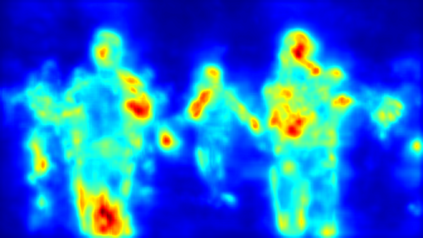
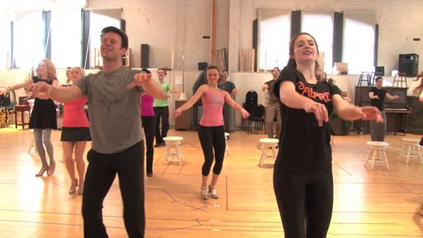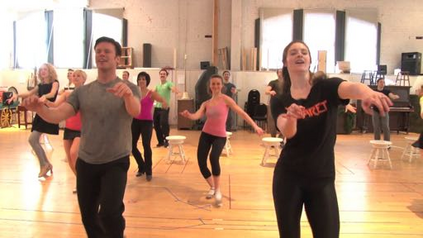Despite huge success in the image domain, modern detection models such as Faster R-CNN have not been used nearly as much for video analysis. This is arguably due to the fact that detection models are designed to operate on single frames and as a result do not have a mechanism for learning motion representations directly from video. We propose a learning procedure that allows detection models such as Faster R-CNN to learn motion features directly from the RGB video data while being optimized with respect to a pose estimation task. Given a pair of video frames---Frame A and Frame B---we force our model to predict human pose in Frame A using the features from Frame B. We do so by leveraging deformable convolutions across space and time. Our network learns to spatially sample features from Frame B in order to maximize pose detection accuracy in Frame A. This naturally encourages our network to learn motion offsets encoding the spatial correspondences between the two frames. We refer to these motion offsets as DiMoFs (Discriminative Motion Features). In our experiments we show that our training scheme helps learn effective motion cues, which can be used to estimate and localize salient human motion. Furthermore, we demonstrate that as a byproduct, our model also learns features that lead to improved pose detection in still-images, and better keypoint tracking. Finally, we show how to leverage our learned model for the tasks of spatiotemporal action localization and fine-grained action recognition.
翻译:尽管在图像领域取得了巨大成功,但像快速R-CNN这样的现代探测模型没有在视频分析中使用过近乎多的视频分析。这可以说是因为检测模型的设计是在单一框架上运行的,因此没有直接从视频中学习运动演示的机制。我们提议了一个学习程序,允许像快速R-CNN这样的检测模型直接从 RGB视频数据中学习运动特征,同时优化了两个框架之间的空间通信,同时优化了估算任务。鉴于一对视频框架框架-Frame A和框架B-WE,我们用框架B的功能来预测框架A中的人类姿势。我们这样做是因为在空间和时间上利用变形变形变形变形变形的变形。我们的网络学会了框架B的空间抽样特征,以便在框架A中最大限度地显示探测的准确性能。这自然鼓励我们的网络学习运动,将两个框架之间的空间对空间通信进行匹配。我们把这些动作的抵消称为DMoforalis(调色的动作)和框架B-B-Weram-We-we 实验中,我们展示了我们的培训计划有助于学习有效运动的动作提示,我们可以在空间和时间和时间里程中学习更精确的动作的动作, 来显示我们如何学习,我们是如何学习我们如何的动作, 展示,然后显示和显示我们是如何学习了我们是如何学习的动作,我们是如何学习了我们是如何学习了我们是如何学习的定位。