

摘要
先进的任务规划软件包(如 AFSIM)使用传统的人工智能方法,包括分配算法和脚本状态机来控制军用飞机、舰船和地面单位的模拟行为。我们开发了一种新颖的 AI 系统,该系统使用强化学习为军事交战生成更有效的高级策略。然而,它不是从头开始学习具有初始随机行为的策略,而是利用现有的传统 AI 方法来自动化简单的低级行为,简化问题的协作多智能体方面,并利用可用的先验知识引导学习以实现数量级更快的训练。
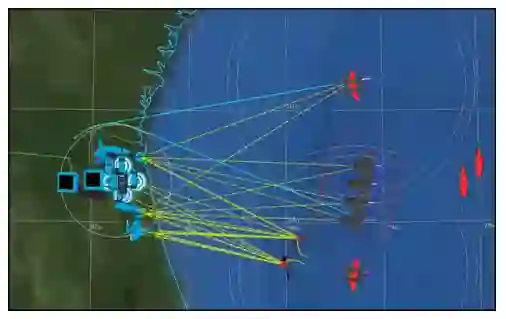
图 1 - 涉及空中、海上和地面单位的复杂 AFSIM 场景示例。分析师必须对所有这些平台进行建模,并使用基于规则的系统指定它们的行为。
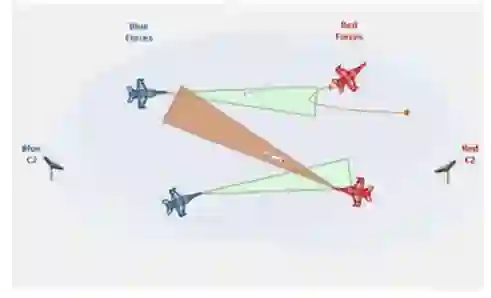
图 2 - 我们最初探索的 AFSIM 场景的概念图。许多红色和蓝色的战斗机被放置在地图上的随机位置。基线脚本 AI 用于控制红队,我们的新混合 RL 智能体学习击败红队的策略。
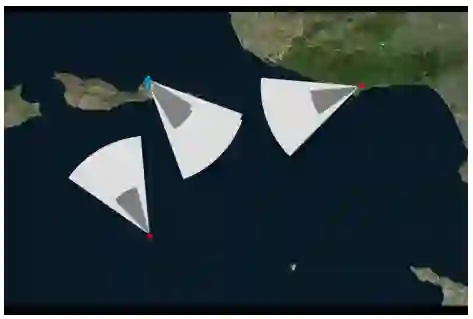
图 3 - 简化的 MA2D 环境,完全用 Python 编写。此示例包含两个蓝色战斗机和两个红色战斗机。深灰色区域代表每个单位的武器区域。目标是通过让每个对手进入该区域来摧毁所有对手,同时避免类似地摧毁友军飞机。这种简化消除了对导弹飞行建模的需要。
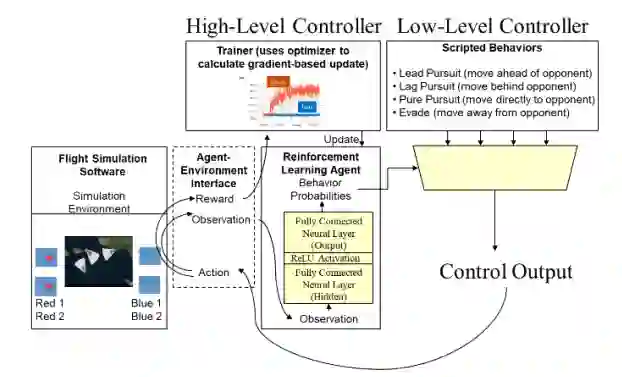
图 4 - 我们的混合架构概述,将高级强化学习器与低级脚本行为策略配对。强化学习代理选择脚本行为,然后生成发送到环境的实际控制输出。
成为VIP会员查看完整内容
相关内容

专知会员服务
24+阅读 · 2022年3月19日
Arxiv
0+阅读 · 2022年4月19日
Arxiv
0+阅读 · 2022年4月18日

相关VIP内容
专知会员服务
24+阅读 · 2022年3月19日
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月19日
Arxiv
0+阅读 · 2022年4月18日