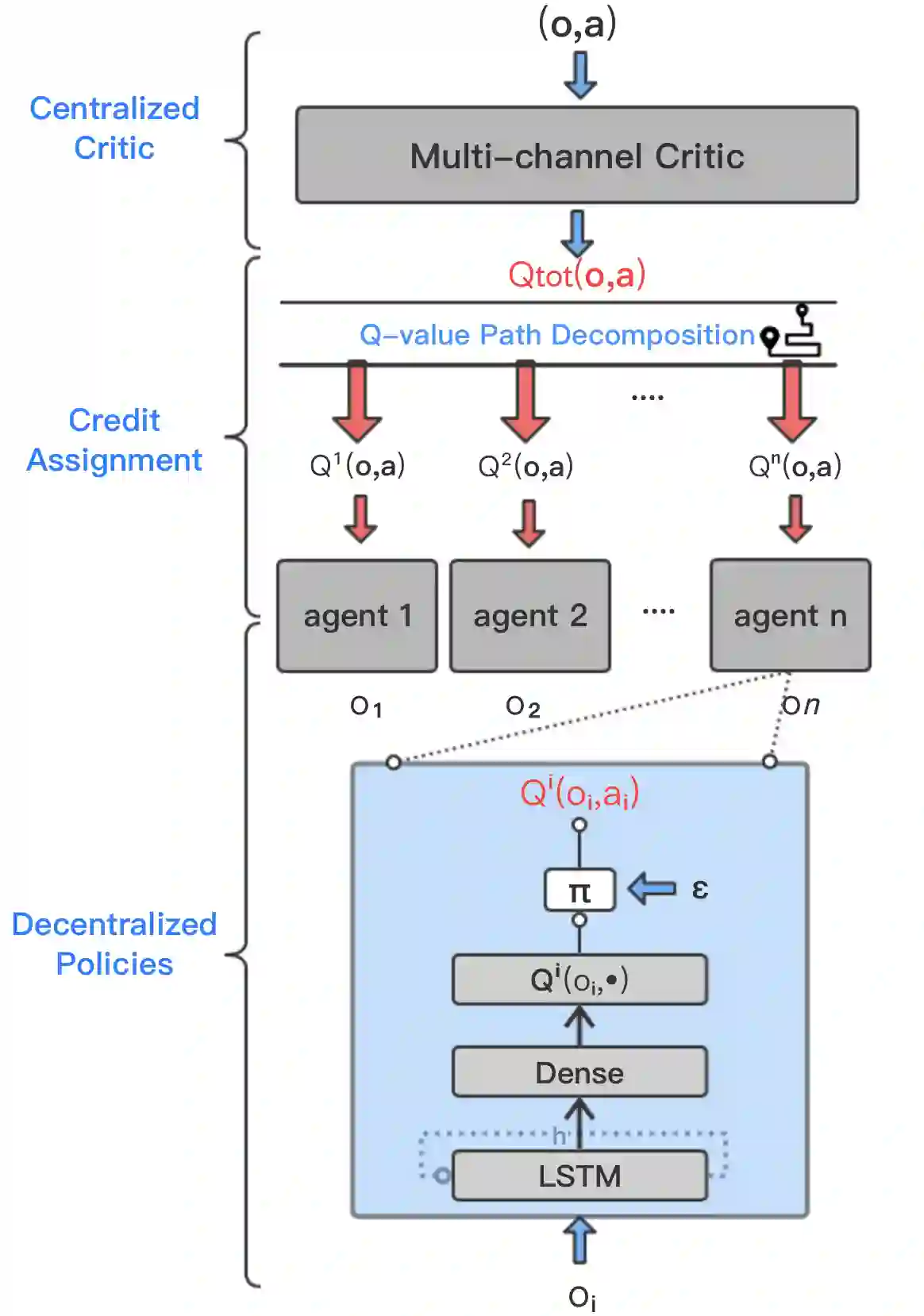
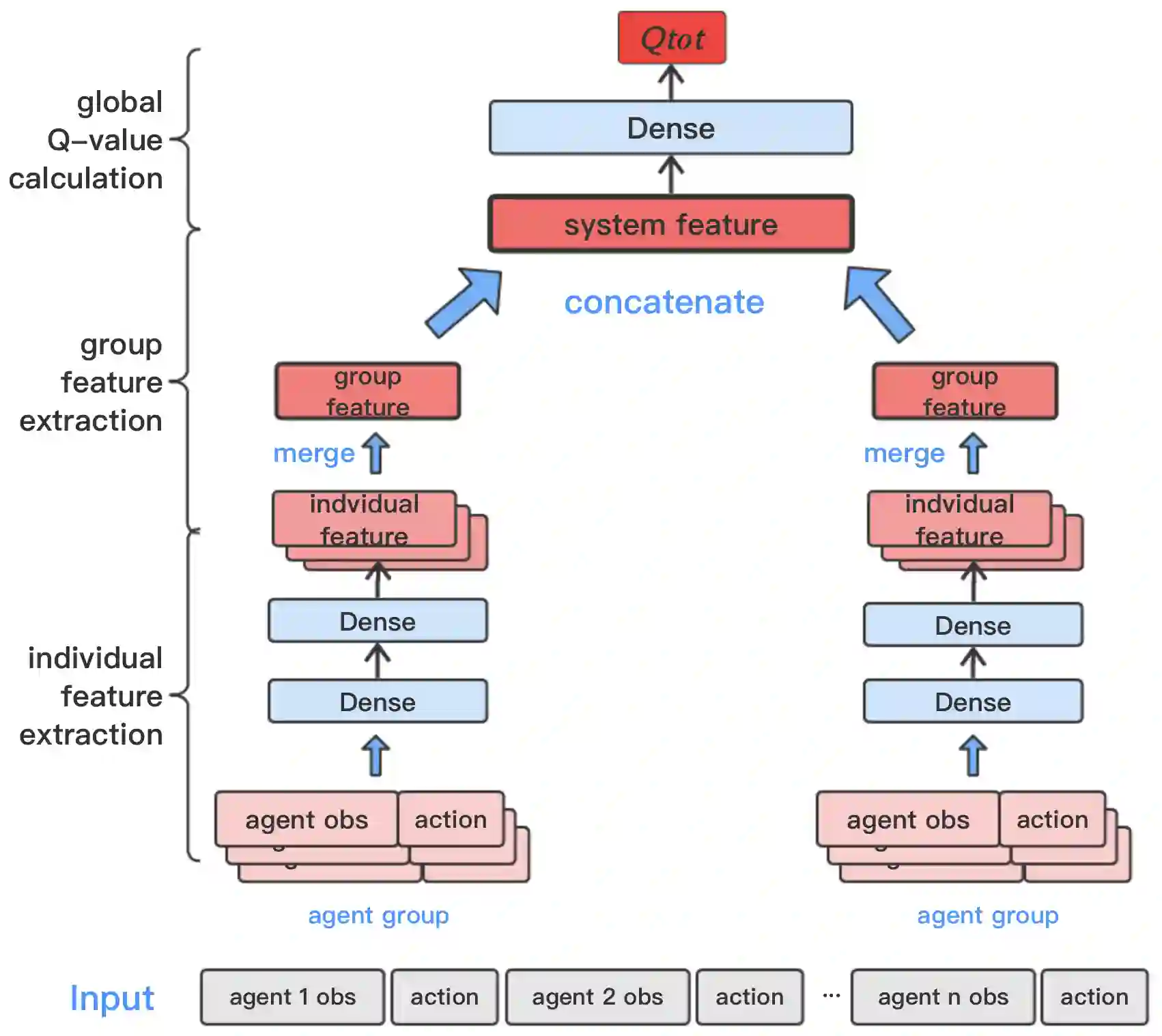
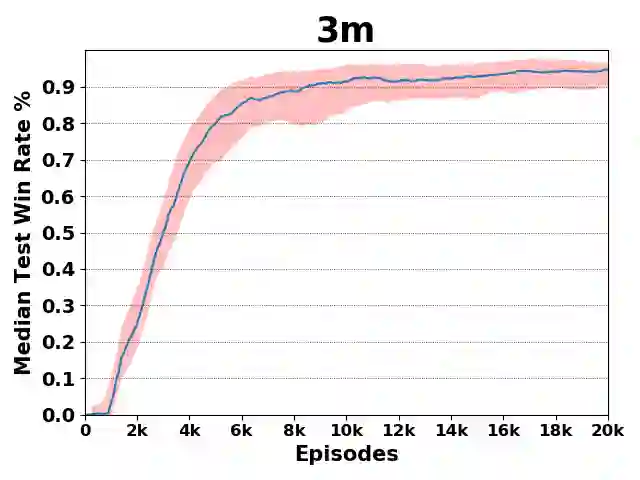
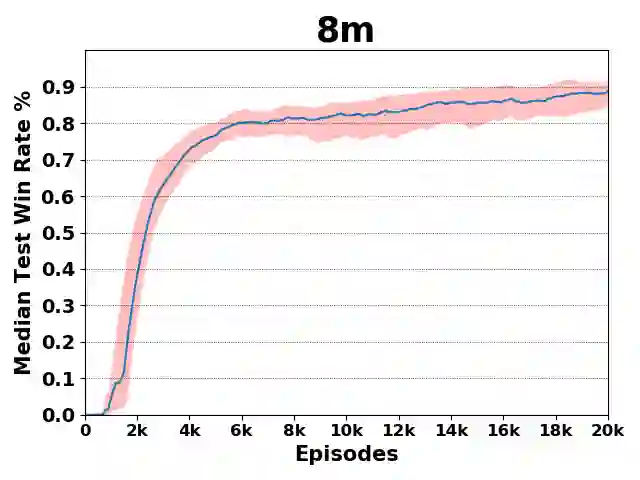
Recently, deep multiagent reinforcement learning (MARL) has become a highly active research area as many real-world problems can be inherently viewed as multiagent systems. A particularly interesting and widely applicable class of problems is the partially observable cooperative multiagent setting, in which a team of agents learns to coordinate their behaviors conditioning on their private observations and commonly shared global reward signals. One natural solution is to resort to the centralized training and decentralized execution paradigm. During centralized training, one key challenge is the multiagent credit assignment: how to allocate the global rewards for individual agent policies for better coordination towards maximizing system-level's benefits. In this paper, we propose a new method called Q-value Path Decomposition (QPD) to decompose the system's global Q-values into individual agents' Q-values. Unlike previous works which restrict the representation relation of the individual Q-values and the global one, we leverage the integrated gradient attribution technique into deep MARL to directly decompose global Q-values along trajectory paths to assign credits for agents. We evaluate QPD on the challenging StarCraft II micromanagement tasks and show that QPD achieves the state-of-the-art performance in both homogeneous and heterogeneous multiagent scenarios compared with existing cooperative MARL algorithms.
翻译:最近,深入的多剂强化学习(MARL)已成为一个非常活跃的研究领域,因为许多现实世界的问题可以被视为多剂系统。一个特别有趣和广泛应用的问题类别是部分可见的合作多剂环境,其中一组代理人学会以私人观察和共同分享的全球奖励信号来协调他们的行为;一个自然的解决办法是采用集中培训和分散执行模式。在集中培训期间,一个关键的挑战就是多剂信用分配:如何分配全球奖励给个别代理人政策,以便更好地协调,实现系统一级的利益最大化。在本文中,我们提出了一种名为Q-价值路径分解的新方法,将系统的全球Q价值分解成单个代理人的Q值。与以往限制个人Q价值和分散执行模式代表关系的工作不同,我们利用综合梯度分化技术深入MARL,直接将全球Q值分解,沿着轨迹路径为代理人分配信用。我们在Star-Craft II微值分解定位(QPDS)中评估了具有挑战性的Star-Craft II微值的微管理任务和MARDRML的多级演算结果,我们用了现有的GPDML的成绩。