对抗样本再下一城,攻陷目标检测!自动驾驶或受攻击?UIUC学者构建欺骗检测器的对抗样本!
【导读】近日,针对深度学习系统的对抗样本攻击问题,来自伊利诺伊大学香槟分校(UIUC)的学者在 arXiv 上发表论文提出对于神经网络图像目标检测(Object Detection, Faster RCNN, YOLO.)的对抗样本生成方法。这篇文章提出的构建对抗样本的方法可以在数字图像上欺骗Faster RCNN,这些不经改变的对抗样本也可以直接欺骗YOLO9000,这表明了本文方法可以产生跨模型转移的对抗样本。同时,本文产生的对抗样本可以直接放在物理世界中,在适当的情况下它们仍然可以欺骗检测器。这个工作是第一个针对检测器产生对抗样本的方法,揭示了检测器所应具有的重要性质。
深度学习的发展也带动了一系列的研究。尤其是在计算机视觉领域,在一些标准测试集上的试验表明,深度模型的识别能力已经可以达到人类的水平。但是,人们还是会产生一个疑问,对于一个非正常的输入,深度模型是否依然能够产生满意的结果。最近大量研究者开始关注深度模型抗干扰能力的研究,也就是关于深度学习对抗样本的问题。“对抗样本”是攻击者故意设计的,被用来输入到机器学习模型里,引发模型出错的值,它就像是让机器在视觉上产生幻觉一样。在这篇文章里,我们将会展现“对抗样本”是如何通过攻陷目标检测任务的。在文末,我们给大家详细科普了一下什么是对抗样本。
▌视频
Adversarial face
Physical adversarial
论文:Adversarial Examples that Fool Detectors

▌摘要
对抗样本是在测试时被提交给系统的,被调整过以产生错误标签的样本。迄今为止,对抗样本结构已经被证明可用于分类器,但不适用于检测器。如果存在可以欺骗检测器的对抗样本,它们可能会被用来在智能车辆的道路上恶意制造安全隐患。在本文中,作者展示了一个架构可以成功欺骗两个标准检测器,Faster RCNN和YOLO。这样的例子的存在是令人吃惊的,因为攻击一个分类器与攻击一个检测器是非常不同的,而且检测器的结构——必须搜索它们自己的bounding box,并且不能精确地估计该box——使得对抗性模式很有可能被破坏。作者展示了,提出的架构产生了对抗性的样本,虽然需要大的扰动,其可以实现在跨数字序列进行很好地泛化。还展示了,提出的架构产生对抗的物理对象。
▌详细内容
一个对抗样本是这样一个样本:当其被调整后在测试时被提交给系统时,它将产生一个错误的标签。在文献中,具有不可思议的干扰和意想不到的特性(例如可转移性)的对抗样本是神经网络最大的奥秘之一。有一系列的架构产生了图像分类器的对抗样本,并且有很好的证据表明,进行小的调整就可以。此外,Athalye等人表明,有可能建立一个物理对象(physical object)的可见干扰模式,其使得标准图像分类器在大致距离的不同视角下产生一致的误分类。有证据表明,用分类器构建的对抗样本也会欺骗其他的分类器。这些攻击的成功可以被看作是一个警告,不要使用不具有强有力数学约束的高度非线性特征架构;但是,采取这一立场意味着不能使用那些基本上准确和有效的方法。
检测器不是分类器。分类器输入一个图像并生成一个标签。相反,一个检测器,像Faster RCNN ,定义的bounding boxes是“worth labelling”,然后生成每个box的标签(其中可能包括背景)。最后利用一个分类器实现最终的标签生成。但是,boundingboxes如何覆盖检测器中的物体的统计数据是复杂的,而且还不太清楚。一些近期流行的检测器,像YOLO9000 [23],使用固定网格上的特征来预测box和标签,从而导致box空间中的采样模式相当复杂,这意味着box外的像素可以参与标记该box。另一个重要的区别是,检测器通常具有RoI pooling或特征映射重新尺寸化,这可能有效地破坏对抗模式。迄今为止,在检测器中还没有成功的对抗性攻击被证实。在本文中,作者展示了对更Faster RCNN的成功的对抗性攻击,并将这种攻击推广到YOLO 9000。
作者还讨论了对抗样本的泛化能力。作者说,如果情况(数字或物理的)发生变化,相应的图像仍然是对抗的,那么对抗性干扰就是泛化的。例如,当相机接近停止标志时,如果它保持对抗性状态时,停止符号的干扰将在不同的距离上泛化。如果对于更多的情况(例如检测器变化,背景和照明的变化)仍然是对抗性的,那么这个样本的泛化能力更好。如果对抗样本不能泛化,那么在大多数系统中它不是一个威胁。
这篇文章的贡献有以下几点:
展示了一种构建对抗样本的方法,它可以数字化地欺骗Faster RCNN;由提出的方法产生的例子能被检测器错过或错误标记。这些没有修改的样本也欺骗了YOLO 9000,表明这个架构产生了可以跨模型转移的样本。
提出的对抗样本可以在物理世界中创造成功,在适当的情况下它们仍然可以欺骗检测器。它们也可以通过最近的强有力的图像处理方法来防御对抗样本。
在实践中,发现对抗样本要求对样本进行相当大的扰动,以便欺骗检测器。物理对抗样本需要比数字样本更大的扰动才能成功。

图1:Evtimov等人生成被错误分类的物理停止标志,然而,这些停止标志可以被Faster RCNN检测到。图片来自[17]的图10.(引用参见原文)
▌模型简介
“对抗样本”如何欺骗目标检测系统?
产生停止标志对抗样本的模型:
为了产生对抗样本,我们最小化Faster RCNN对训练集中所有停止标志图像产生的平均得分:
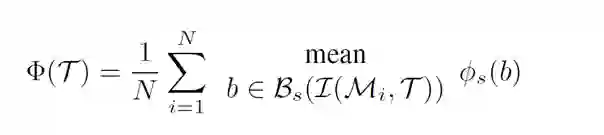
这里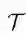
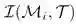
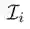
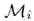
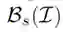
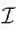
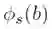
优化过程:
直观的方式是通过计算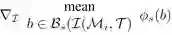
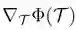
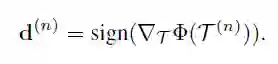
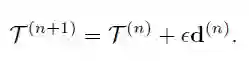
其中,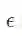
▌实验结果

图2:修改单个停止标志图像能成功地攻击Faster RCNN。在原停止标志图像(左边)中,停止标志可以被成功地检测到。在中间图像,在整个图像中添加了小的干扰,则停止标志不能被检测到。在最后一个图像中,在停止标志的符号区域添加小的干扰,而不是在整个图像,停止标志被检测成了一个花瓶。

图3:修改人脸图像以成功地攻击Faster RCNN。在原人脸图像(第一个)中,人脸被可靠地检测到。第二个图像,在整个图像中加入小的干扰,人脸没有被检测出来。最后一个图像,更大的干扰被添加到脸部区域而不是整个图像中,人脸没有被检测到。

图4:停止标志图像的对于Faster RCNN的对抗样本可以跨视角进行泛化。第一行中的原始序列是为实际停止标志(stop sign)捕获的测试视频序列,并且在所有帧中都检测到停止标志。我们将我们的攻击应用到视频训练集以产生跨视角的对抗性干扰,并将该干扰应用于该测试序列以生成第二行中的攻击序列。这是一个数字攻击,停止标志要么没有被检测到,要么被检测为风筝。

图5:针对基于人脸检测器的Faster RCNN [ 12 ]的对抗样本,可以在跨视角条件下进行泛化。第一行中的原始图像从测试视频序列中被采样,并且所有的人脸被可靠地检测到。我们将我们的攻击方法应用到视频训练集中,生成一个跨视角条件下的对抗性干扰,并将该干扰应用于该测试序列,生成第二行的攻击序列。这是一次数字攻击。

图6:我们用我们的攻击方法产生了三个对抗的停止标志图。第一个停止标志不使用L2距离惩罚,并使用终止规则,成功地攻击了90%的验证图像。第二个停止标志在目标函数中使用L2距离惩罚,当90%的验证样本被成功攻击时终止。最后一个同样适用L2距离惩罚,但是执行了大量次数的迭代。这三种都能产生数字攻击,但只有第三个在物理攻击上具有更好的效果。

图7:我们从图6中打印出三个对抗的停止标志,并将它们贴在一个真正的停止标志上。我们在开车的时候拍了打印的停止标志的视频,在这些视频中运行Fastere RCNN。注意,所有的对抗性干扰都是在数字化的情况下进行的。我们只对检测结果中的停止标志进行着色,以使图片数据更干净。这个图中的三个序列顺序对应于三个停止标志。在前两个序列中,停止标志可以被检测到,而在最后一个序列中,视频中的停止标志没有被检测到,所以它是一个物理上的对抗性停止标志。这可能是由于纹理对比度差异的结果,即使这个序列在训练中是不可见的。

表1:本表报告了停止标志多图像数字攻击的Faster RCNN和YOLO检测率。每个单元格中,分号前的比例代表Faster RCNN的检测率,分号后的比率代表YOLO的检测率。Tree bg表示停止标志的背景是树并且具有低对比度,Sky bg意味着停止标志的背景是天空并且具有高对比度。L后面的意思是扰动很大,而EL意味着扰动非常大。我们有三个黑色的停车标志,在训练/评估/测试的三个不同距离(远/中/近)计算的准确率。我们可以用多重视角条件攻击FasterRCNN,对抗性干扰可以推广到新的视角条件。对抗样本也可以推广到YOLO,特别是当背景是树时。

表2:该表展示了基于Faster RCNN的人脸检测器[12]对人脸用多重图像数字攻击的检测率。 S100表示实验中有100张图像,S15表示有15张图像。Ft表示正面,而sd表示侧面。当应用小干扰时,对所有训练图像的攻击成功,但不能泛化到验证和测试图像。只有在应用大干扰时,攻击才会泛化到不同的视角条件。
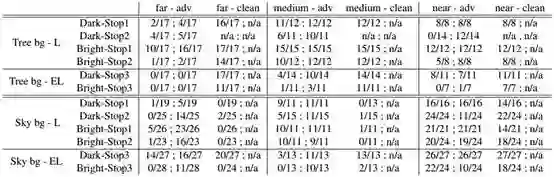
表3:RCNN和YOLO在物理对抗停止标志(physical adversarial stop signs)和物理干净停止标志(physicalclean stop signs)的不同情况下的检出率。表中的布局类似于表1。对于较大的干扰,我们有两个不同亮度的停止标志,还有一个停止标志在亮度上具有非常大的扰动。我们展示了30 x 30英寸对抗停止标志(adv)和20 x 20英寸的正常停止标志的检测率。

图8:我们测试是否Faster RCNN产生的对抗样本可以推广到YOLO。在第一行,针对小扰动的单个图像生成了这些对抗样本。YOLO可以毫不费力地检测到这些停止标志。在第二行,这些对抗样本是从多重图像生成的,数字干扰的图像可以在大约一半的时间欺骗YOLO。在最后一行,物理对抗性的停止标志在某些情况下还可以欺骗YOLO。详细的总结可在表1和表3中找到。

图9:在多重视角条件设置中,对停止标志和人脸的局部攻击会失败。我们在大量迭代中对停止标志和人脸区域施加攻击,并引入非常大的干扰,但仍然能检测到对象。详细地说,对停止标志的局部攻击有时可以对远端的停止标志进行数字欺骗,但不适用于中距离和近距离的停止标志;对人脸的局部攻击则不能欺骗人脸检测器。第一幅图像是干扰停止标志的例子,第二幅图像是干扰人脸的一个例子。

图10:将简单的防御[ 11 ]应用于关于Faster RCNN的对抗样本生成。对图像均值和分辨率进行一般的下采样,然后上采样到原始分辨率。TV噪声就是对图像进行全变化正则化去噪,去除高频信息,保持低频信息。在第一行中,通过简单的图像处理就能检测出具有小干扰的单个图像产生的对抗样本。在第二行,在简单的防御之后仍然无法检测到来自多重视角条件的对抗样本。在最后一行,在简单防御后仍然无法检测到具有物理对抗性的停止标志。
注:上述引用文献参见原文
▌结论
这篇文章已经证明了第一个对抗样本可以欺骗检测器。提出的架构也产生了欺骗检测器的物理对象。然而,作者说其所构造的所有对抗样本都需要很大的干扰,才能达到欺骗检测器的效果。这表明了在检测器中box的预测步骤是一种自然的防御形式。文章进一步推测,在提出的架构中,更好的观察模型可能会导致物理和数字结果之间的差距更小。这种模式可能揭示了对于检测器来说,什么是重要的。
▌什么是“对抗样本”
在给大家详细科普一下什么是对抗样本,在Ian J. Goodfellow的论文“Explaining and Harnessing Adversarial Examples ”中有这么一个例子:左边是一只大熊猫的图片,我们这张图片中加入一个很小的干扰噪声,虽然生成的图片看起来和原始的每什么区别,但是却会导致系统将其误认为是长臂猿的照片。


此前对抗样本已经相继攻陷图片识别,图像标注,人脸识别等任务,从而引发了广泛的关注 。
比如最近的一项研究“Adversarialexamples in the physical world”)显示,把“对抗样本”用标准的纸张打印出来,然后用普通的手机对其拍照制成的图片,仍然能够影响到系统。比如在下图中系统错把“洗衣机”标签为“保险箱”。“对抗样本”很有可能变得危险。比如,攻击者可以用贴纸或一幅画制成一个“停止”指示牌的“对抗样本”,以此来攻击汽车,让汽车将原本的“停止”指示牌误理解“让行”或其它指示牌,

此外,来自卡内基梅隆大学(CMU)的研究人员表示(Accessorize to a Crime: Real and Stealthy Attacks onState-of-the-Art Face Recognition),佩戴专门设计过的眼镜架,可以愚弄最先进的面部识别软件。一副眼镜,不单可以让佩戴者消失在人工智能识别系统之中,而且还能让AI把佩戴者误以为是别人。

前不久,来自麻省理工学院、加州大学戴维斯分校、IBM Research 和腾讯 AI Lab 的学者撰写的论文将对抗样本攻击延伸到了图像标注(image captioning)系统领域(Show-and-Fool: Crafting Adversarial Examples for Neural ImageCaptioning)。image captioning可以从给定的图像中自动生成一段描述性文字,从而可以帮助盲人阅读新闻图片的含义,或者通过实时摄像头告诉他前方有发生了什么。而对图像标注系统使用对抗样本改造后,可能会生成无关、完全相反甚至恶意的描述。比如下图中中 Show-and-Tell 模型将一个关于纳达尔的对抗样本标注为了「一名女子正在浴室里刷牙。」;右图中 Show-and-Tell 模型将一个关于停车标志的对抗样本标注为了「一只棕色的泰迪熊躺在床上。」

参考文献
https://arxiv.org/abs/1712.02494
作者主页:http://www.jiajunlu.com/
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域25个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!

点击“阅读原文”,使用专知!



