论文浅尝 | AMUSE: 基于 RDF 数据的多语言问答语义解析方法

来源:ISWC 2017
链接:https://link.springer.com/content/pdf/10.1007%2F978-3-319-68288-4.pdf
本文主要关注基于RDF数据的多语言问答任务中,对不同语言问句的语义分析工作。作者提出一种基于DUDES(Dependency-based Underspecified Discourse Representation Structures)的因子图推理方法,对多语言问句中的词进行角色定义和识别,并根据获取到的语义解析结果,规则生成问题的SPARQL。文中表示,使用因子图进行推理对语言类型的敏感程度较低,是一种有效的多语言语义解析方法。模型的性能评测基于QALD-6发布的英语,德语以及西班牙语数据。
动机
多语言问答是 QALD 提出的一个问答子任务,目标是将给定的多语言问题映射到知识库中或是得到对应的SPARQL。
例如:问句“Who createdWikipedia?” 目标生成的SPARQL为
SELECT DISTINCT ?uri WHERE { dbr:Wikipedia dbo:author ?uri .}
多语言问答的一个主要难点在于“语义鸿沟”,当问题语言与知识库语言不相同的时候,就无法直接生成有效的映射。虽然机器翻译模型可以实现语言之间的转换,但是存在两个明显局限:其一,现有的双语或者多语言平行问答语料数量不足以训练出高质量的机器翻译模型;其二,基于QALD定义的跨语言问答任务,语言的转换完全取决于对问题句子的转换,然而问句中可能包含部分噪声信息,影响翻译的效果。
为了解决语义鸿沟,作者提出了AMUSE——一个基于因子图推理的跨语言解析模型。
方法
AMUSE的方法主要由两步推理构成:
1. L2KB
这一步以实体链接为目标,将问题中的局部与知识库相关联
2. QC
利用 L2KB 的链接结果,以及问题中的主要关键词的词类/词性等因素,构建问句的逻辑表达形式(SPARQL)
关键技术:DUDES(Dependency-based Underspecified Discourse Representation Structures),一种用于指定意义表示及构成的结构化方式。
模型流程如图 2 所示,这里为了方便读者阅读,作者以英语问题为例子来表现推理过程,使用其他语言的过程也是一样。
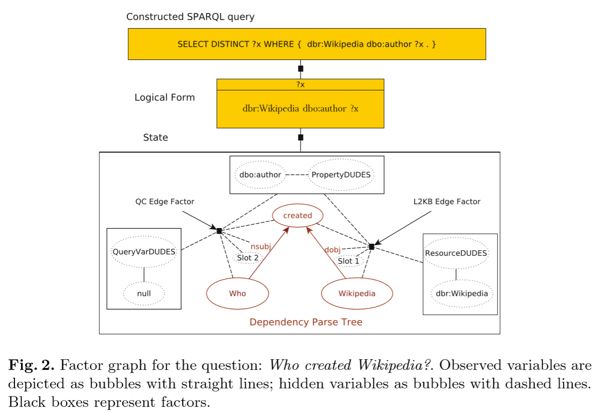
描述如下:
1. 输入问句为“Who created Wikipedia”,首先得到对应的依存解析树
2. 对问句中的词进行 L2KB 推理过程,找到 Wikipedia 链接到的知识库中实体:Wikipedia,以及 created 链接到知识库中的属性:author,细节如图3,此时的结果构成的部分SPARQL成分为:

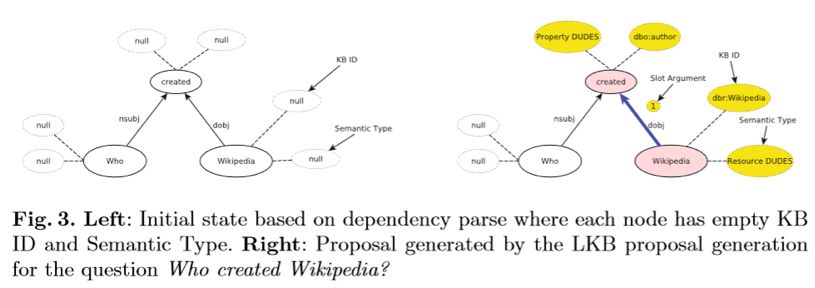
3. 进入 QC 推理过程,根据问句中各词的词性,及依存关系,给出问句中疑问词的推理标签,此时完成 SPARQL 构成如:
SELECT DISTINCT ?y WHERE { dbr:Wikipedia dbo:author ?y .}
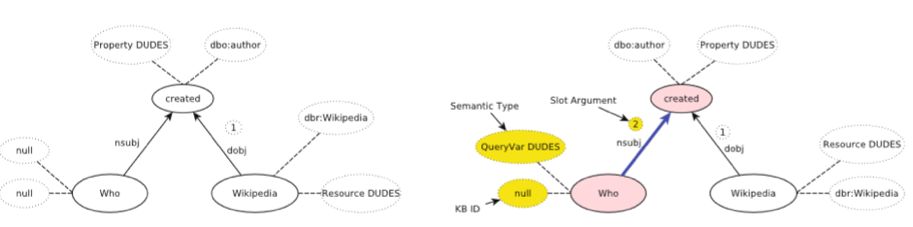
对于问题语言与知识库不相同的案例,作者提出的处理方式是利用多语言词典 Dict.cc 的词级别翻译配合 word embedding 检索找到知识库中可能的目标实体。
实验
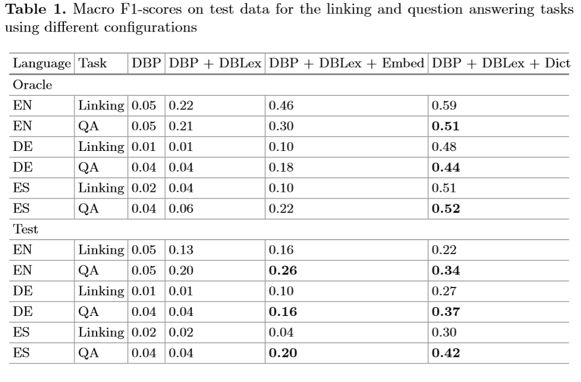
文章表示,由于本工作是首个多语言语义解析器,为了测试模型性能,作者构建了多种词典+word embedding 的组合,分别在英,德,西班牙语上进行 Linking 与 QA 的两组实验,评价指标为 F1 值,结果如表 1:
总结
文章的主要贡献在于提出了一个具备语言通用性的语义解析方法,并且在QALD的定义下,提出了一种词典+embedding相似性检索的方式应对语义鸿沟(用于应对没有平行语料训练翻译模型的情况)。
论文笔记整理:谭亦鸣,东南大学博士生,研究兴趣:知识问答,自然语言处理,机器翻译
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。



