【ICML2020-天津大学】多智能体深度强化学习中的Q值路径分解
多智能体深度强化学习中的Q值路径分解

Q-value Path Decomposition for Deep Multiagent Reinforcement Learning
作者:
杨耀东 郝建业 陈广勇 汤宏垚 陈赢峰 胡裕靖 范长杰 魏忠钰
简介:
近年来,由于许多现实世界中的问题可以建模为多智能体系统,因此多智能体深度强化学习(MARL)已成为一个非常活跃的研究领域。一类特别有趣且广泛适用的问题可以被抽象为部分可观察的合作式多智能体环境,在这种环境中,一组智能体根据自己的局部观察和共享的全局奖励信号来学习协调其行为。一种自然的解决方案是求助于集中式训练、分布式执行范式。在集中式训练期间,一项关键挑战是多智能体信度分配:如何为单个智能体的策略分配属于它自身的贡献,从而更好地协调以最大化全局奖励。在本文中,我们提出了一种称为Q值路径分解(QPD)的新方法,可以将系统的全局Q值分解为单个智能体的Q值。和以前的工作限制单个Q值和全局Q值的表示关系不同,我们将累积梯度归因技术运用到深度MARL中,沿着轨迹路径直接分解全局Q值来为智能体进行信度分配。我们在具有挑战性的《星际争霸II》微观管理任务上评估了QPD,表明其与现有的MARL算法相比,QPD在同质和异质的多智能体场景中均达到了先进的性能。
方法:
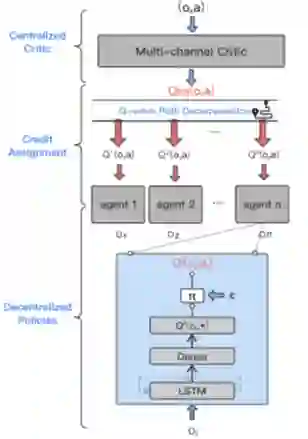
在集中式训练、分布式执行的范式下,智能体会依据自身的历史轨迹和当前观察选择执行动作与环境交互,使用集中式的critic网络学习基于智能体联合观察和动作的全局Q值函数。
在获得当前轨迹后,通过累积梯度技术沿着状态动作轨迹将全局Q值归因到每个智能体的特征上,将属于每个智能体的特征的归因信度叠加作为当前状态下智能体的个体Q值信度。
使用个体Q值信度作为底层智能体策略网络的监督信号对智能体策略进行训练。
效果:
该算法在挑战性的星际争霸游戏平台进行了测试,实验显示QPD能够在同质和异质场景中学习到协调的策略,取得先进的性能。
地址:
https://www.zhuanzhi.ai/paper/58224edb0d1daf4fc46ba395a22ce0eb
参考链接:
https://mp.weixin.qq.com/s/2SkwD1csLLw0icZ9Kzpcmg
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“QPD” 可以获取《【ICML2020-天津大学】多智能体深度强化学习中的Q值路径分解》专知下载链接索引







