
题目: Physically Realizable Adversarial Examples for LiDAR Object Detection
摘要:
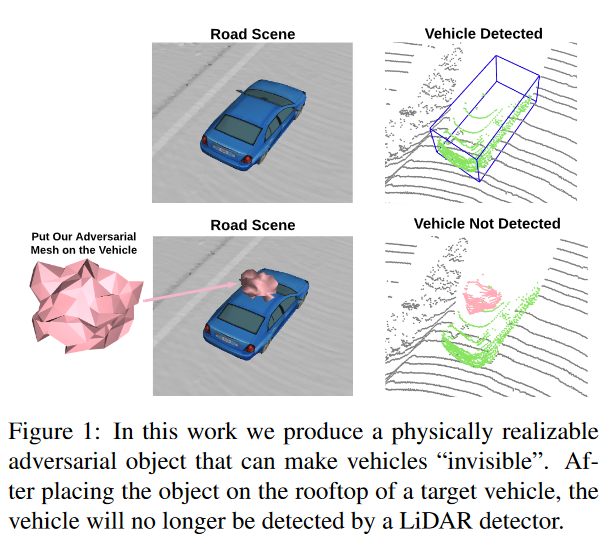
现代自主驾驶系统严重依赖深度学习模型来处理点云感知数据;与此同时,深层模型已经被证明容易受到带有视觉上难以察觉的干扰的对抗攻击。尽管这给自动驾驶行业带来了安全隐患,但在3D感知方面却鲜有探索,因为大多数对抗攻击只适用于2D平面图像。本文针对这一问题,提出了一种生成通用三维对抗对象的方法来欺骗激光雷达探测器。特别地,我们证明了在任何目标车辆的车顶放置一个对抗性物体来完全隐藏车辆不被激光雷达探测器发现,成功率为80%。我们使用点云的各种输入表示来报告一组检测器上的攻击结果。我们还利用数据扩充进行了对抗防御的初步研究。从有限的训练数据来看,这是朝着在不可见条件下更安全的自动驾驶又迈进了一步。
成为VIP会员查看完整内容
相关内容

专知会员服务
24+阅读 · 2020年4月4日
专知会员服务
51+阅读 · 2020年3月31日
专知会员服务
38+阅读 · 2020年3月23日
专知会员服务
39+阅读 · 2020年3月19日
专知会员服务
15+阅读 · 2019年11月13日
Arxiv
4+阅读 · 2018年5月13日
Arxiv
4+阅读 · 2018年2月22日
Arxiv
6+阅读 · 2018年1月28日


相关VIP内容
专知会员服务
24+阅读 · 2020年4月4日
专知会员服务
51+阅读 · 2020年3月31日
专知会员服务
38+阅读 · 2020年3月23日
专知会员服务
39+阅读 · 2020年3月19日
专知会员服务
15+阅读 · 2019年11月13日
相关资讯
相关论文
Arxiv
4+阅读 · 2018年5月13日
Arxiv
4+阅读 · 2018年2月22日
Arxiv
6+阅读 · 2018年1月28日