论文浅尝 | 基于知识图的问答变分推理

Zhang Y, Dai H, Kozareva Z, et al. Variational Reasoning for Question Answering with Knowledge Graph. Proceedings of 32th AAAI 2018
动机
传统的知识图谱问答主要是基语义解析的方法,这种方法通常是将问题映射到一个形式化的逻辑表达式,然后将这个逻辑表达转化为知识图谱的查询例如SPARQL。问题的答案可以从知识图谱中通过转化后的查询得到。然而传统的基于语义解析的知识库问答会存在一些挑战,如基于查询的方法只能获取一些明确的信息,对于知识库中需要多跳才能获取的答案则无法回答。举例来说当问到这样一个问题“Who wrote the paper titled paper1?,传统的基于语义解析的方法可以获得如下语句进而可以查到 paper1 这个实体
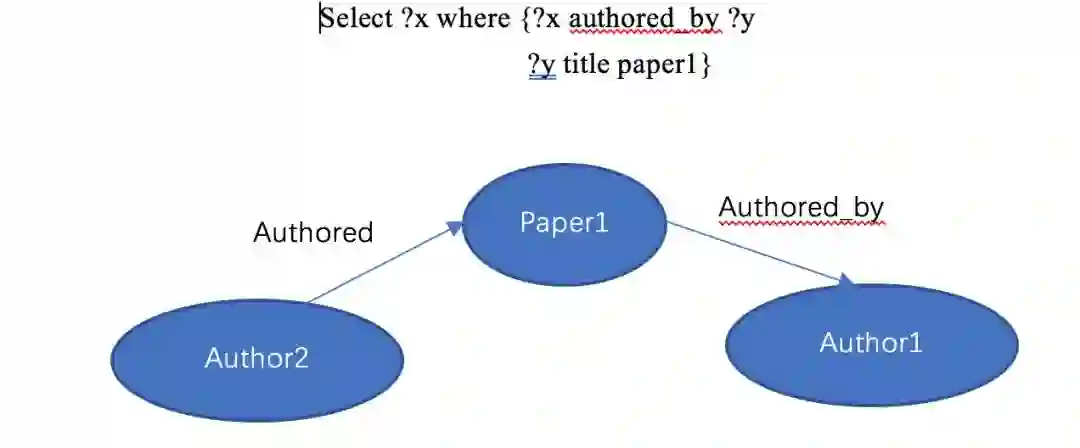
但是在上例中,当我们询问Who have co-authored paper with author1由于缺乏co-author这个明确的关系,传统的方法则无法转换成合适的查询语句。但实际上在上例中author2则是author1在paper1中的co-author
另一个对于传统方法的挑战是,在传统方法中问句中含有的实体通常都使用很简单的方法来匹配到知识库上,例如字符串匹配。但是实际的场景中用户的输入可能是通过语音识别转换而来或者是用户通过打字输入而来。因此用户的输入很难确保不存在一定的噪声。在具有噪声的场景下,问句中的实体则很难直接准确的匹配到知识库上。因此本文提出了一个端到端的知识库问答模型来解决以上两个问题。
创新点
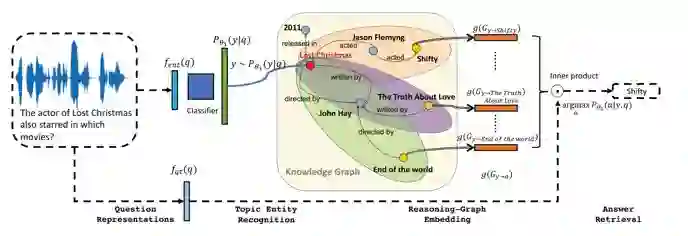
模型框架图
本文提出的模型如上图所示。这个模型为了克服上述所说的问题则将模型分为两个部分:
第一部分是通过概率模型来识别问句中的实体。如问句 who acted in the movie Passengers? 我们希望能将 Passengers 识别出来。但由于训练数据中的实体没有被标注出来,因此这个识别的实体将被看成一个隐变量。整个识别实体的过程如下:
1) 先将输入的问句 q 进行编码,将问句 q 转换为一个维度是 d 的向量
2) 随后将图谱中每个实体都转化为一个向量
3) 通过 softmax 计算在 q 下图谱中每个实体是 q 中实体的概率
该过程在整个模型框架图的左上部分在上例中输入问句 The actor of lost Christmas also starred in which movies 通过算法在图中找到 lost Christmas 为问句中对应的实体
第二部分则是在问答时在知识图谱上做逻辑推理,在推理这部分的工作中我们给出了上一步识别的实体和问句希望系统能给出答案。由于在整个系统的学习过程中没有人来标注在问答时使用的推理规则,因此在问答时使用的规则将被学习出来。整个推理过程如下所示:
1) 通过另一个网络对问句 q 进行编码,将 q 转化为一个维度是 d 的向量
2) 通过一个Reasoning graph embedding,对 y 的相邻实体进行编码
3) 通过 softmax 计算通过 y 推理找到实体是问题 q 答案的概率
4) 如果推理没有达到限定的步数则返回2)将原来y相邻的实体转换为y进而进行推理
整个推理过程则在上图的右半部分,该部分分别计算推理时实体是问句答案的概率,最后得到实体 shifty 对于问句 q 概率最大。而概率最大的实体到y的路径则是推理所获取的路径为 lost Christmas acted Jason Flemyng acted Shifty.
最后算法通过 EM 进行优化,整体训练的思路是希望第一部分和第二部分的概率同时最大
实验结果
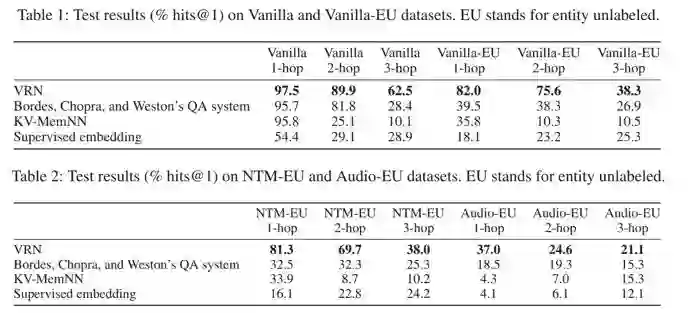
实验结果显示在 Vanilla、NTM 和 Audio 数据集下,算法的效果都超过传统的 QA 系统,同时在需要推理的问题中性能更为显著。
笔记整理:高桓,东南大学博士生,研究方向为知识图谱、自然语言处理。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

转载须知:转载需注明来源“OpenKG.CN”、作者及原文链接。如需修改标题,请注明原标题。
点击阅读原文,进入 OpenKG 博客。


