【ACL2019】富有知识又鲁棒的自然语言表示学习方法
【导读】你的深度学习表示,对不同的任务(QA,对话生成,推理)来说,是否鲁棒?对抗训练能带来鲁棒性么?怎么样改进才能是学到的表示更鲁棒?怎么定量评价一个模型的鲁棒性?前些日子,在ACL2019的表示学习workshop上,来自UNC-NLP实验室的Mohit Bansal 做了关于《Knowledgeable and Adversarially-Robust Representation Learning》的talk,对深度学习表示的鲁棒性进行了系统分析。
【Talk简介】
在这次演讲中,我将讨论关于自然语言处理和生成的富有知识和鲁棒的表示学习的工作。首先,我将描述我们过去的工作,即将语法、意译和多语言知识合并到不同粒度语言形式的嵌入中。接下来,我将介绍我们最近的多任务学习和强化学习方法,利用辅助的知识技能任务,如entailment, saliency, video generation,self-learning等,以及这些辅助任务的选择。我们还将讨论使用外部常识性知识来学习如何填补多跳生成式QA中的推理空白的模型。最后,我们将讨论如何分析NLP模型对抗训练的失败的问题,以及如何推进文本对抗训练,例如,在QA中跨越干扰,在多跳QA中推理捷径,在对话模型中过度敏感和过度稳定,在NLI模型中合成不敏感等问题。
【作者简介】
Mohit Bansal 博士是北卡罗来纳大学NLP实验室(nlp.c.s. unc.edu)主任,也是北卡罗来纳大学教堂山分校(UNC Chapel Hill) CS专业的助理教授。在此之前,他是芝加哥理工大学的助理教授。他在加州大学伯克利分校获得博士学位,在印度理工学院坎普尔分校获得BTech学位。他的研究专长是统计自然语言处理和机器学习,特别关注多模态、具体语义,类人语言生成和问答/对话,以及可解释和泛化的深度学习。曾获得2019 Google Focused Research Award, 2018 ARO Young Investigator Award, 2017 DARPA Young Faculty Award, 2017 ACL Outstanding Paper Award, 2014 ACL Best Paper Award Honorable Mention, and 2018 COLING Area Chair Favorites Award。他也是CoNLL 2019的 Program Co-Chair.
【部分PPT】









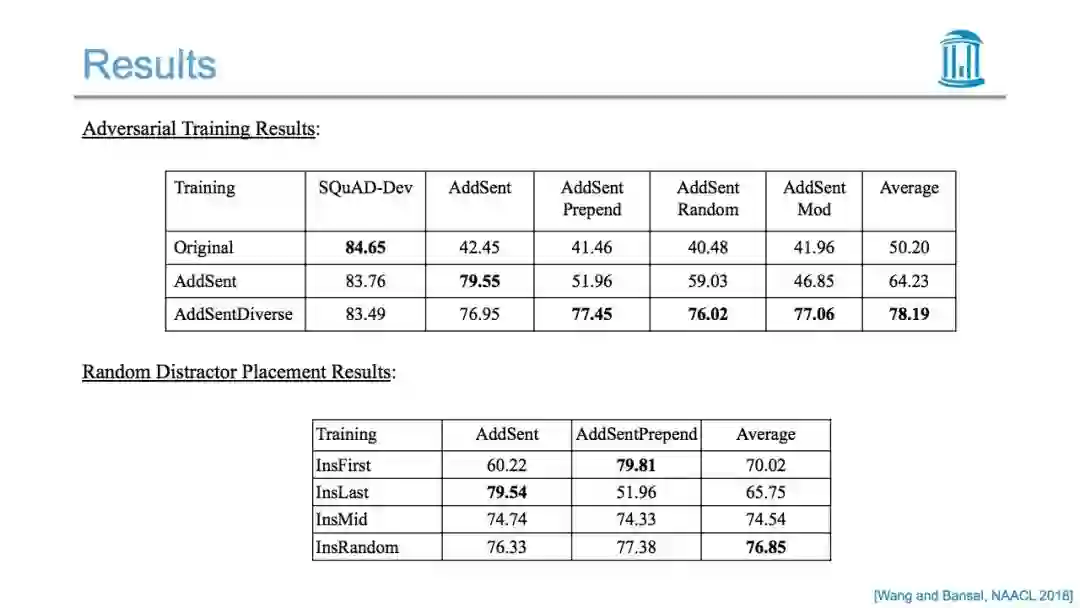
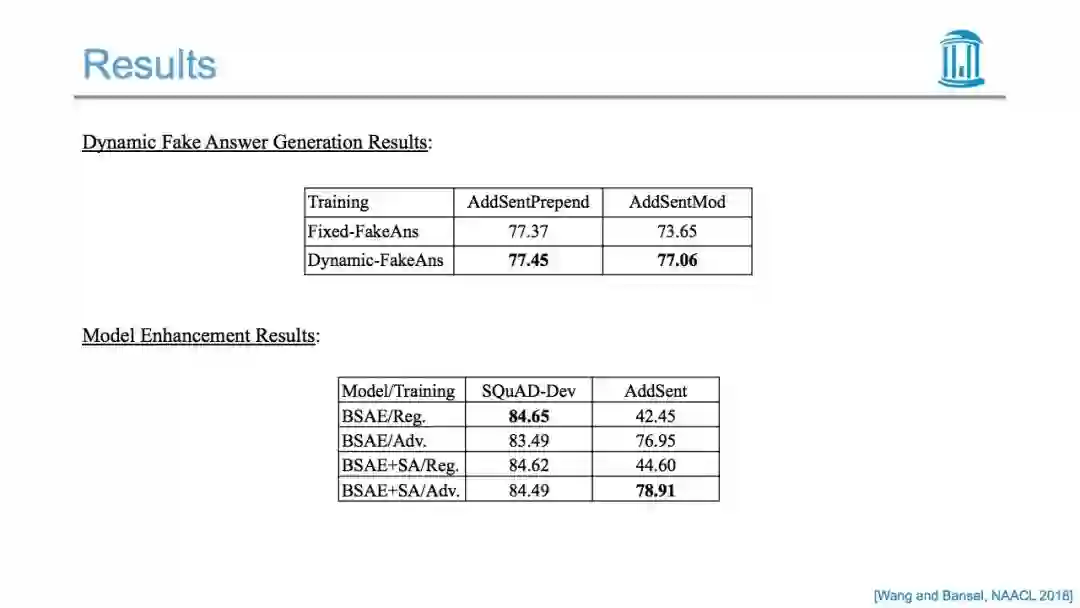







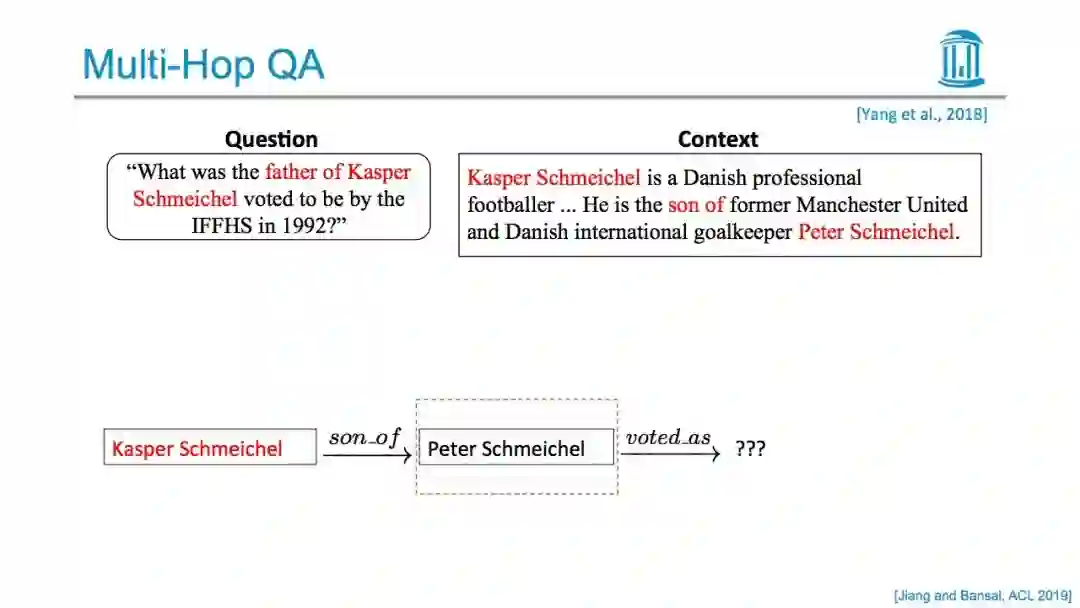

更多内容,请关注专知公众号(点击上方蓝色专知关注)
后台回复“KRRL” 就可以获取完整版PPT下载链接~
-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!560+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程



