
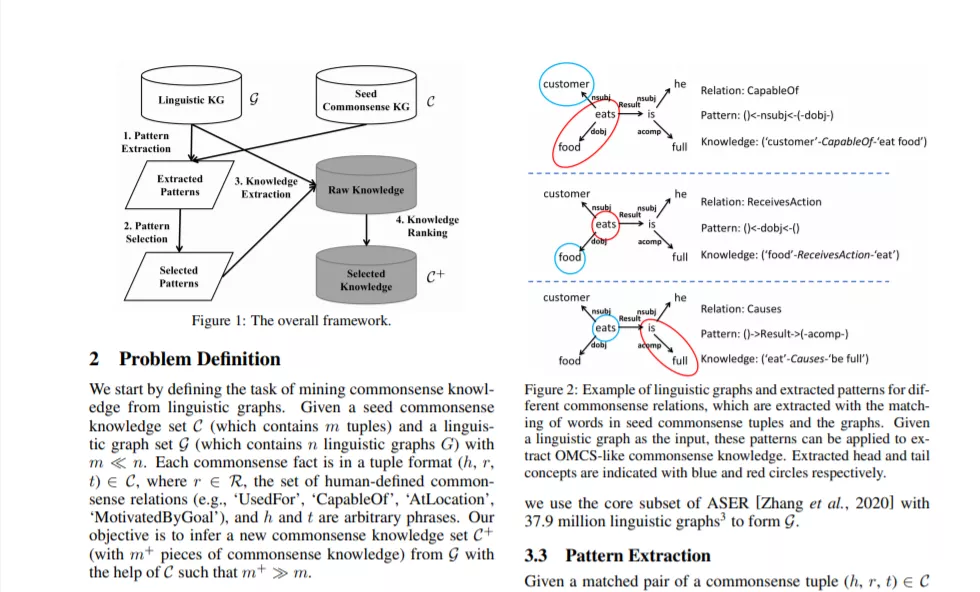
常识知识的获取是人工智能的关键问题。传统的获取常识的方法通常需要耗费大量人力和财力进行注释,而这在大规模的情况下是不可行的。本文探讨了一种从语言图形中挖掘常识性知识的实用方法,目的是将通过语言模式获得的廉价知识转化为昂贵的常识性知识。其结果是将大规模的选择性偏好知识资源ASER [Zhang et al., 2020]转换为与ConceptNet [Liu and Singh, 2004]具有相同表示的TransOMCS,但要大两个数量级。实验结果表明,该方法在量、新颖性、质量等方面都具有从语言知识到常识的可转移性和有效性。TransOMCS可通过以下网址访问
成为VIP会员查看完整内容
相关内容
专知会员服务
26+阅读 · 2020年5月6日
专知会员服务
47+阅读 · 2019年12月1日
专知会员服务
16+阅读 · 2019年10月25日
Arxiv
4+阅读 · 2019年12月12日
Arxiv
5+阅读 · 2018年7月23日
相关VIP内容
专知会员服务
26+阅读 · 2020年5月6日
专知会员服务
47+阅读 · 2019年12月1日
专知会员服务
16+阅读 · 2019年10月25日
相关资讯
相关论文
Arxiv
4+阅读 · 2019年12月12日
Arxiv
5+阅读 · 2018年7月23日