
摘要
提供态势感知是战术领域的一项关键要求和一项具有挑战性的任务。战术网络可以被描述为断开、间歇和受限 (DIL) 网络。在 DIL 网络中使用跨层方法有助于更好地利用战术通信资源,从而提高用户感知的整体态势感知。用于优化应用程序的规则,描述其合适跨层策略(启发式)的规范仍然是一项具有挑战性的任务。
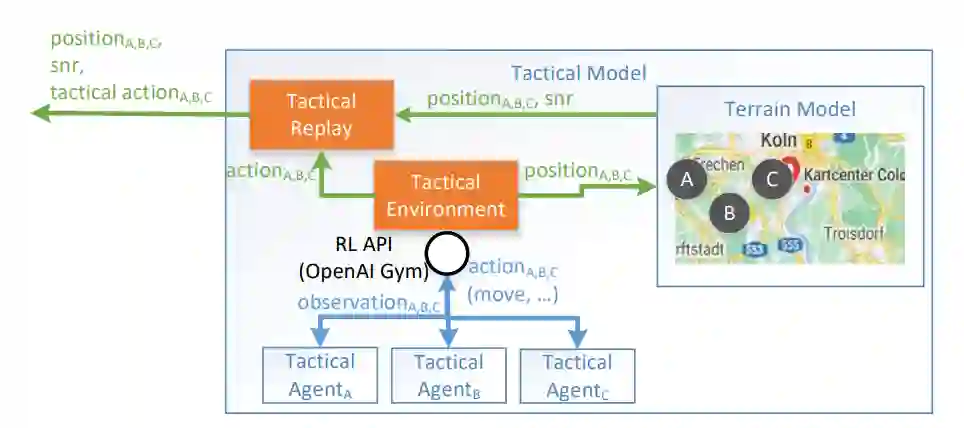
我们之前介绍了一种学习环境架构,旨在训练分散的强化学习 (RL) 智能体,这些智能体应该通过使用跨层信息 [1] 来改善 DIL 网络中网络资源的使用。由于这些智能体的训练需要大量场景,因此定义了一个额外的战术模型。战术模型的目的是生成具有动态变化的网络条件和应用程序之间动态信息交换的场景,从而为训练 RL 智能体奠定基础。战术模型本身也基于 RL 智能体,它在博弈环境中模拟军事单位。
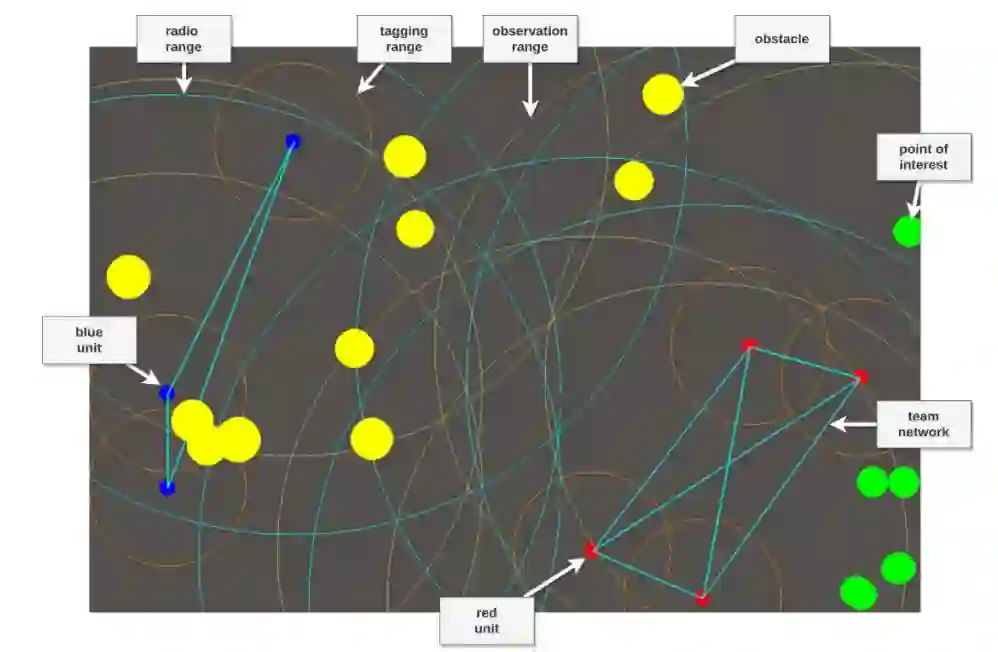
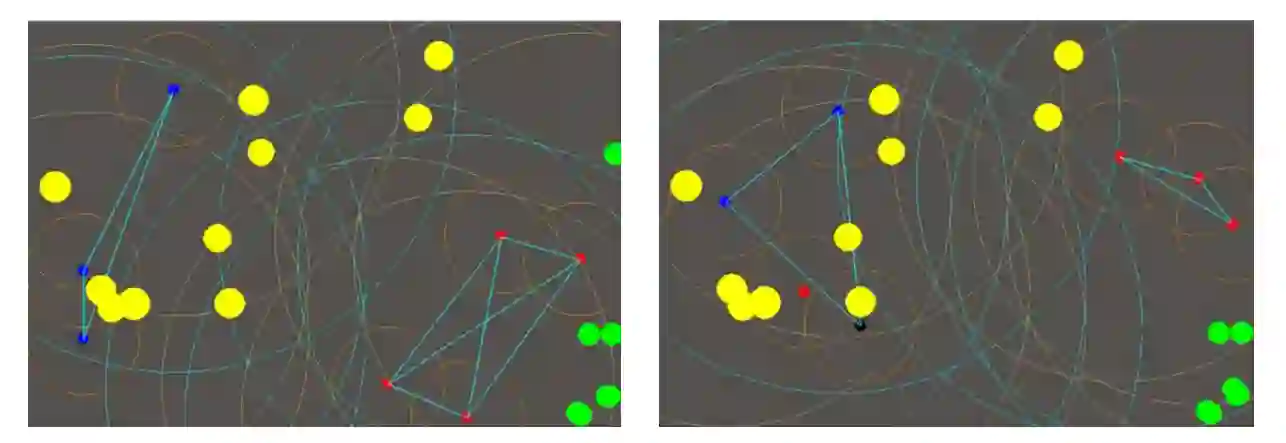
在本文中,我们展示了这个战术模型,实验性的深度强化智能体放置在一个专注于控制多智能体合作博弈中的运动和通信战术环境中。该博弈的重点是多个智能体,通过在二维空间中进行交流和移动来达到与对方团队竞争的共同目标。我们研究智能体如何与彼此和环境交互以解决偶发性和连续性任务。由于这项工作的重点是在通信网络上进行强化学习以增强 DIL 通信网络,因此我们提出了基于近端策略优化 [2] 的智能体,以适应协作多智能体通信网络问题。此外,该博弈的最终轨迹用于在 DIL 设置中训练智能体。
成为VIP会员查看完整内容

相关内容

Arxiv
0+阅读 · 2022年4月20日
Arxiv
0+阅读 · 2022年4月19日
Arxiv
0+阅读 · 2022年4月18日
相关主题

相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月20日
Arxiv
0+阅读 · 2022年4月19日
Arxiv
0+阅读 · 2022年4月18日