教程 | 如何在Unity环境中用强化学习训练Donkey Car
介绍
Donkey Car是一种为模型车开源的DIY自动驾驶平台,它利用一个带有相机的树莓派单片机,让模型车可在赛道上自动驾驶,Donkey Car会学习你的驾驶方法,在训练后懂得自动驾驶。对于那些没有背景知识的人来说,该平台能提供你所需要的必要细节,它既包含硬件也带有软件。阅读完这一教程,你也可以无需硬件背景知识组装一辆自己的自动驾驶汽车。
现在,训练汽车进行自动驾驶最常见的方法就是行为克隆和路线跟随。在高级层面,行为克隆是利用卷积神经网络学习汽车前方摄像机所拍摄的图像之间的映射,并通过监督学习控制方向和油门大小。而路线跟随是利用计算机视觉技术跟踪路线,并且利用一个PID控制器让小车跟着该路线。我尝试了两种方法,它们都很有用!

用行为克隆训练Donkey Car避开障碍物
用强化学习训练Donkey Car
重要的一点是,Donkey Car的目标是搭建一辆在比赛中跑的最快的车(能以最快速度跑完一圈)。我认为强化学习是训练的好方法,只需设计一种奖励,让汽车的速度达到最快,并且让它能一直保持在轨道内即可。听上去很简单对吧?但事实上,很多研究表示在实体目标上训练强化学习是很困难的。强化学习主要通过试错法训练,放在汽车身上,我们只能保佑车子不会在一次次的实验中撞碎。另外,训练时长也是一个问题,通常,强化学习智能体都要训练个几百回合才能掌握些许规律。所以,强化学习很少用在现实物体中。
模拟现实
最近有一些科学家们研究对现实进行模拟,即先用强化学习在虚拟模拟器上训练小车,然后将其迁移到现实世界里。例如,最近OpenAI就训练了一个灵活的机械手臂,可以做出多种动作,整个过程就是在虚拟中训练的。除此之外,谷歌大脑也曾训练过一个四足机器人,可以用模拟现实的技术学习灵活的动作。在虚拟器中学习控制策略,然后再将其部署到真正的机器人上。这样看来,若想用强化学习训练Donkey Car,一个可行方案就是先用模拟器训练,再把学到的策略用在真的小车上。

OpenAI训练的机械手
Donkey Car模拟器
第一步是先为Donkey Car建造一个高保真度的模拟器。幸运的是,Donkey Car社区里一位爱好者在Unity中创建好了一个模拟器。但是它设计的目的主要针对行为学习(即将相机中的图片保存在对应的控制角度和油门大小文件中以进行监督学习),但是和强化学习无关。我希望的是有一个类似OpenAI Gym那样的交互界面,可以用reset( )重置环境、对其进行操作。所以,我决定在现有的Unity模拟器基础上对其进行修改,让它更适合强化学习。
4.1 创建一种能用Python和Unity沟通的方法
因为我们要用Python书写强化学习代码,所以我们首先要找到一种方法能让Python在Unity环境中使用。结果我发现这现有的模拟器也是用Python代码进行沟通的,但它是通过Websocket协议进行的,Weosocket和HTTP不同,它支持服务器和客户端之间进行双向通信。在我们的案例中,我们的Python“服务器”可以直接向Unity推送信息(方向和油门),而我们的Unity“客户端”也可以反向对服务器推送信息(状态和反馈)。
除了Websocket,我还考虑使用gRPC,这是一种高性能服务器-客户端通信框架,用谷歌在2016年八月开源。Unity将其用于机器学习智能体接口通信的协议。但是它的设置有点麻烦,并不高效,所以我还是选择Websocket。
4.2 为Donkey Car创建一个定制化的环境
下一步是创建一个类似于OpenAI gym的交互界面,用于训练强化学习算法。之前训练过强化学习算法的人可能对各种API的使用很熟悉。常见的就是reset( )、step( )、isgameover( )等。我们可以将OpenAI gym的种类进行扩展,然后用上面的方法创建自己的gym环境。
最终成果能和OpenAI gym相媲美,我们科用类似的指令与Donkey环境交互:
env = gym.make("donkey-v0")
state = env.reset()
action = get_action()
state, action, rewards, next_state = env.step(action)
环境同样可以让我们设置frame_skipping,并且用headless模式训练智能体(也就是无需Unity GUI)。
同时,Tawn Kramer还有3中Unity场景可用:生成道路、仓库和Sparkfun AVC,都可以用于训练。在我们开始运行自己的强化学习算法之前,我们要么自己搭建Donkey Car的Unity环境,要么下载预先搭建好的环境可执行程序。具体的环境设置和训练指导可以在我的GitHub中找到:github.com/flyyufelix/donkey_rl
4.3 用DDQN训练Donkey Car
准备好了对强化学习友好的环境,我们现在就可以搭建自己的强化学习算法啦!我采取的是用Keras书写的Double Deep Q学习算法,这是DeepMind开发的经典强化学习算法,易于测试,编写简单。我已经在OpenAI gym中的cartpole和VizDoom中测试了,所以如果有什么问题,应该是Unity环境的问题,算法没有问题。关于DQN的文章,大家可以参考我之前的博文。flyyufelix.github.io/2017/10/12/dqn-vs-pg.html
4.3.1 状态空间
我们用Donkey Car前方安装的摄像机所拍摄的像素照片,执行以下转换:
将尺寸从(120, 160)改为(80, 80)
变为灰度图像
框架堆叠:去前面几个步骤中的4个框架堆在一起
最后的状态维度应该是(1, 80, 80, 4)。
4.3.2 动作空间
现实和虚拟世界中的Donkey Car都是将持续的方向控制和油门数值作为输入。为了简介,我们将油门数值设为常量(例如0.7),仅仅改变控制方向。控制方向的值从-1到1,但是,DQN只能处理分离的动作,所以我将方向的值分为15个种类。
4.3.3 Q网络框架
我们的Q网络是一个3层卷积神经网络,以堆叠的框架状态为输入,输出表示方向值分类的15个值。
4.3.4 奖励
奖励是有关汽车偏离中线程度的函数,它由Unity环境所提供。奖励函数用以下公式表达:
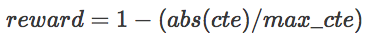
其中maxcte是一个归一化常数,所以奖励的范围在0到1之间。如果abs(cte)大于maxcte,循环即终止。
4.3.5 其他重要变量
Frame skipping设置为2以稳定训练。Memory replay buffer的值为10000.Target Q网络在最终训练时会更新。CNN训练时的Batch size为64。贪婪函数用于探索。Epsilon初始值为1,逐渐在10000次训练后会成为0.02。
4.3.6 结果
经过上面的设置,在单个CPU和一个GTX 1080 GPU上,我训练了DDQN差不多100次。整个训练用了2到3个小时。可以从上面的视频中看到,小车跑得很好!
去除背景噪声
我们想让我们的强化学习智能体只根据路线的位置和方向进行决策输出(即方向控制),不要受环境中的其他因素影响。但是,由于我们的输入是全像素的图像,它可能对背景模式过度拟合,而无法认出行进路线。这在现实中尤其重要,因为旁边的车道可能会有障碍物(例如桌子、椅子、行人等)。如果我们想从虚拟世界将学习策略进行迁移,我们应该让智能体顾略背景中的噪音,只关注于车道。
为了解决这个问题,我创建了一个预处理通道,可以将行车路线从原始像素图像中分离出去,再输入到CNN中。分割过程受这篇博文的启发(https://medium.com/@ldesegur/a-lane-detection-approach-for-self-driving-vehicles-c5ae1679f7ee)。这一过程概括如下:
用Canny Edge检测器检测并提取所有边框
用Hough直线转换确定所有直线
将直线分成positive sloped和negative sloped两类
删除所有不属于车道的直线
最终转换出的图片应该有最多2条直线,具体情况如下:

接着我把分割后的图像重新调整到(80, 80)的,将4个连续的框架堆叠在一起,用它们作为新的输入状态。我使用新状态再次训练了DDQN,生成的强化学习智能体可以学习良好策略进行驾驶!
然而,我注意到不仅仅训练时间会变长,学习策略也会变得不稳定,车子会经常在转弯的时候摇晃。我想可能是因为在训练的时候丢掉了有用的背景信息。不然的话,智能体应该不会过度拟合。
下一步
在这篇文章中,我们介绍了一种能和OpenAI gym相比的环境,用来训练Unity模拟器中的Donkey Car。还用DDQN训练它自动成功地自动驾驶。接下来,我计划让小车通过训练加速到最大值,并且将这一策略迁移到现实中。
原文地址:flyyufelix.github.io/2018/09/11/donkey-rl-simulation.html
代码地址:github.com/flyyufelix/donkey_rl





