【泡泡图灵智库】实时单目物体-模型感知稀疏SLAM(ICRA)
每天一分钟,带你读遍机器人顶级会议文章
标题:Real-Time Monocular Object-Model Aware Sparse SLAM
作者:Yan Wang, Wei-Lun Chao, Divyansh Garg, Bharath Hariharan
来源:ICRA(2019)
编译:万应才
审核:李雨昊
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——Real-Time Monocular Object-Model Aware Sparse SLAM,该文章发表于ICRA 2019。
同时定位和建图(SLAM)是移动机器人的一个基本问题。虽然基于稀疏点的SLAM方法提供了精确的摄像机定位,但生成的地图缺乏语义信息。这项工作将一个实时的深度学习对象检测器合并到单目击SLAM框架中,用于将通用对象表示为四次曲面,允许检测无缝集成,同时达到实时性能。由CNN网络学习到的对象的更精细的重构也被合并,并为二次曲面的进一步精细化提供了一个先验形状。为了捕捉场景的主要结构,使用CNN的平面探测器检测到额外的平面标志,并在地图中建模为独立的标志。大量的实验证明我们提出的将语义对象和平面结构直接包含在SLAM-语义SLAM的束调整中,这在语义上丰富了重建的地图,同时显著改善了相机的定位。
贡献
本文的主要贡献如下:(1)将两个不同的基于CNN的模块集成到分割平面上,并对参数进行回归;(2)将一个实时的深度学习目标检测器集成到单目SLAM框架中,以检测一般目标作为数据关联策略的地标并跟踪它们,(3)为物体提出一个新的观测因子,以避免轴对齐的圆锥体,(4)代表相对于摄像机的地标,这些地标是第一次观测到的,而不是一个全局参考帧,(5)在可用的情况下,整合利用CNN在地图上对单个图像中的目标进行检测,并基于重建点云对重建二次曲面的范围进行附加先验。
方法
本文介绍了一个单目SLAM系统,它可以在一个在线的实时系统中结合平面和物体模型方面的已知先验。我们表明,在SLAM框架中引入这些数量可以更精确地跟踪摄像机和更丰富的地图表示,而无需巨大的计算成本。这项工作也为利用深度学习来提高传统的SLAM技术的性能提供了一个案例,通过引入更高层次的结构实体和先验,从平面和对象的角度。
我们使用前面提出的对偶四次曲面的表示。
(1)从前端的角度,例如:a)依赖深度通道进行平面分割和参数回归,b)预先计算更快的R-CNN基础对象检测以允许实时性能,以及c)特别对象和平面匹配/跟踪。
(2)从后端的角度来看:a)假设圆锥观测是轴对准的,从而限制了二次重建的稳健性;b)所有探测到的地标都保持在一个全局参考框架内。这项工作除了解决上述局限性外,还提出了新的因素,可以实时包含平面和物体检测,同时将深度CNN的细点云重建(如有)纳入地图,并根据该对象模型改进二次重建。

图1 本文提出的SLAM系统的结构

图2 单视点云重构对多视点云重构二次曲面的形状先验约束
实验
1.场景重构评估

图3 不同TMU和NYUv2数据集的定性结果。从丰富的平面结构到多对象杂乱的办公场景,这些顺序各不相同。
2.对比
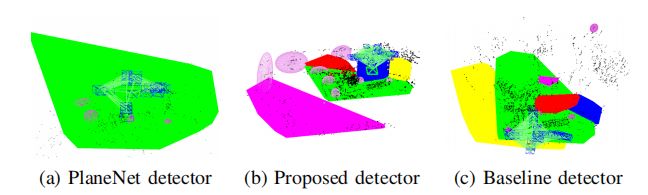
图4FR1/XYZ单目SLAM系统中使用不同平面探测器的定性比较
3.重建效果和相机估计结果。用我们的Slam重建了Kitti-7的地图和摄像机轨迹。提出的目标观测和形状先验因子在重建过程中是有效的,并将重建的轿车和两厢车停放在路边的点云模型与四次曲面一起进行了渲染.
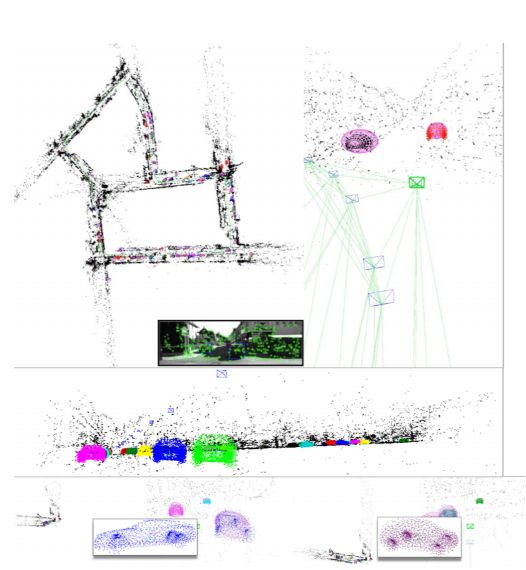
图5 SLAM场景建图和相机位姿估计
4.RMSE(Cm),我们单目SLAM与与ORb-SLAM 2相比,改进的百分比。
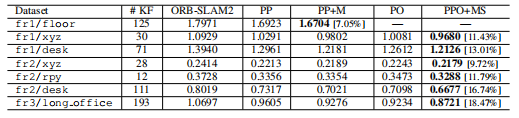
表1 与orb-SLAM对比

Abstract
Simultaneous Localization And Mapping (SLAM)is a fundamental problem in mobile robotics. While sparse point-based SLAM methods provide accurate camera localization, the generated maps lack semantic information. On the other hand, state of the art object detection methods provide rich information about entities present in the scene from a single image. This work incorporates a real-time deeplearned object detector to the monocular SLAM framework for representing generic objects as quadrics that permit detections to be seamlessly integrated while allowing the real-time performance. Finer reconstruction of an object, learned by a CNN network, is also incorporated and provides a shape prior for the quadric leading further refifinement. To capture the dominant structure of the scene, additional planar landmarks are detected by a CNN-based plane detector and modeled as independent landmarks in the map. Extensive experiments support our proposed inclusion of semantic objects and planar structures directly in the bundle-adjustment of SLAM - Semantic SLAM - that enriches the reconstructed map semantically, while signifificantly improving the camera localization.
如果你对本文感兴趣,请点击点击阅读原文下载完整文章,如想查看更多文章请关注【泡泡机器人SLAM】公众号(paopaorobot_slam)。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com




