention 引入的计算复杂度,Swin-Transformer通过使用局部非重叠窗口限制自注意力的计算开销。此外,引入分层特征表示来利用来自不同尺度的特征以获得更好的表示能力。
另一方面,PVT提出了spatial-reduction attention (SRA)来降低计算成本。它还通过在基本Transformer Block的自注意力层之后的前馈网络(FFN)中插入深度卷积来消除位置嵌入。
Swin-Transformer和PVT都证明了它们对于下游视觉任务的有效性。然而,当将模型缩小到移动端友好的大小时,也会出现显著的性能下降。
在这项工作中,专注于设计一个移动端高效的Vision Transformer。更具体地说,引入了一个Lite Vision Transformer (LVT) Backbone,它具有两个新颖的自注意力层,以追求性能和紧凑性。LVT遵循标准的四阶段结构,但与现有的移动端网络(如MobileNetV2和PVTv2-B0)具有类似的参数大小。
这里对自注意力的第一个改进是卷积自注意力(Convolutional self-attention, CSA)。自注意力层是Vision Transformer的基本组件,因为自注意力捕获了短期和长期的视觉依赖。然而,识别位置是视觉任务成功的另一个重要关键。例如,卷积层是处理Low-level特征的更好层。现有的技术已经提出将卷积和自注意力与全局感受野结合起来可以得到更高的性能。
相反,作者将局部自注意力引入到卷积核大小为3×3的卷积中。CSA被提出并应用于LVT的第一阶段。由于CSA的存在,LVT比现有的Transformer模型更丰富了Low-level特征,具有更好的泛化能力。如图1所示,与PVTv2-B0相比,LVT能够在局部区域产生更多的相干标签。

另一方面,lite模型的性能仍然受到参数数量和模型深度的限制。本文进一步提出通过递归Atrous自注意力(RASA)层来提高lite Transformer的表示能力。如图1所示,LVT结果的语义正确性较好,这是因为这种有效的表示方式。
具体来说,RASA包含了两个具有权重共享机制的组件。第一个是Atrous自注意力(ASA)。在计算query和key之间的相似度时,它利用了具有单个卷积核的多尺度上下文。第二个是递归管道。按照标准的递归网络,将RASA形式化为一个递归模块,其中ASA作为激活函数。它在不引入额外参数的情况下增加了网络深度。
在ImageNet分类、ADE20K语义分割和COCO全景分割上进行实验,以评估LVT作为广义视觉模型Backbone的性能。
主要贡献总结如下:
-
提出了卷积自注意力(CSA)。与以往融合全局自注意力和卷积的方法不同,CSA将局部自注意力集成到卷积核大小为3 × 3的卷积中。该算法通过包含动态核和可学习滤波器来处理Low-level特征; -
提出递归Atrous自注意力(RASA)。它由两部分组成。第一部分是Atrous自注意力(ASA),它捕捉了自注意力相似性映射计算中的多尺度语义。另一部分是用ASA作为激活函数的递归公式。提出了RASA算法,在增加额外参数代价的前提下提高算法的表示能力。 -
提出Lite Vision Transformer (LVT)作为视觉模型的轻量级Transformer Backbone。LVT包含四个阶段,前三个阶段分别采用CSA和RASA。LVT在ImageNet识别、ADE20K语义分割和COCO全景分割等方面的性能都得到了验证。
2相关工作
2.1 Vision Transformer
ViT是第一个证明了Transformer结构可以以优异的性能转移到图像识别任务中的Vision Transformer。图像被分割成一系列的patches,这些patches被线性嵌入为ViT的token输入。
在ViT之后,提出了一系列的改进方法。
在训练方面,DeiT介绍了Transformer知识蒸馏策略。
对于Tokenization,T2T-ViT提出了T2T模块,递归地将相邻token聚合成一个token,以丰富局部结构建模。TNT进一步将token分解成更小的token,从它们中提取特征,以便与普通token特征集成。
对于位置嵌入,CVPT提出了可推广到任意分辨率图像的动态位置编码。
在多尺度加工方面,Twins研究了局部自注意力和全局自注意力的结合。该方法在位置嵌入中引入了卷积,从不同阶段考察了不同尺度下特征间的交叉注意力。
Cross-ViT提出了处理不同尺度token的双路Transformer,并采用了基于交叉注意力的token融合模块。
在层次设计方面,Swin-Transformer和PVT都采用了四阶段设计,并逐渐下样,这有利于下游的视觉任务。
2.2 CNN与Transformer的结合
有四种方法:
-
第一种是将自注意力中的位置嵌入与卷积相结合,包括CVPT和CoaT;
-
第二种是在自注意力前应用卷积,包括CvT、CoAtNet和BoTNet;
-
第三个是在自注意力后插入卷积,包括LocalViT和PVTv2;
-
第四种是并行的自注意力和卷积,包括AA和LESA。
与上述所有将局部卷积与全局自注意力合并的方法不同,本文提出了卷积自注意力(Convolutional self-attention, CSA),它将自注意力和卷积结合在一起,并在模型的第一阶段将3×3 kernel作为一个强大的层。
2.3 递归卷积
递归方法已被用于卷积神经网络(CNNs)的各种视觉任务。它包括图像识别、超分辨率、目标检测、语义分割。与这些方法不同的是,本文在轻量级Vision Transformer中研究了一种递归方法作为通用Backbone。具体而言,提出了一种具有多尺度query信息的递归自注意力层,有效地提高了移动端模型的性能。
3Lite Vision Transformer
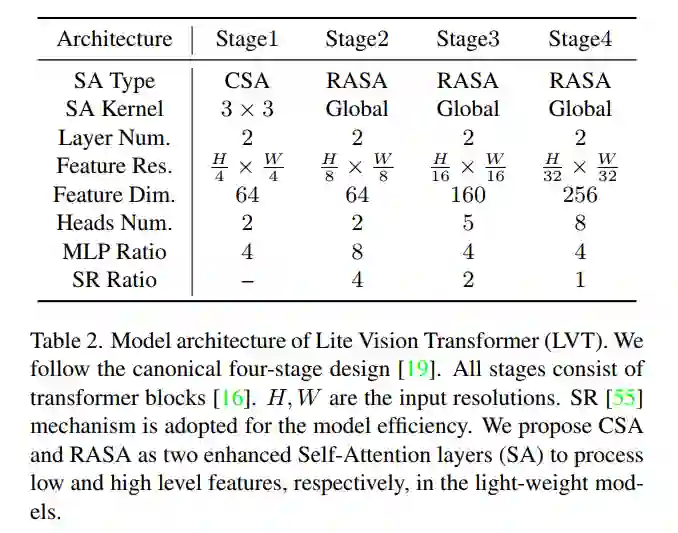
本文提出了Lite Vision Transformer (LVT),如图2所示。作为多视觉任务的Backbone,遵循标准的四阶段设计。每个阶段执行一次下采样操作,并由一系列构建块组成。输出决议从第4步逐步到第32步。与以往的Vision Transformer不同,LVT的参数比较少,具有两个新的自注意力层。第一个是卷积自注意力层,第一阶段采用了3×3卷积核。第二个是递归的Atrous自注意力层,它有一个全局卷积核,在最后三个阶段被采用。
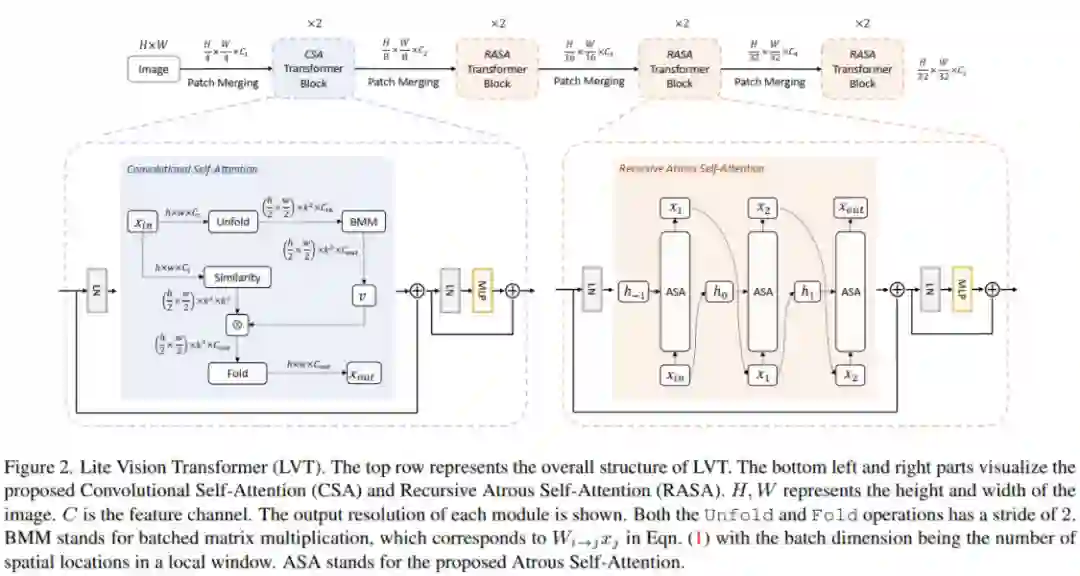
3.1 卷积自注意力模块(CSA)
我们应该都知道全局感受野有利于自注意力层的特征提取。然而,在视觉模型的早期阶段,卷积更受青睐,因为局部性在处理Low-level特征时更为重要。与以往结合卷积和大核(全局)自注意力的方法不同,作者重点设计了一个基于窗口的自注意力层,它有一个3×3 kernel,并包含卷积的表示。
1、卷积再分析
让 是输入和输出特征向量,其中d表示通道数。让 索引空间位置。卷积是通过滑动窗口计算的。在每个窗口中,可以将卷积公式写为:

其中 表示由以位置 为中心的核定义的局部邻域中的空间位置。 ,其中 为核大小。 表示 到 之间的相对空间关系。 是投影矩阵。总的来说,kernel中有 。一个3 × 3 kernel由9个这样的矩阵 组成。
2、Self-Attention再分析
自注意力需要3个投影矩阵 计算query,key和value。本文考虑了基于滑动窗口的自注意力问题。在每个窗口中,可以写出自注意力的公式为:

其中, 是一个标量,控制值在求和中每个空间位置的贡献。 通过softmax操作归一化,使得 。与相同核大小k的卷积相比,可学习矩阵的数量为3,而不是 。最近,Outlook Attention提出了预测 ,而不是通过query和key的点积来计算 ,并且在kernel size较小时表现出了优越的性能。这里也采用这样的计算,可以写成:
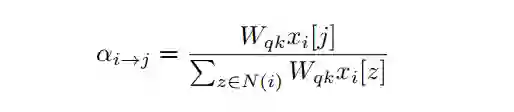
其中 和 表示向量的第 个元素。
3、Conv Self-Attention的诞生
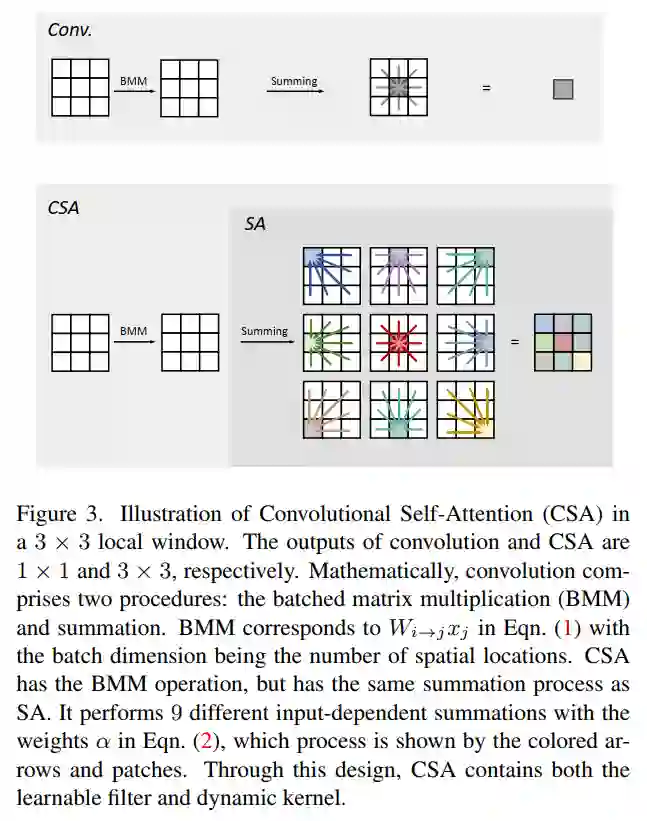
将自注意力和卷积推广为统一的卷积自注意力,如图3所示。其公式如下:

SA和CSA都有大小为k×k的局部窗口输出。当 且所有权值相同时,CSA为输出中心的卷积。当 且所有投影矩阵都相同时,CSA为自注意力。
由于采用输入预测的动态 ,如Eqn(3)所示,Outlook Attention是CSA的一个特例。CSA的容量比Outlook Attention大。在表1中总结了它的性质。通过这种推广,CSA既具有输入相关的kernel,又具有可学习的滤波器。为增强Vision Transformer第一阶段的表现能力而设计的。

3.2 Recursive Atrous自注意力(RASA)
轻量化模型更高效,更适合于设备上的应用程序。然而,即使采用先进的模型体系结构,它们的性能也受到参数数量较少的限制。对于轻量级模型,本文将重点放在通过略微增加参数数量来增强它们的表示能力。
1、Atrous自注意力层
我们都知道多尺度特征有利于检测或分割目标。Atrous卷积被提出以与标准卷积相同数量的参数来捕获多尺度上下文。权值共享的Atrous卷积也被证明可以提高模型性能。
与卷积不同,自注意力的特征响应是来自所有空间位置的投影输入向量的加权和。这些权重由query和key之间的相似度确定,并表示任何一对特征向量之间的关系强度。因此,在生成如图4所示的权重时,添加了多尺度信息。具体来说,将query的计算从1×1的卷积升级为以下操作:
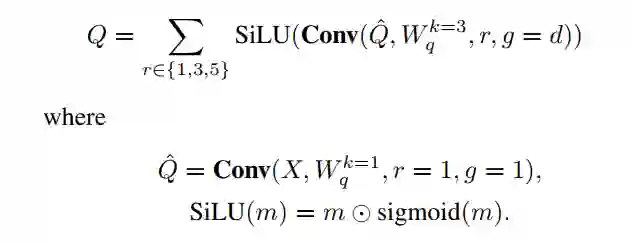
为特征映射, 为权值。 是空间维度。D为特征通道。 表示卷积的核大小、膨胀率和组数。
这里,首先使用1×1卷积来应用线性投影。然后,应用三种具有不同膨胀率但共享内核的卷积来捕获多尺度上下文。通过将组数量设置为特征通道数量,进一步降低了参数开销。然后将不同尺度的并行特征加权求和。
同时本文采用了一种自校准机制,通过激活强度来确定每个刻度的weight。这可以由SiLU实现。在本设计中,自注意力中任意一对空间位置之间的query和key的相似度计算采用了多尺度信息。
2、Resursive Atrous自注意力 (RASA)
对于轻量级模型,在不增加参数使用的情况下增加它们的深度。递归方法在卷积神经网络的许多视觉任务中被提出。与这些方法不同,本文提出了一种自注意力的递归方法。设计遵循标准循环网络。与Atrous自注意力(ASA)相结合,提出递归Atrous自注意力(RASA),其公式可以写成:
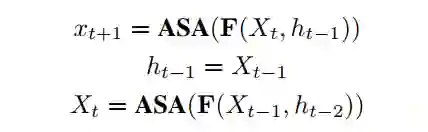
其中 为步长, 为隐状态。以ASA作为非线性激活函数。初始隐藏状态 。 是输入状态与隐藏状态相结合的线性函数。 是投影weight。然而,经验发现,设置 可以提供最好的性能,并且避免引入额外的参数。将递归深度设置为2,以限制计算成本。
4模型架构
LVT的架构如表2所示。采用标准的四阶段设计。采用四层重叠的patch嵌入层。第一个将图像采样到stride-4分辨率。另外三个样本将特征映射为stride-8、stride-16和stride-32的分辨率。所有级均由Transformer组成。每个块包含Self-Attention层,后面跟着一个MLP层。CSA嵌入在第1阶段,RASA嵌入在其他阶段。它们是增强的自注意力层,用于处理LVT中的局部和全局特征。
5实验
4.1 消融实验
1、Recursion Times of RASA
作者研究了递归时间和模型性能之间的关系。实验是在ImageNet分类上进行的。作者把递归时间设为1到4。结果如表7所示。
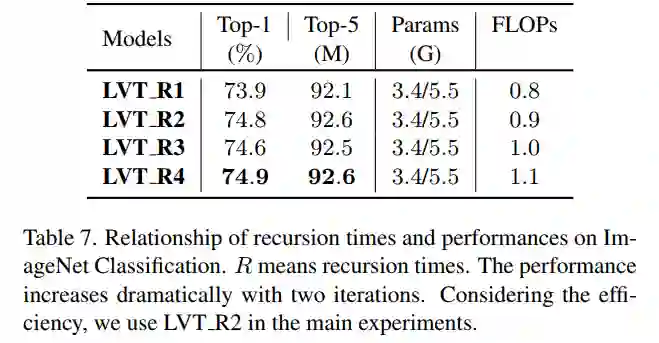
通过上表可以看出,随着递归时间的变长,精度也得到了一定的提升,但是FLOPs也有一定的提升。
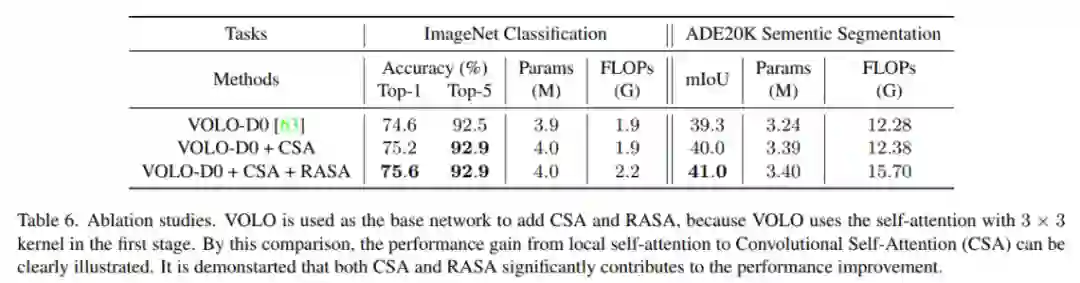
2、CSA和RASA的贡献
在下表中。对于ImageNet分类,训练和测试的输入分辨率都是224 × 224。对于ADE20K语义分割,按照SegFormer框架,在MLP解码器中插入VOLO和LVT。在测试期间,图像的短边被调整为512。它被观察到CSA和RASA对性能增益有显著的贡献。

4.2 ImageNet分类
结果如表所示。限制编码器尺寸小于3.5M,遵循MobileNet和PVTv2-B0。编码器是设计重点,因为它是其他复杂任务(如检测和分割)所使用的Backbone。为了将LVT与其他标准模型进行比较,这里将LVT扩展到ResNet50的大小。
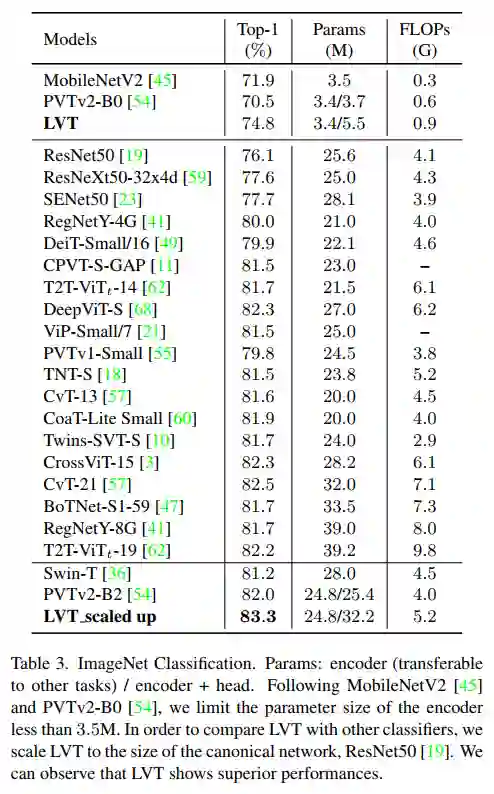
4.3 ADE20K语义分割
使用输入分辨率512×512计算。在单个NVIDIA V100 GPU上计算2000张图像的FPS。在推理过程中,将调整图像的大小,使其短边为512。只使用单尺度测试。模型是紧凑的。加上解码器,参数小于4M。可以观察到LVT在之前所有的移动语义分割方法中表现出最好的性能。
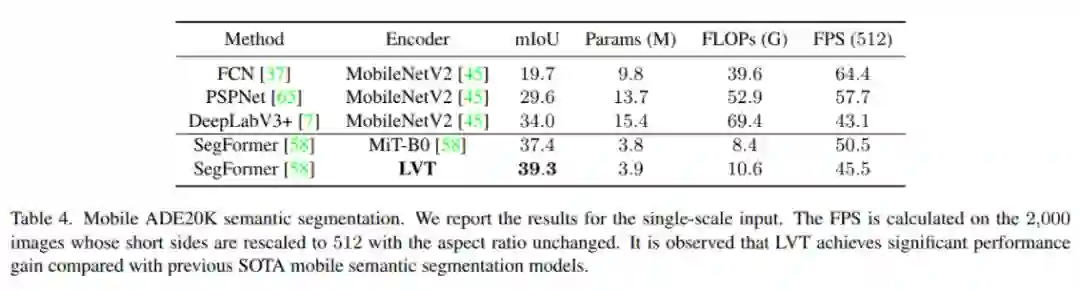
4.4 移动端COCO全景分割
输入分辨率为1200 × 800。在推理过程中,将调整所有图像的大小,使大边不大于1333,短边小于800。使用单个NVIDIA V100 GPU,在2000张高分辨率图像上计算FLOPs。包括解码器在内的整个模型所需参数小于5.5M。可以观察到LVT在移动全景分割方面的优势。
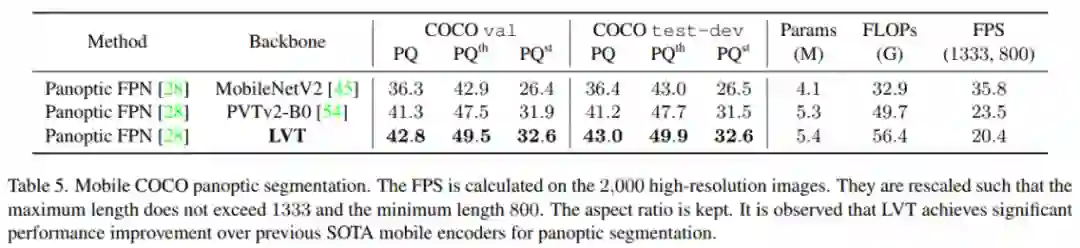

上面论文代码下载
后台回复:LVT,即可下载上述论文
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
重磅!Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、Transformer、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看


