赛尔原创 | IJCAI 2018 利用跨语言知识改进稀缺资源语言命名实体识别
本文介绍哈尔滨工业大学社会计算与信息检索研究中心(HIT-SCIR)录用于IJCAI 2018的论文《Improving Low Resource Named Entity Recognition using Cross-lingual Knowledge Transfer》,在稀缺资源语言实体识别任务中,我们在原有LSTM-CRF模型的基础上,利用双语词典作为跨语言信息传播桥梁,为每个稀缺资源语言词语学习英文语义空间下的语义表示,并映射到稀缺资源语言空间增强原有表示。在西班牙语、荷兰语和中文三种语言数据集上进行实验,结果显示,通过加入跨语言信息表示,实体识别性能平均提高大于3%。本论文的数据和代码;https://github.com/scir-code/lrner
论文作者:冯骁骋、 冯夏冲、 秦兵、 刘挺
关键词:命名实体识别,稀缺资源语言,LSTM-CRF,知识表示
联系邮箱:xcfeng@ir.hit.edu.cn
个人主页:http://ir.hit.edu.cn/~xcfeng/
1. 引言
命名实体识别是信息抽取中一个最为重要的子任务,并且该任务可以为后续信息抽取任务 (关系抽取、事件抽取和实体消歧) 提供帮助。实体识别的目的是从文本中识别出事物的名称并进行分类,例如最常用的人名、地名和机构名。传统的命名实体识别方法大多采用有监督的机器学习模型,如支持向量机和条件随机场模型。尽管这些方法取得了相对较好的结果,但是这类方法严重依靠于训练数据的大小以及特征表示的好坏;此外还有一些基于神经网络的方法,该类方法可以从文本中自动选择特征,并且实验效果更优。
早期的研究人员指出,不同的语言间包含完整的实体语义线索。基于这一真实假设,本论文提出一种利用辅助语言的语义信息去提高目标语言实体识别结果的神经网络模型。特别地,本文通过利用不同语言间的翻译词典 (目标语言到辅助语言) 建立起了不同语言之间的桥梁,不仅可以进行语义层面的特征传递,还可以将实体类型分布特征进行有效的传输。例如,图1句子中的 “本” 字,虽然经常在 中文中使用,但是很少作为名字姓氏出现,因此模型在判断的过程中很难对其进行正确分类。然而 “本” 的英文翻译 “Ben” 却经常在英文中当作姓名出现,因此,如果在考虑“本” 的时候能同时考虑其英文语义将有助于模型进行判断。
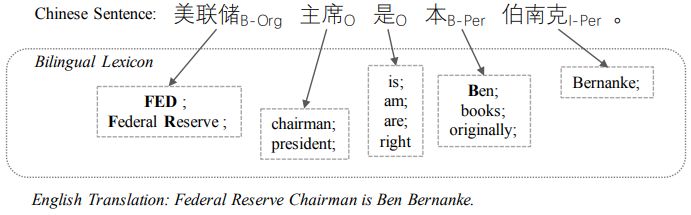
图1: Example of NER labels with bilingual lexicon.
2. 方法
基于之前利用跨语言(双语词典)知识帮助目标语言实体识别任务的动机,本节介绍一个通用的跨语言表示学习框架,去增强目标语言的语义表示。具体而言我们将首先介绍一下当前最好的实体识别模型LSTM-CRF模型,之后在此基础上学习当前语言的跨语言词典表示,然后考虑到词典覆盖率问题,去额外建模一个映射函数学习没有词典翻译的词语的跨语言表示,最后再学习在目标语言和辅助语言中各个词汇的的实体类型分布表示,将其作为额外特征加入到模型中。
2.1 LSTM-CRF
本节中,我们采用LSTM-CRF作为我们的基础模型,并在此基础上进行扩展。该网络由两个长短期记忆网络组成,一个前向记忆网络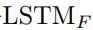
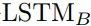
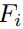
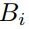
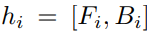

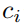

图 2: Main architecture of LSTM-CRF Model.
CRF
对于实体识别任务而言,一个简单且有效的方法就是将学到的每一个词的隐层表示作为特征输入到最终判别器中,之后对每一个词打出相应的标签。在神经网络模型中,最常用的方式就是将该隐层映射到所需分类的特征维度,之后选取概率最大的一维作为其实体类别,该方法也称之为softmax。尽管该模型在独立的序列标注任务中取得了成功,例如词性标注,但是该模型忽略了标签间的依赖关系,这一缺点导致了部分精度的损失。实体识别任务存在某些内在限制,例如I-PER 标签并不能接在B-LOC标签的后边。因此,有人提出用条件随机场模型(CRF)来学习标签之间的关系,而不是进行独立的标注。输入一句话X和对应的标签Y,
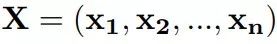
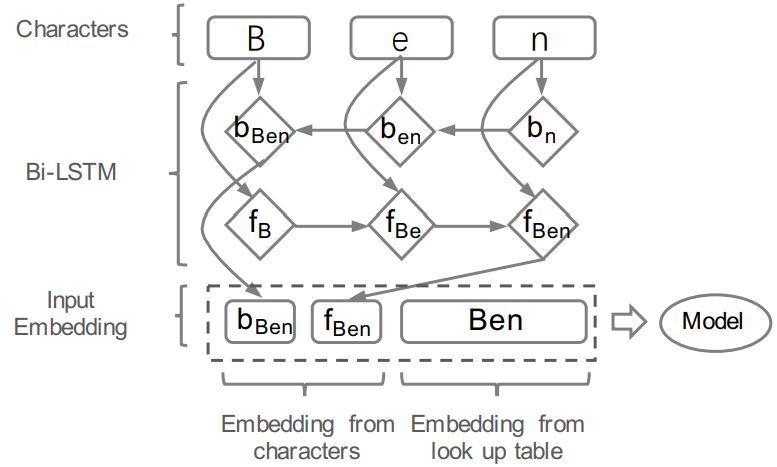
图 3: The character embeddings of the word “Ben” are given as input to a bidirectional LSTM.
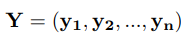
根据CRF模型定义其打分函数为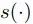

其中
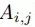

在测试阶段,我们根据其最大分类概率来确定其实体类别:
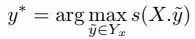
BIO标注体系
对于实体识别任务而言,其目的是给输入的文本中每一个词打一个对应的标签。一个实体可能由多个单词组成,因此有专家设计了BIO标注体系,其中B是beginning(开始)的缩写,I是inside(中间)的缩写,O是outside(非标签)的缩写,将每个单词标注为其中一种,例如图1所示,"美联储''只由一个词构成,并且为机构,因此标注为"B-Org'',而"本 伯南克''由两个词构成,所以"本''标注为"B-Per'',"伯南克''为"I-Per''。其它词均为"O''。
2.2 双语词典语义表示
在本节中,我们将介绍两种方法去学习目标语言词语在辅助语言语义空间的表示,可以简化为学习中文词语在英文翻译词典上的语义表示,具体而言,分为基于LTSM表示和Attention表示。基于LTSM表示的学习方法是指将词典中某个中文词的不同翻译随机组成一个序列,之后用一个双向LSTM模型去建模,最终将两个隐层的表示串联作为跨语言知识表示
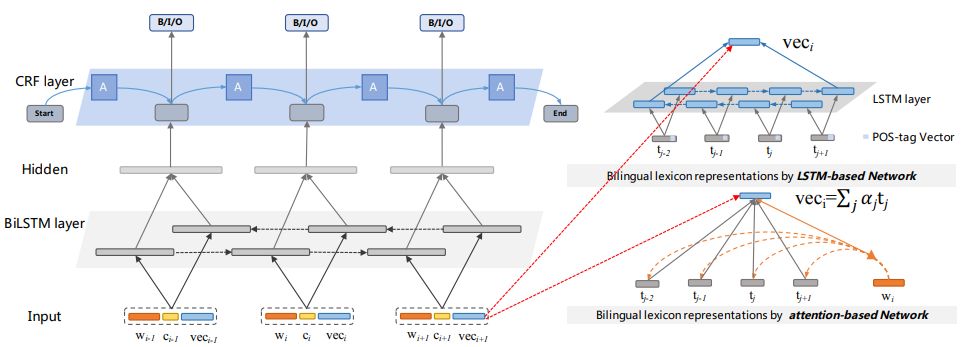
图 4: The character embeddings of the word “Ben” are given as input to a bidirectional LSTM.
2.3 基于映射的双语词典表示策略
在上一节中,我们介绍了如何利用双语词典去学习跨语言的词汇表示
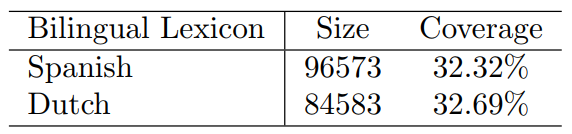
表 1: Bilingual Lexicons used in our experiments on Spanish and Dutch.
为了解决这一问题,我们提出了一种基于线性映射函数的解决策略,利用具有双语翻译的词汇去学习一个由目标语言表示到辅助语言空间的映射函数,之后将那些没有翻译的词汇利用这一映射学习其跨语言表示。具体公式如下:
其中M是映射矩阵,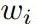

在我们获得矩阵M之后,对于没有翻译的目标语言词汇
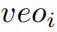

2.4 实体类型分布特征表示学习
在本节中我们将介绍如何学习词汇的实体分布特征,该特征可以理解为某一词汇成为某一实体的可能性,该特征是一种语言无关的特征,因此我们可以从目标语言和辅助语言两个空间进行学习。并且该特征可以一定程度上帮助我们去进行实体识别,因为通过向量化的词汇表示其可以自然的去计算某一相似度,而且word embedding之间保持某些语义特性,例如我们对人名、地名和机构名各学习一个表示,则自然而然的知道 "Microsoft''距离机构的表示应该更近,而"Bill Gates''距离人的表示更近, 我们希望学习词汇的实体分布特征并将其用于实体识别模型中。具体计算过程如图5所示,
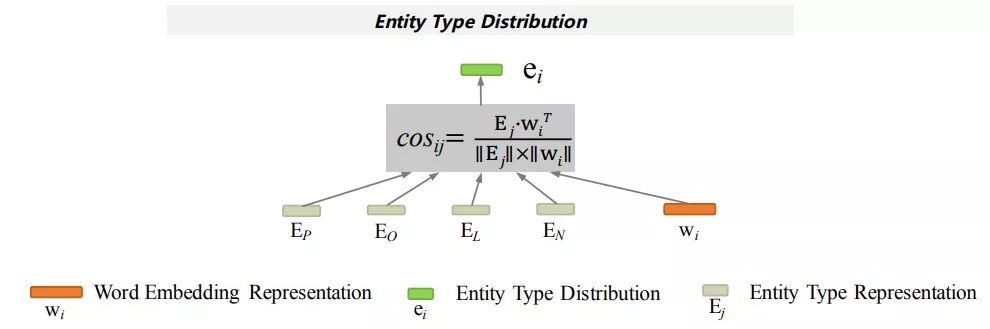
图 5: The architecture of Entity Type Distribution.
其中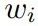


图 6: Main architecture of our model.
2.5 模型训练
在训练过程中,我们将实体识别的交叉熵损失函数和2.3节讲的映射函数损失函数一起进行学习,其表示为:
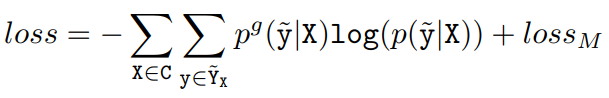
3. 实验
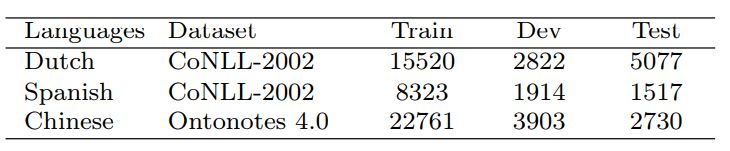
我们在西班牙语、荷兰语和中文上进行实验,其语料如下表2所示
表 2: # of sentences.
我们将自己所提的方法进行了不同的模型组合,其西班牙语和荷兰语结果如表3所示,中文结果如表4所示,均显示我们的方法
表 3: Comparison of different methods on low resource NER.
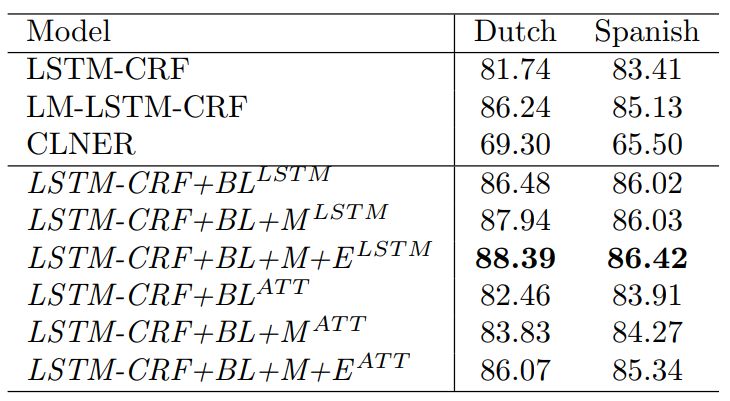
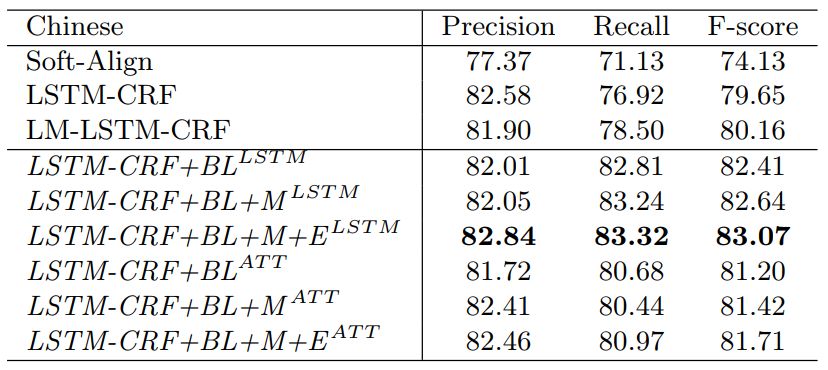
表 4: Comparison of different methods on Chinese NER.
此外,我们为了验证所提模型对于未登录实体的有效性,进行了分组实验,其结果如下表5所示,其中A代表测试集中在训练集中出现过的实体,B代表测试集中的实体未在训练集里出现过,最终,我们可以看到我们的模型在B数据集获得了更多的提升,说明跨语言知识的引入对于未登录实体的识别有非常显著的作用。
表 5: Comparison of the results for LSTM-CRF, LM-LSTM-CRF and our LSTM-based networks. A denotes the entities appearing in both training and test datasets, and B indicates all other cases. Evaluation metric is F measure

4. 结论
在面向资源稀缺语言的实体识别任务中,我们提出了一个通用的跨语言语义表示框架,我们通过学习跨语言的知识来增强目标语言的语义表示,使得目标语言能够在实体识别任务上获得更好的结果,具体而言,我们学习了两种跨语言知识表示方法,以及一种基于映射的词典扩充表示方法和基于实体类型分布的表示特征。在三种语言(西班牙语、荷兰语和中文)上进行实体识别实验,与标准的LSTM-CRF模型对比,我们的方法能够平均获得超过3%的提升。在未来的工作中,我们计划将该框架用于其它序列标注和文本分类任务。
本期责任编辑: 刘一佳
本期编辑: 赵怀鹏
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,赵森栋,刘一佳
编辑: 李家琦,赵得志,赵怀鹏,吴洋,刘元兴,蔡碧波,孙卓
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。





