【学界】对抗强化学习最新研究:可用于自动驾驶汽车「碰撞避免机制」检测
原文:arXiv
作者:Vahid Behzadan、Arslan Munir
来源:雷克世界
导语:现如今,随着人工智能技术的迅速发展,人们普遍认为,未来的交通系统将由自动驾驶汽车(AV)所主导。可以说,对于更为安全的交通设施的需求是引起人们对自动驾驶汽车感兴趣并推动其发展的一个主要推动力。但不可否认,就现在而言,可靠和具有鲁棒性的自动驾驶汽车技术的发展仍然是一个持续的挑战,对可靠的运动规划和碰撞避免机制的研究尤其重要。最近,堪萨斯州立大学(Kansas State University,KSU)的科学家了提出了一种基于深度强化学习的新框架,用于对自动驾驶汽车的碰撞避免机制的行为进行基准测试。
现如今,随着人们对自主导航的兴趣日益增长,关于运动规划和碰撞避免技术(collision avoidance techniques)的研究已经加速了全新提议和新进展的速度。然而,新技术的复杂性及其安全性要求使得当前的大部分基准测试框架不充分,因此对高效的比较技术的需求没有得到满足。这项研究提出了一种基于深度强化学习的新框架,用于在处理最佳对抗性智能体的最坏情况下对碰撞避免机制的行为进行基准测试,该最佳对抗性智能体进行训练从而将系统驱动到不安全状态。我们将这个框架的体系结构和流程描述为一个基准测试解决方案,并通过一个比较两种碰撞避免机制的可靠性的实际案例研究来证明其有效性,从而对有意识的碰撞尝试做出回应。
人们普遍认为,未来的交通系统将由自动驾驶汽车(AV)所主导。随着近年来这一领域的迅速发展,许多人预测这种转变将在未来十年内发生。对更为安全的交通运输的需求,是引起人们兴趣和推动自动驾驶汽车发展的一个主要动机。一般认为,用专家计算模型代替人类驾驶员的内在缺陷,可以显著减少由驾驶员的误差所导致的事故数量。然而,可靠和具有鲁棒性的自动驾驶汽车技术的发展仍然是一个持续的挑战,并且人们正在积极从各个研究和发展方向来追求这一目标。
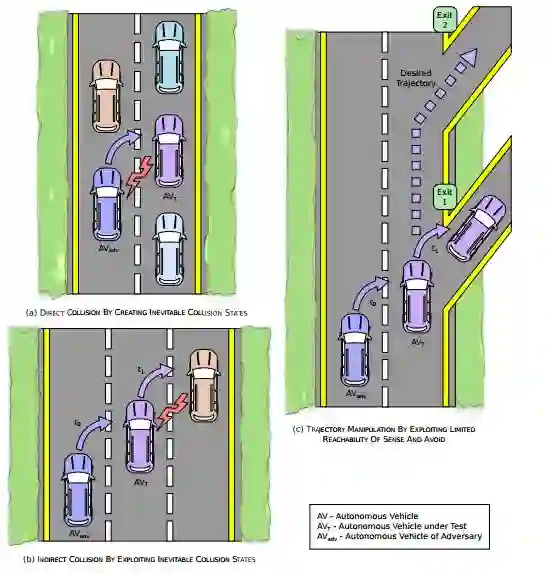
图1:对抗性目标的图释
对可靠的运动规划和碰撞避免机制的研究尤其重要。在过去数十年的时间里,科学家们已经提出了许多解决这个问题的方法,从控制理论形式化和最优控制方法到潜在的基于场和规则的技术(field- and rule-based techniques),等等。最近,机器学习的进步使得基于诸如模仿学习和深度强化学习(RL)等技术的全新数据驱动的碰撞避免方法成为可能。然而,随着其部署环境和机制日益复杂,为这些解决方案提供安全保障的挑战变得越来越困难。一个值得注意的例子是交通碰撞避免系统(TCAS),在它广泛部署到NextGen商用飞机之前,它就已经满足了联邦航空局(FAA)的严格安全要求。然而,最近的一些表现表明它在现代高密度空域中非常不可靠,在一定程度上,它可能会导致不可避免的碰撞状态(ICS)——不管未来的轨迹如何,最终都会发生碰撞。此外,最近的研究表明,自动感知和避免机制可以被对抗性地加以利用以操纵自动驾驶车辆的运动轨迹。
作为回应,科学家们提出了越来越多的缓解技术和全新的安全运动规划方法,但每一种都有特定的特定于案例的假设和验证程序。因此,对这些方法进行定量比较变得非常困难。当前最为先进的方法包括在运动规划和碰撞避免中对安全行为进行基准测试的几次尝试,但是许多现有的框架未能满足基于机器学习的新自适应技术的要求。而且,目前的基准测试框架并不能提供全面的和具有鲁棒性的探测机制,用于在不理想状态和轨迹的复杂空间中进行探索。这种框架中的突出方法是基于随机化或基于情景的障碍产生,这些障碍很容易丢失特定于被测机制的关键ICS或其他不需要的状态。这些框架中的另一种方法依赖于计算上昂贵的碰撞状态可达性分析技术,而这也无法为安全运行的关键边界提供具体的保证。
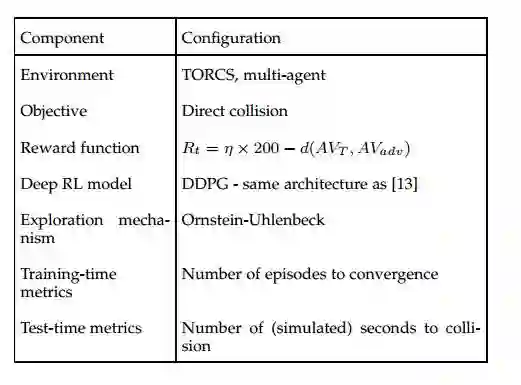
图2:实验环境设置
为了弥补以安全为中心的基准测试的缺陷,本文提出了一种基于机器学习的新框架,用于在与最优对抗性智能体进行交互的最坏情况下对新技术的可靠性进行基准测试。该框架采用深度强化学习的强大的探索和优化性能来训练对抗性自主智能体,而该智能体的目标是学习旨在将系统驱动到ICS和其他不安全状态的最佳导航策略。根据分析的参数和目标,这些目标可能包括对抗性智能体与自动驾驶汽车的直接碰撞,或利用避免碰撞机制来操纵自动驾驶汽车的轨迹以改变和控制其路径,或间接诱发自动驾驶汽车和环境中的其他物体之间的碰撞。
在此基础上,这项研究的主要贡献包括:
1)提出碰撞避免算法的最坏情况基准测试的计算框架和处理流程,且独立于其复杂性、随机性以及自适应动力学。
2)提出深度强化学习过程流程以无缝地适应于被测系统,并克服完全随机或基于情景的探索机制的缺点。
3)提出关于碰撞避免算法标准化比较的全新的衡量指标。
4)通过一个比较两种碰撞避免机制应对故意碰撞企图的可靠性的实际案例研究,来证明所提出框架的实际应用和效果。
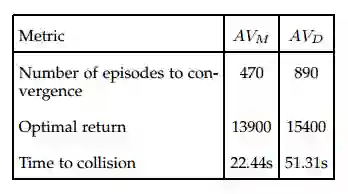
图3:实验结果——平均超过100次运行
总而言之,在本文中,我们提出了一个流程和框架,它利用对抗性深度强化学习来衡量自动驾驶汽车的运动规划和碰撞避免机制的可靠性。我们已经确立了这一框架的优势,要超过当前的基准测试规划,其中包括灵活性和通用性、通过针对特定系统下测试、样本效率和自定义探索机制对对抗性策略进行训练获得的适用性探测,以及为不同系统之间的基准测试和比较提供基线(例如,最坏的情况)测量。
可以这样说,本文所提出框架的直接架构为进一步研究提供了一些潜在的研究领域。紧随而来的下一个步骤就是将此框架应用于显著的和最近发布的运动规划和碰撞避免技术中,目的是为相关研究项目创建参考基准。另一个有发展前景的研究领域是检查近期发布技术的适用性,这些已发布的技术声称在对抗性干扰下进行训练可以增强策略的适应力和鲁棒性。因此,通过对对抗性策略和碰撞避免的强化学习模型的结合性训练进行调查,可能会出现潜在的缓解和防御技术。
原文链接:https://arxiv.org/pdf/1806.01368.pdf
☞【学界】OpenPV:中科院研究人员建立开源的平行视觉研究平台
☞【征稿通知】IEEE IV 2018“智能车辆中的平行视觉”研讨会
☞【征稿】神经计算专刊Virtual Images for Visual Artificial Intelligence
☞【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞【CFP】Virtual Images for Visual Artificial Intelligence
☞【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞【学界】谷歌大脑提出自动数据增强方法AutoAugment:可迁移至不同数据集
☞【深度】伯克利发布目前最大规模、内容最具多样性的高质量标注公开驾驶数据集BDD100K
☞【学界】CVPR 2018 | 牛津大学&Emotech首次严谨评估语义分割模型对对抗攻击的鲁棒性



