深入理解强化学习,看这篇就够了

©PaperWeekly 原创 · 作者 | 孙裕道
学校 | 北京邮电大学博士生
研究方向 | GAN图像生成、情绪对抗样本生成

强化学习
-
强化学习的数据集不是训练初始阶段就有的,而是来自智能体与环境交互才能获得; -
强化学习不追求单步决策的最优策略,而是追求与环境交互获得的长期累积奖励。强化学习需要从整体上衡量整个交互过程。智能体在做决策时,会更加偏向于历史交互中带来更多奖励的动作。同时正如发现这些动作一样,未曾选择的动作中可能蕴藏着更优的决策,这鼓励着智能体尝试未曾选择的动作。因此智能体需要平衡利用(exploitation)和探索(exploration)。

马尔可夫决策过程
-
表示所有状态(state)的集合,也称为状态空间。状态空间的大小可以是有限的,也可以是无限的。 -
表示初始状态 的分布。 -
表示所有动作(action)的集合,也称为动作空间。动作空间同样可以是有限的,也可以是无限的。 -
表示状态转移概率(state transition probability)。具体来说, 表示在状态 上执行动作 ,状态转移到状态 的概率。显然,对于任意 而言,都有 ,并且 。 -
表示状态转移过程的奖励函数(reward function)。 简记作为 ,表示在状态 上执行动作 后转移到状态 得到的数值奖励。 -
表示状态转移过程中的折扣系数(discount coefficient),通常在区间 中。
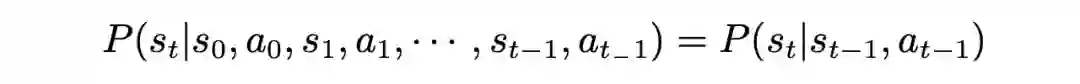


强化学习的优化目标

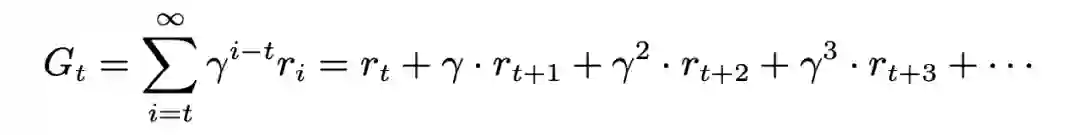

值函数和贝尔曼方程
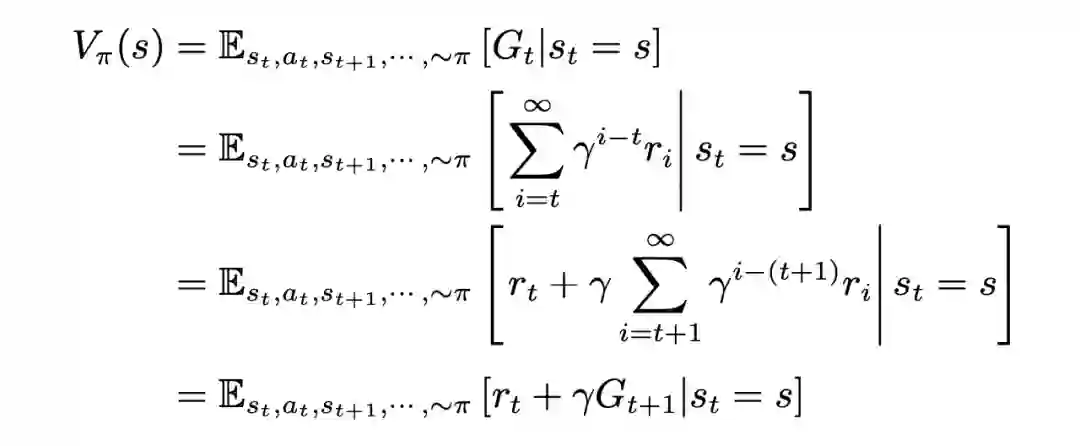
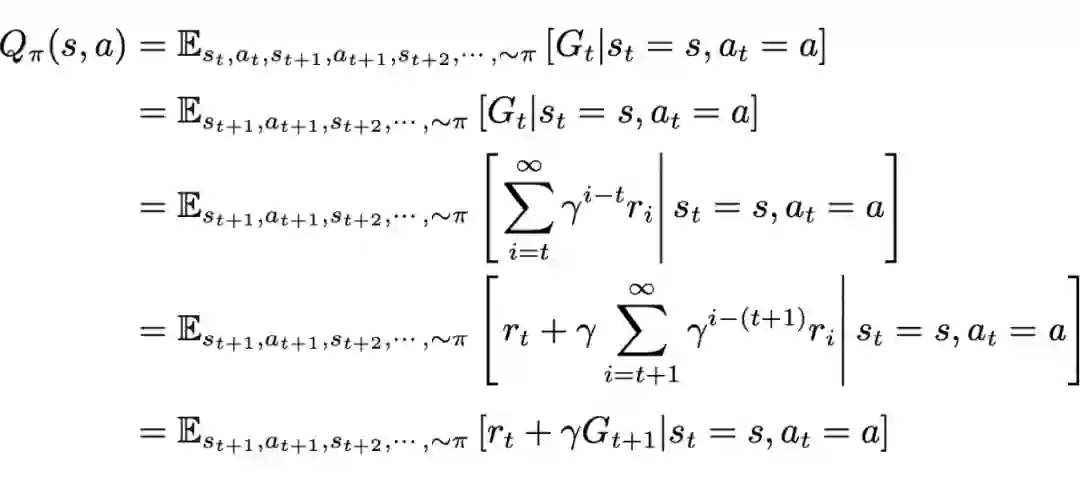
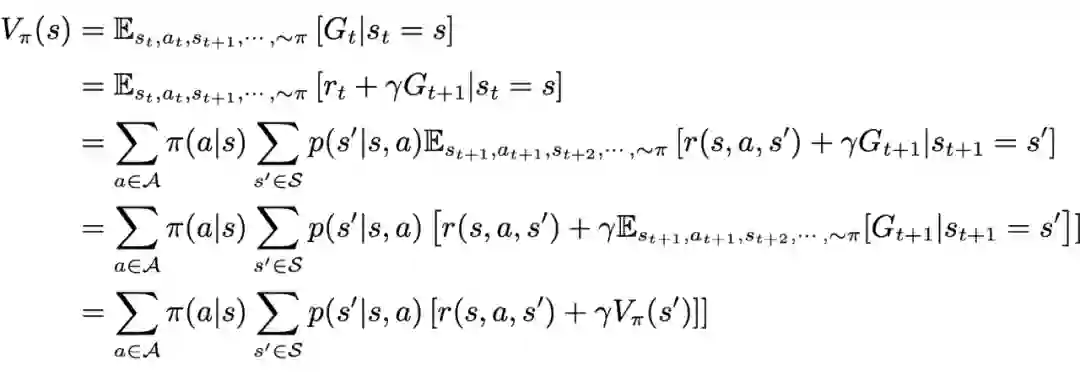
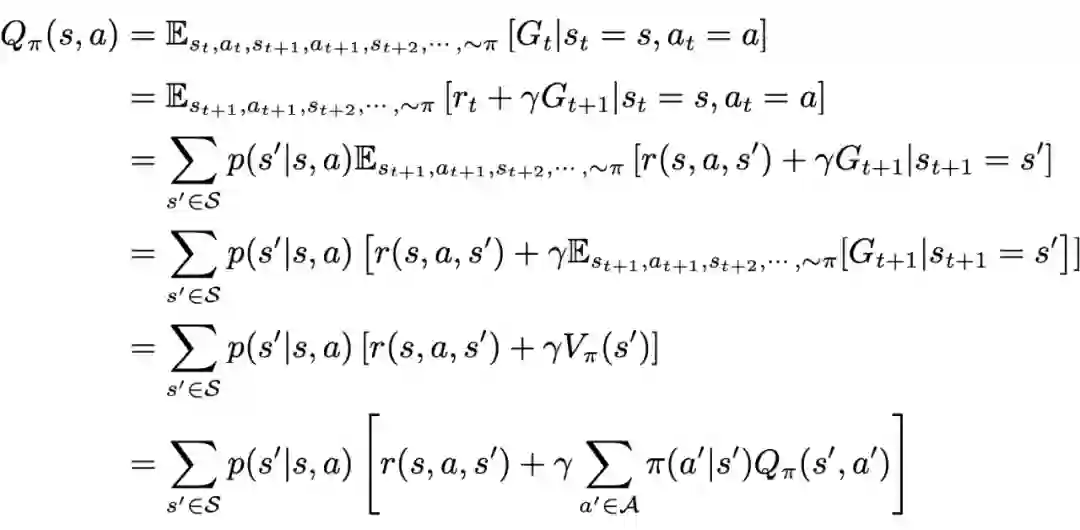
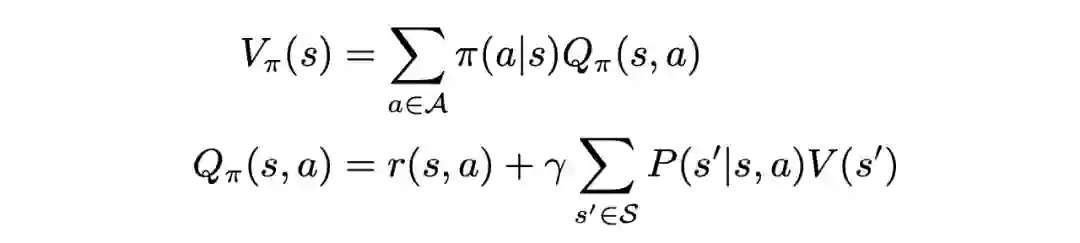

和
的探讨

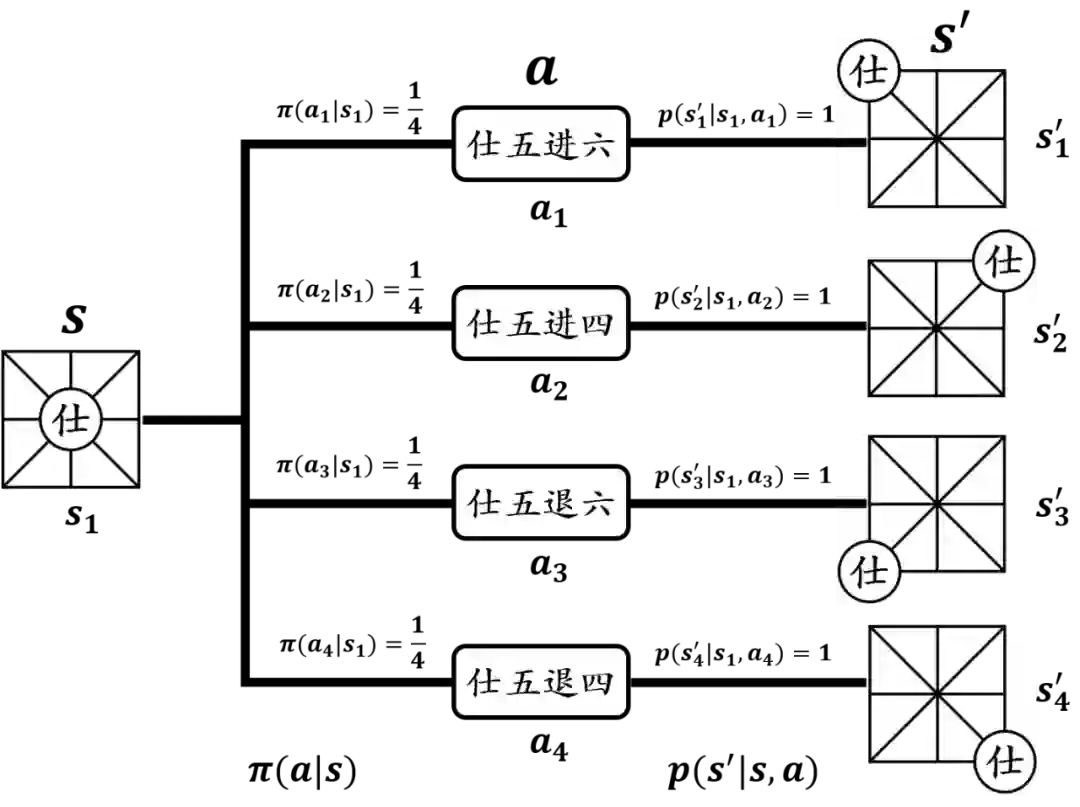
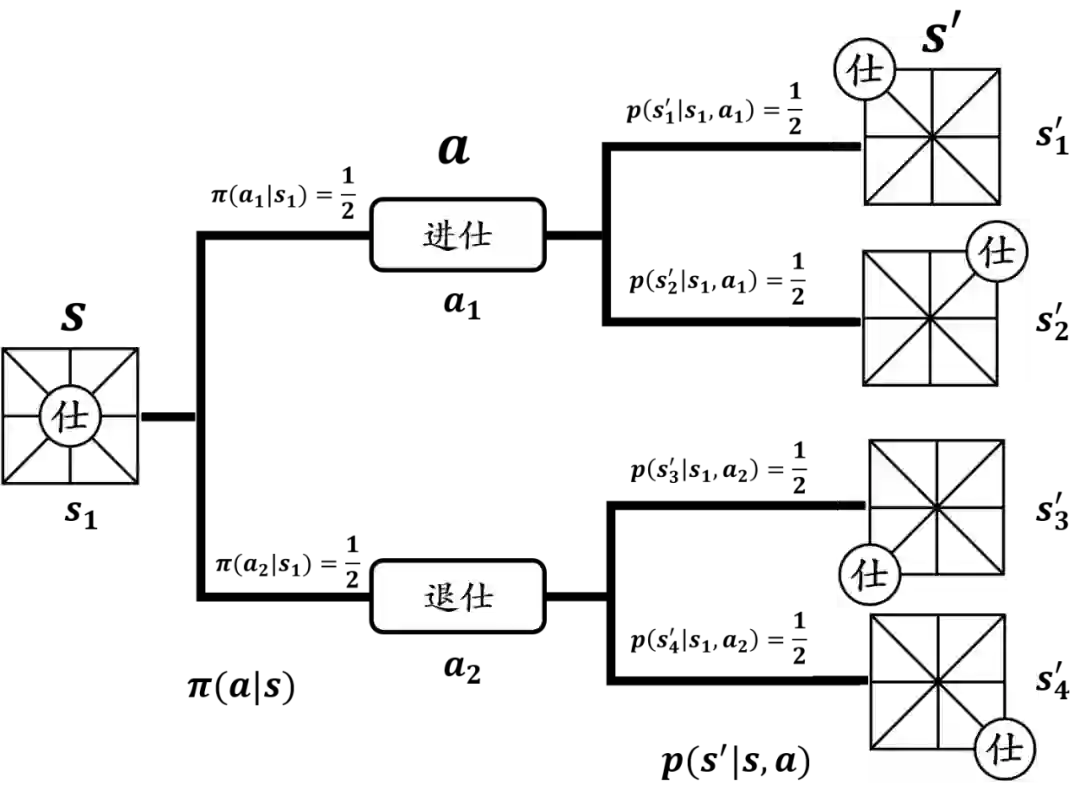

相关定理证明
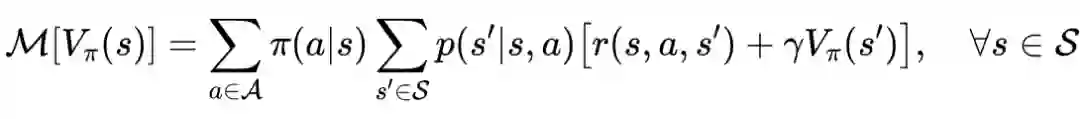
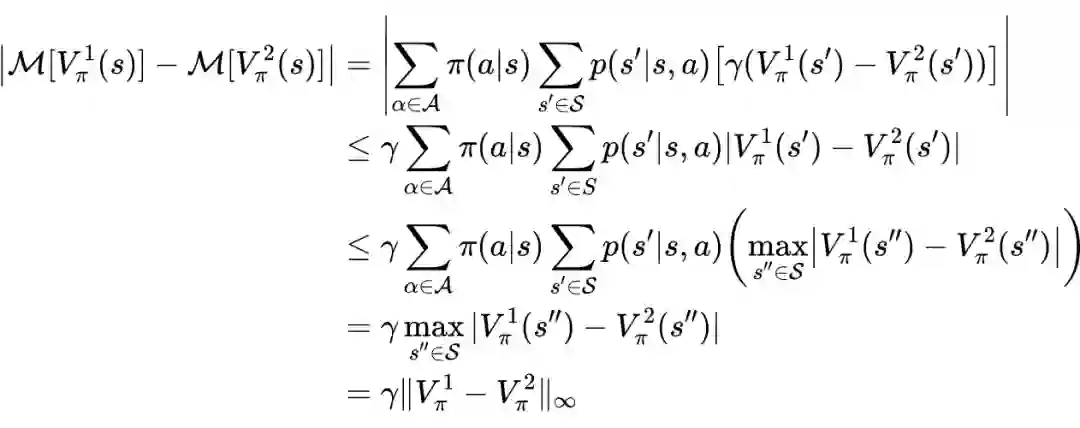
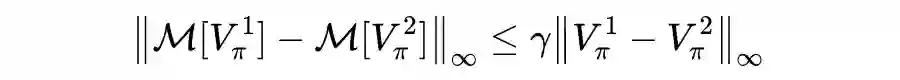
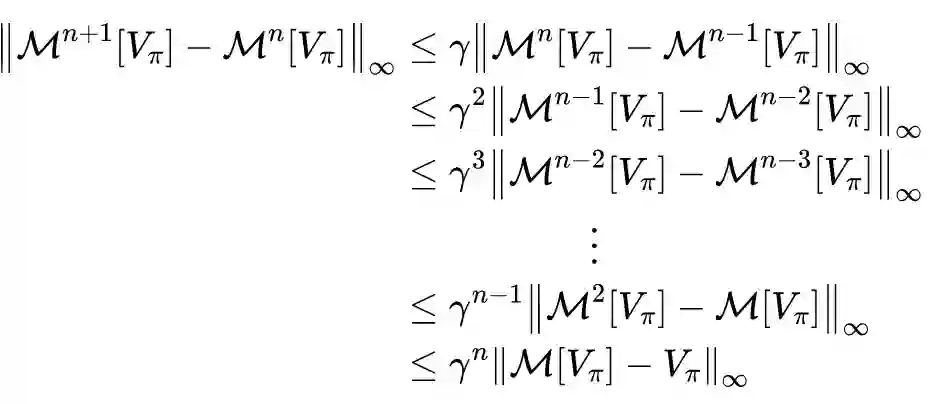
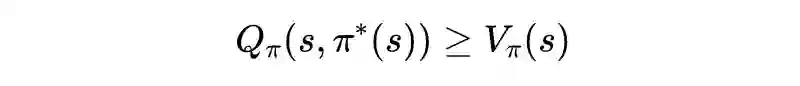
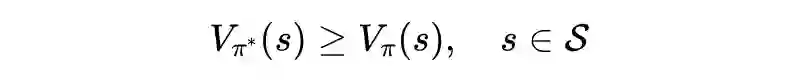
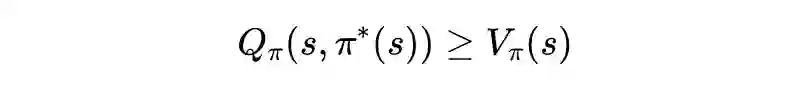
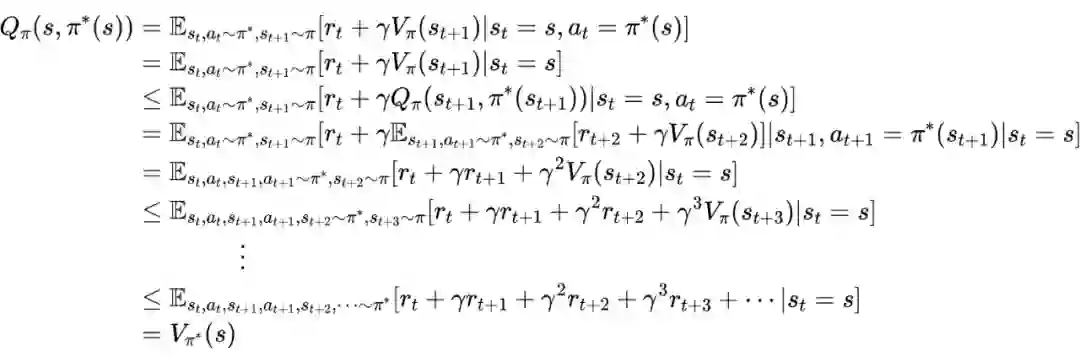
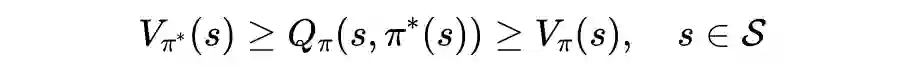
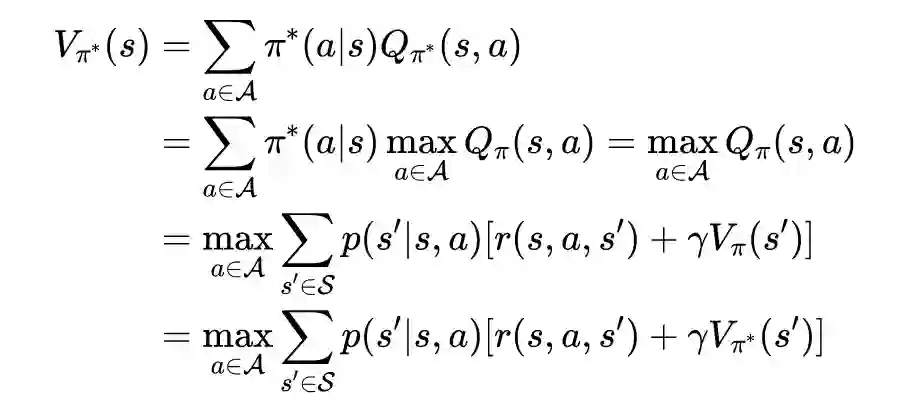
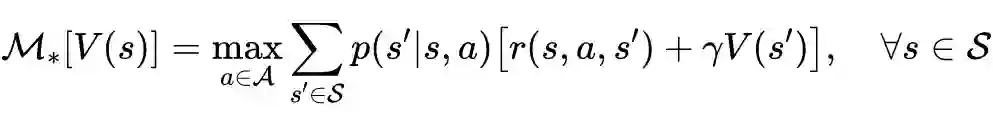
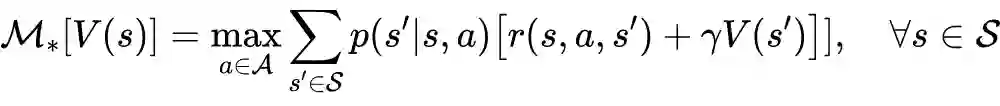
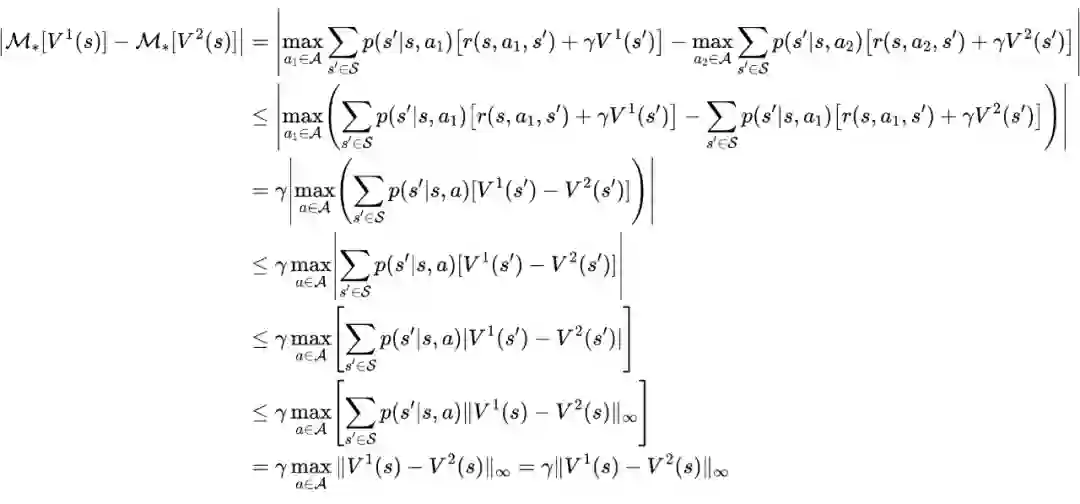
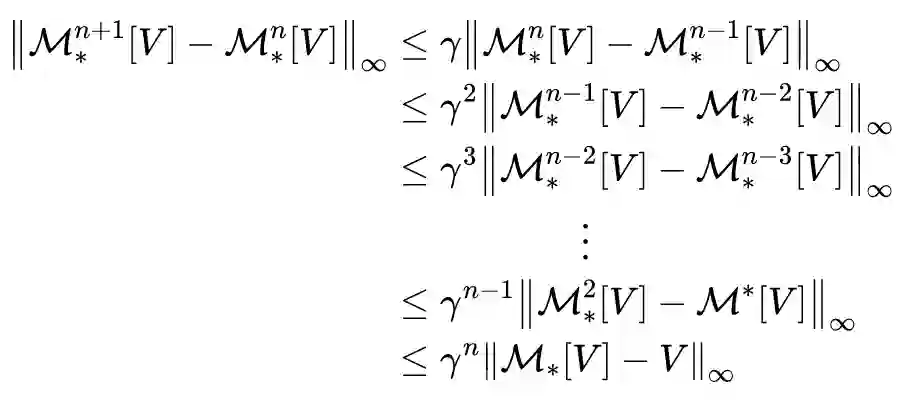

值迭代法介绍
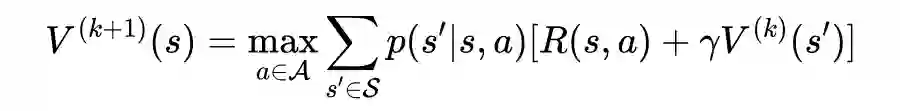
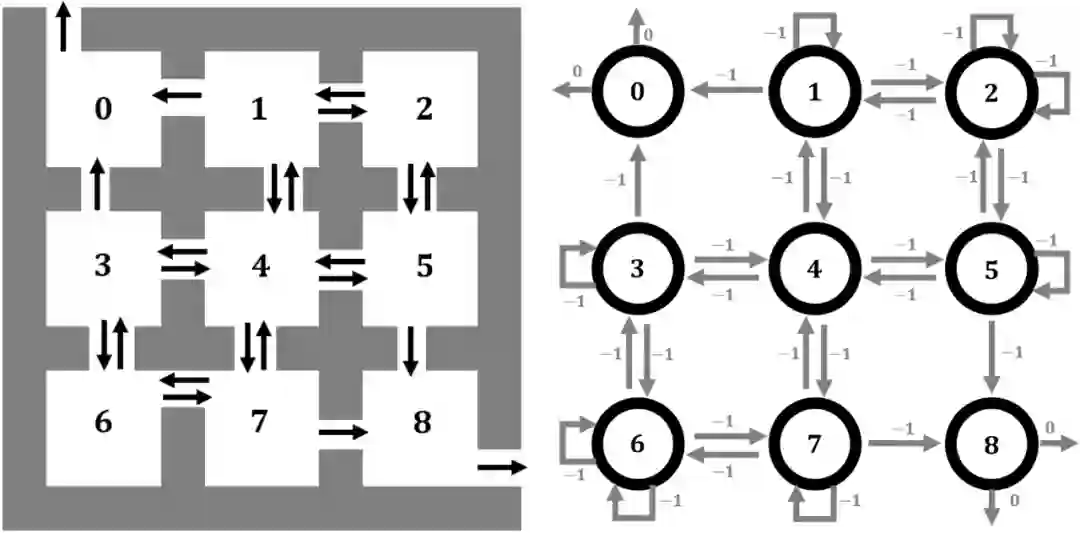
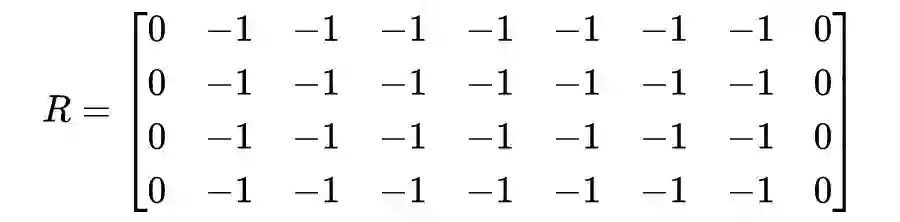
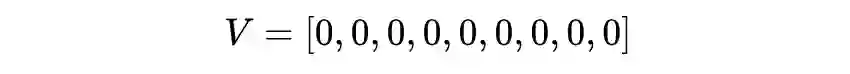
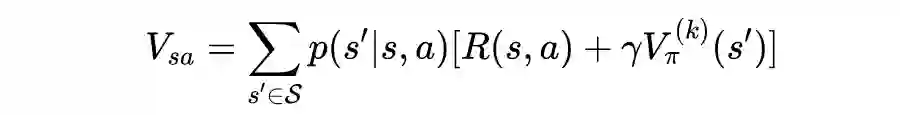
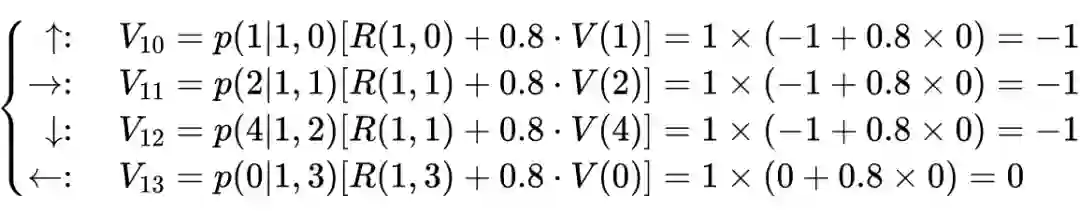
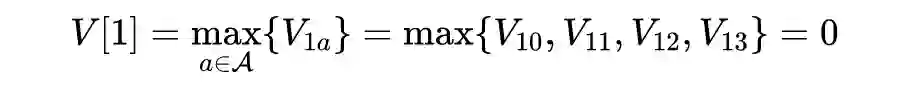
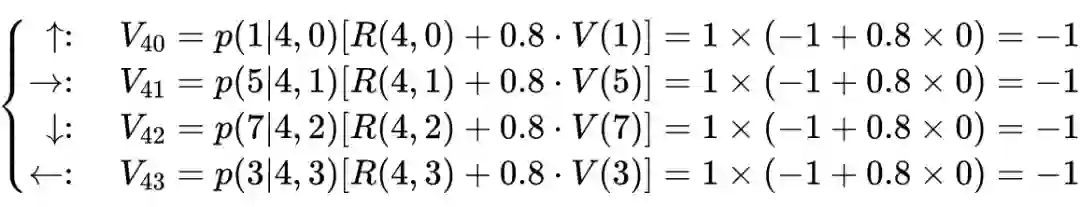
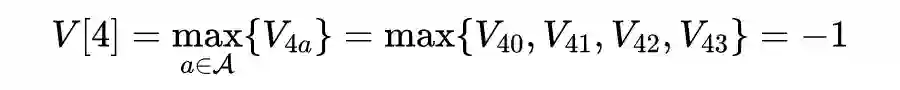
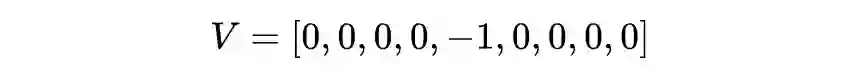
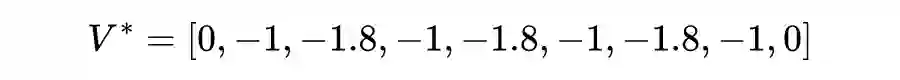
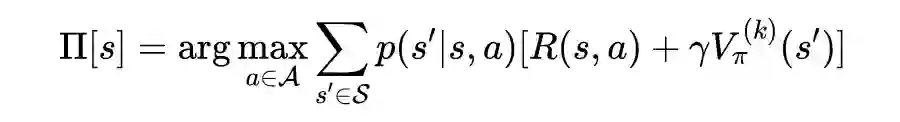
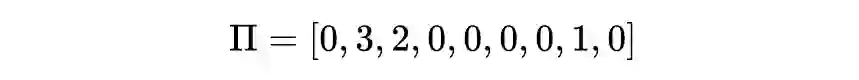
def state_value_iteration(env, theta=0.0001, discount_factor=0.8):
def one_step_action_choice(state, V):
A = np.zeros(env.nA)
for a in range(env.nA):
for prob, next_state, reward, done in env.P[state][a]:
A[a] += prob * (reward + discount_factor * V[next_state])
return A
V = np.zeros(env.nS)
while True:
delta = 0
for s in range(env.nS):
# find the best action
A = one_step_action_choice(s, V)
best_action_value = np.max(A)
# Calculate terminate condition
delta = max(delta, np.abs(best_action_value - V[s]))
# Update the value function
V[s] = best_action_value
# Check if we can stop
if delta < theta:
break
policy = np.zeros([env.nS, env.nA])
for s in range(env.nS):
A = one_step_action_choice(s, V)
best_action = np.argmax(A)
policy[s, best_action] = 1.0
return policy, V


- 原理介绍
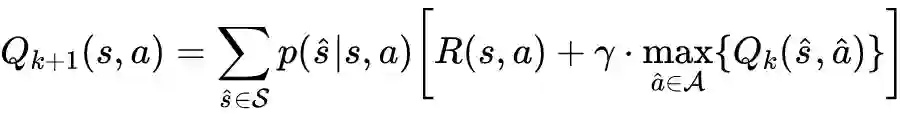
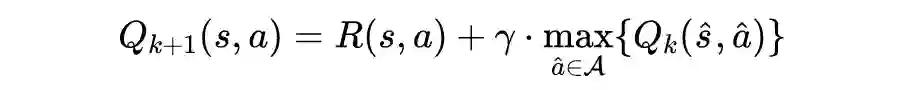

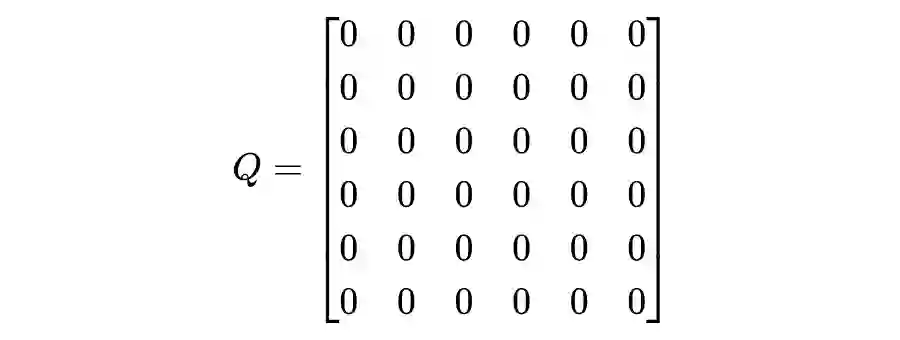
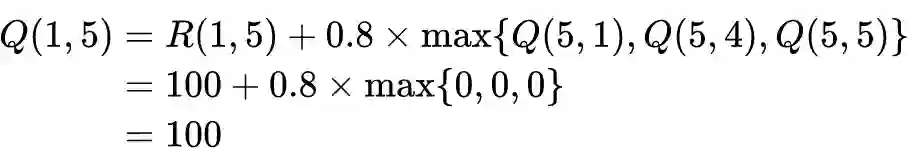

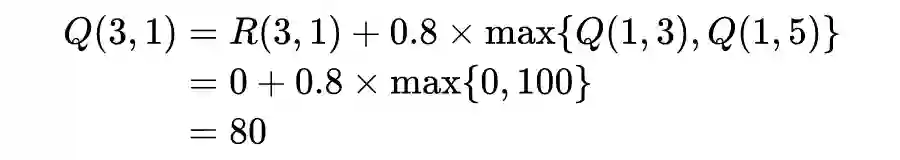

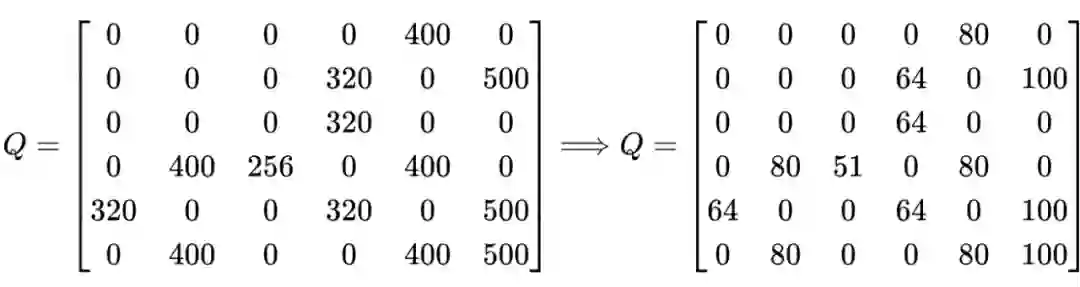
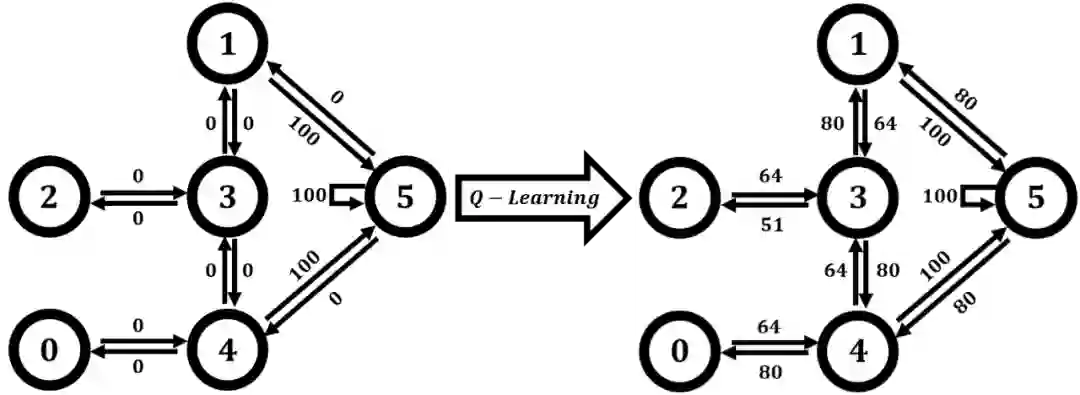
import numpy as np
import os
import random
def random_action(V):
index_list = []
for index, s in enumerate(list(V)):
if s >= 0:
index_list.append(index)
return random.choice(index_list)
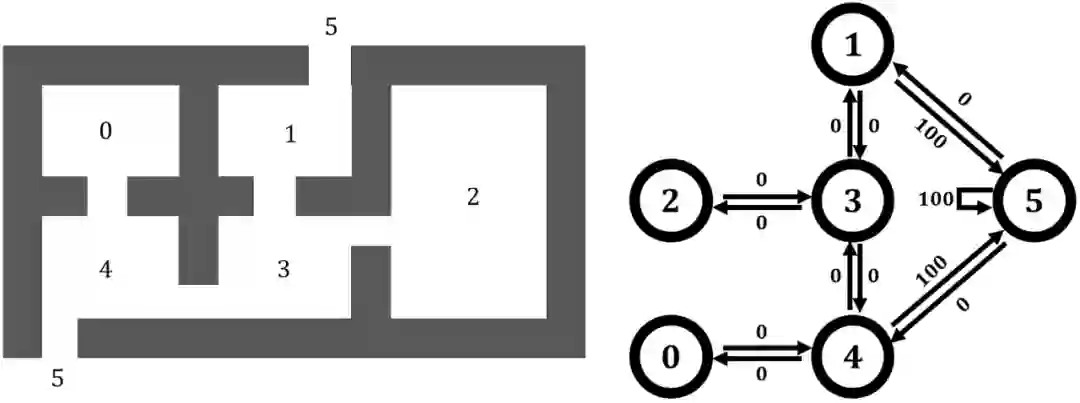
def reward_setting(state_num, action_num):
R = -1 * np.ones((state_num , action_num))
R[0,4] = 0
R[1,3] = 0
R[1,5] = 100
R[2,3] = 0
R[3,1] = 0
R[3,2] = 0
R[3,4] = 0
R[4,0] = 0
R[4,3] = 0
R[4,5] = 100
R[5,1] = 0
R[5,4] = 0
R[5,5] = 100
return R
if __name__ == '__main__':
action_num = 6
state_num = 6
gamma = 0.8
epoch_number = 200
condition_stop = 5
Q = np.zeros((state_num , action_num))
R = reward_setting(state_num , action_num)
for epoch in range(epoch_number):
for s in range(state_num):
loop = True
while loop:
# Obtain random action a
a = random_action(R[s,:])
# Calculate maximum Q value
q_max = np.max(Q[a,:])
# Bellman optimal iteration equation
Q[s,a] = R[s,a] + gamma * q_max
s = a
if s == condition_stop:
loop = False
Q = (Q / 5).astype(int)
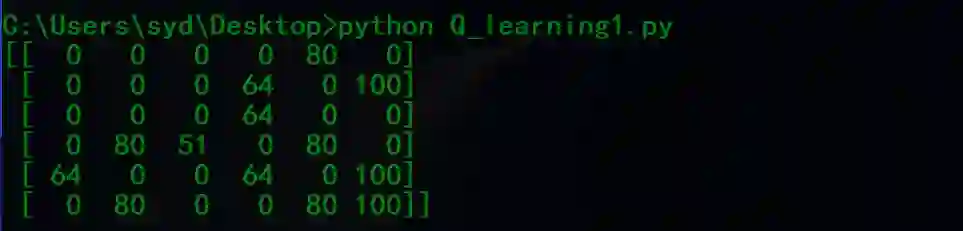
print(Q)
特别鸣谢
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧

登录查看更多
相关内容



相关VIP内容
相关资讯
相关论文