ACL 2019 知识图谱的全方位总结

优秀的学者,开完会都是要写总结博客的~
翻译 | 栗峰 审校 | Camel
编辑 | Pita
ACL 2019已经结束,但其空前的规模仍然震撼人心:2900多篇提交论文,660篇被接收,3000多名会议注册人员,以及4个超过400人的研讨会(比一些国际CS会议都大)。
值得一提的是,在本届ACL中热门话题(例如BERT系列、Transformers、机器翻译等)受到热烈关注,但除此之外还有一些新的趋势,例如对抗学习、自然语言生成、知识图谱等。以知识图谱为例,本次会议中共有30篇接收论文,大约占了所有接收论文的5%。
会后总结是优秀学者的必要行动。随着ACL会议的结束,在网上已经先后出现了多篇关于ACL大会上各细分领域的总结文章。
例如来自德国Fraunhofer IAIS的研究科学家Michael Galkin近日便在Medium上发表了一篇关于知识图谱@ACL2019的总结文。
文章则围绕ACL大会上关于知识图谱(KG)的研究进行了详细且完整的探讨的内容,共包含五个部分,分别为:
1、基于知识图谱的对话系统
2、知识图谱事实的自然语言生成
3、基于知识图谱的问答
4、基于知识图谱的NER和关系链接
5、知识图谱嵌入和图表示
一、基于知识图谱的对话系统
对话系统,传统上分为目标导向agent和闲聊agent两种。所谓目标导向agent,即帮助用户去完成某项任务,例如帮忙预定餐桌或安排代驾等。闲聊agent即智能对话,具有互动性、娱乐性和话题性。
近来,我们可能听到太多关于深度神经网络构建端到端(不需要特定通道)对话系统的工作。然而,现在越来越明显的一个趋势就是,无论在目标导向还是闲聊的agent中都需要拥有一些知识,前者需要领域知识,后者需要常识知识。
1、关于集成知识的趋势,ACL主席周明在大会主旨演讲中已经表达的很清楚了。演讲中,他强调了将知识图谱、推理和背景纳入对话系统的重要性。我想补充的一点是,知识图谱也将同时提高agent对话的可解释性。
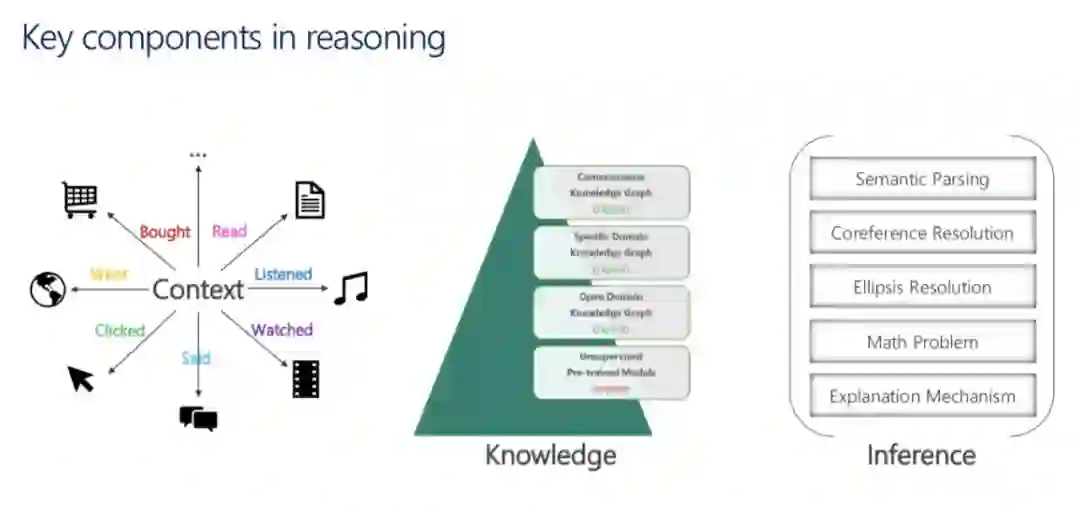
图1:ACL主席周明演讲中提到知识图谱的重要性
2、在NLP forConversational AI 研讨会[1]中讨论了更多此类细节问题。华盛顿大学的 Yejin Choi[2]提出了一种在对话中整合基于知识种子的常识推理(knowledge-seeded commonsense reasoning)的方法。

3、亚马逊的RuhiSarikaya[3]证实,Alexa有一部分仍需要在带有从结构源(例如图)中提取知识的通道模式下执行。
4、微软研究院的JianfengGao[4]阐释了小冰是如何利用结构化信息与用户互动的。值得注意的是,小冰目前为止仍然保持着最长人机对话的记录(23轮)。
5、Facebook AI的Moon等人[5]在2019年推出了OpenDialKG,这是一个新的开放式对话知识图谱并行语料库,有15K的标注对话、91K轮(基于1M三元组、100k实体和1358个关系的Freebase子集)。这在构建基于知识图谱的对话系统上迈出了巨大的一步,希望Facebook的工作也会鼓励到其他人。此外,作者提出了一种新颖的DialKG Walk架构,能够利用带有一个基于注意力图谱路径解码的E2E方式的知识图谱。
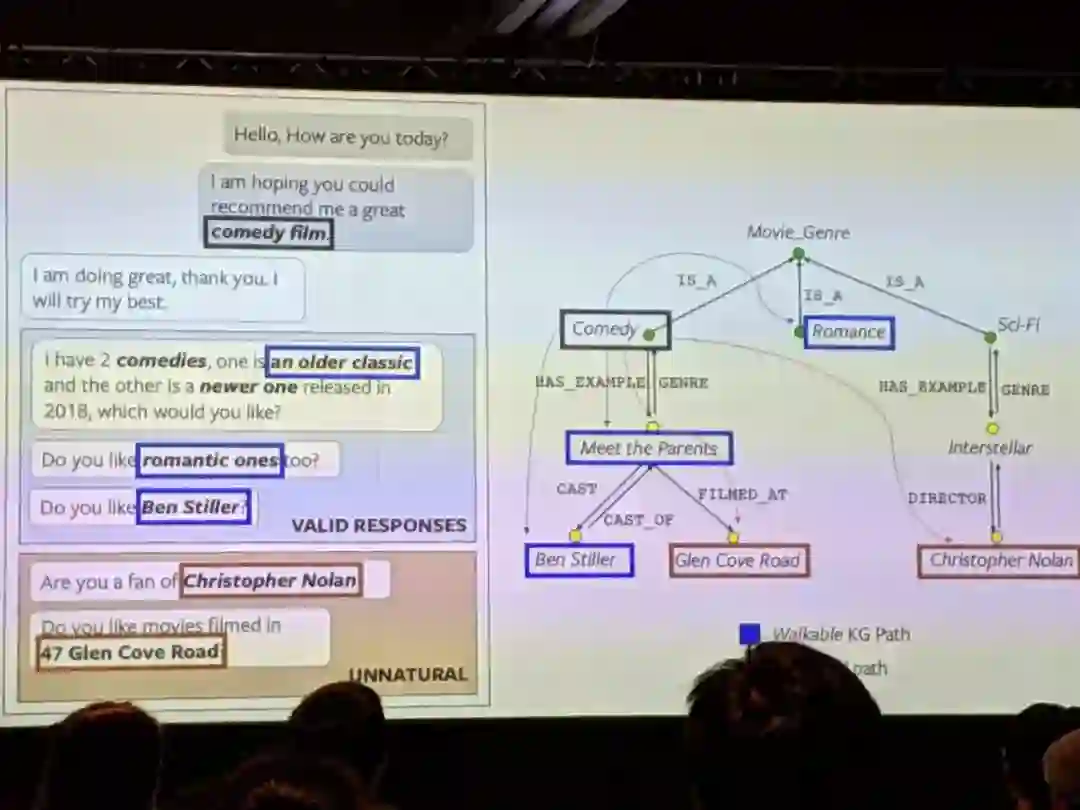
图3:ACL上FacebookAI 对OpenDialKG的报告
唯一值得担心的是选定的图(Freebase)从2014年起就正式停用了,并且很长时间里都没有支持了。或许是时候该将社区数据切换到维基数据了?
二、知识图谱事实的自然语言生成
生成连贯的自然语言话语(例如从结构化数据)是一个热门的新兴话题。纯粹的神经端到端 NLG模型试图解决的是生成“非常枯燥”的文本的问题,而结构化数据的NLG在表达自然语言的固有结构方面则更具有挑战性。知识图谱难以用语言表述。例如,你可以从一个三元组(Berlin, capitalOf,Germany)生成多个不同的句子,但当你有一组连接的三元组时(Berlin, capitalOf,Germany)(World_Cup_2006, hostedBy, Germany)时,以下哪个选项更有效呢?
“Berlin is the capital ofGermany which hosted the World Cup 2006”
“Berlin is the capital of thecountry where World Cup 2006 took place”
令人惊讶的是,ACL会议中展示了相当多关于知识图谱三元组描述(verbalizing triples in KGs)的内容。
首先,我要提一下由IBM研究院组织的关于storytelling研讨会[6],在这个研讨会上提出了大量解决三元组描述问题的比赛和可行的方案。(可以去看相关的slides).
在Logan等人展示的论文[7]和poster中,他们建议应当将语言模型(例如OpenAI GPT)与知识图谱嵌入结合使用。作者还介绍了一个新的数据集Linked WikiText-2[8],数据集中训练集包含了从Wikidata中标注的41K个实体和1.5K个关系。
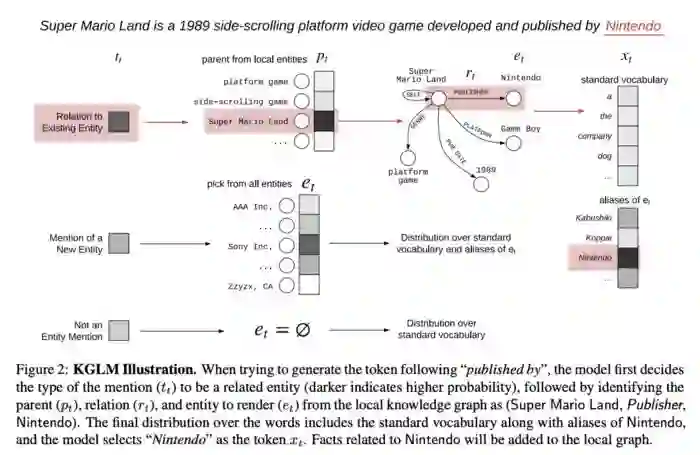
图4:Taken from Logan et al.
事实上并仅仅是在ACL 2019上有这些文章,在最近的NAACL 2019中,Moryossef等人的一项工作[9]也于此相关,他们提出一种基于三元组的自然语言生成双重模型Chimera(two-fold model for NLG over triples)。首先,在给定三元组的情况下,他们生成如图(graph)一样的文本方案,其中保留了给定三元组的组合型;然后对这些文本方案进行打分排序;最后,运行一个典型的具有复制机制的神经机器翻译(NMT)来生成文本句子。其实验评估是就WebNLG数据集,有意思的是这个数据集也使用了Wikidata实体和谓词ID。
三、基于知识图谱的回答
问答(作为一个阅读理解任务)是追踪类似BERT这样大型模型进展的流行基准之一。
“基于知识图谱的问答(KGQA)旨在为用户提供一个界面,让用户能够用自然语言提问,且能使用他们自己的术语,然后通过查询知识图谱来得到简明的答案。”
以上的定义我引用了Chakraborty等人[10]的定义。在QA任务中,知识图谱为用户提供了可解释的结果(实际上,一个图模式可以/不可以在目标图中找到)。此外,它还可以执行阅读理解系统无法实现的复杂推理。在这方面,ACL 2019有许多state-of-art的研究,你可以去查一查。
Saha等人的工作[11]是复杂序列问答(ComplexSequential Question Answering,CSQA)数据集(带有WikidataID),这个数据集目前包含了基于知识图谱的最困难的问题,例如,
聚合:“Which people are the patron saint of around the same number ofoccupations as Hildegard of Bingen?”
验证:“Is that administrative territory sister town of Samatice andShamsi, Iran?”
以及更多组织为带有「基于实体和关系的指代消除」的对话。
没有记忆的方法及时在简单问题上训练也会表现出非常差的性能,现在看来你需要某种格式化语言或语法来执行逻辑动作和聚合。Saha等人介绍了一种包含几个动作(例如交集、知识图谱嵌入查找等)的语法,强化学习用它来推导出能够在对话环境中回答以上复杂问题的逻辑程序。

Weber等人[12]研究的是神经Prolog,这是一个可微逻辑方法(differentiable logic approach),它将符号推理和基于句子嵌入的规则学习方法结合了起来,可以字节应用到自然语言文本中,而不需要将文本转化为逻辑形式,且可以使用Prolog形式的推理来进行逻辑查询。因此,这个框架事实上是建立在模糊逻辑和预训练句子嵌入模型之上的。我认为神经逻辑方法目前在社区中是一个被严重低估的领域,这篇文章以及上篇文章都为它们是如何推理出特定答案提供了一个非常基础的可解释的机制;因此当研究人员想要在真实可解释性方面开辟战场时,我希望这个领域能够得到足够的重视。
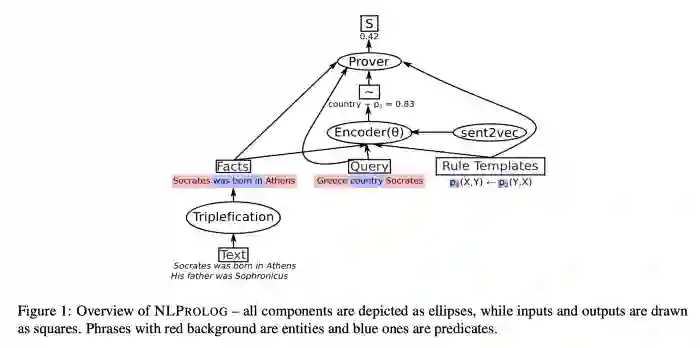
图6:Taken from Weber et al.
针对处理起来相对简单的KGQA数据集,Xiong等人[13]提出了一种基于不完整知识图谱的QA,在这里需要进行一些链接预测;Sydorova等人[14]在TextKBQA任务(有两个知识源:图和文本段落)上获得了不错的结果。另外一种方法是Yang等人[15]提出的,他们使用了带有KG(本例中使用的是wordNet和NELL)的BERT形式的阅读理解模型。截止2019年3月,他们的KT-NET在SQuAD1.1和ReCoRD上的表现优于纯粹的MRC系统,这说明这是一个有前景的研究方法。
基于阅读理解的QA系统目前仍然是比较火热的领域,在本次会议中有多个oral和poster的session都是关于这一方面的,所以我敢肯定随后会有一些关于这个方面更详细的解读。。简而言之,类似WikiHop或HotpotQA这样的新数据集是针对整个 Wikipedia文章进行multi-hopQA,您需要结合几篇文章中方法来回答一个问题。CommensenseQA包含了从搜索引擎日志中获取的真实问题,因此系统需要建立莫衷类型的常识推理。如果你想从一堆完全无意义的样本中区分出有意义的部分,那么你就需要使用对抗训练了,今年ACL也提供了几篇文章(Zhu等人[16]和Wu等人[17]),他们的对抗训练还不错。
最后,要为了克服训练数据集较小的问题,Alberti等人[18]提供了一种改写数据增强方案(paraphrasing data augmentation schema),能够生成多达50M额外的问题来训练他们的系统,结果显示F1值有+2到+3的提升。
四、基于知识图谱的NER和关系链接
今年的ACL大会中,“信息抽取”毫无疑问是最受欢迎和最引人注目的一个方向。而KG在信息提取的命名实体识别、实体链接、关系抽取、关系链接等方面也展现出了真正的优势。此外,在本次会议上也出现了许多新的(带有Wikidata IDs的)数据集和方法。
Bosselut等人[19]写的文章是在本次会议中我最喜欢的文章Top-3之一,在这篇文章中他们介绍了一种常识transformer架构:COMET。
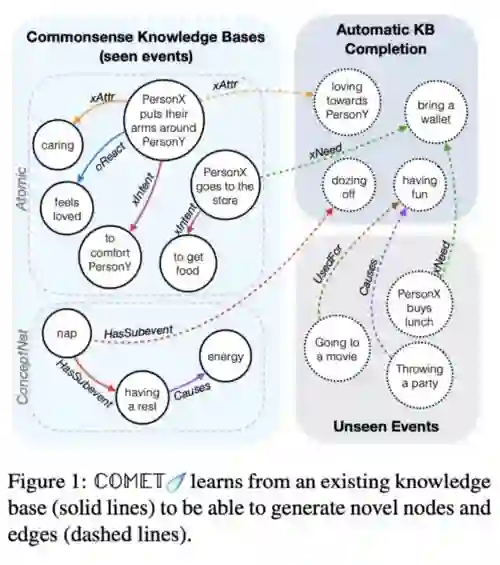
图7:Taken from Bosselut et al.
在COMET中,他们将语言模型(例如GPT-2)与种子知识图谱(例如ATOMIC)结合在了一起。给COMET输入图的种子元组,COMET便能学到图的结构和关系。此外,这个语言模型是用图表示构建而成,而不是传统的生成结点和边然后把它们加入到种子图中。更酷的是,你还可以得到一个表示为自然文本元组(例如(take a nap, CAUSES, have energy))的图。用这个架构在大型数据集(例如Wikidata)上测试应该是一件非常有意思的事情。
新数据集和关系提取的基线模型(它们都是基于Wikidata实体和谓词,很好!)Yao和Ye等人[20]提出了一个大型数据集DocRED,其中共102K个文档,包含了6个实体类型、96个关系、2.5M个实体(没有WikidataIDs),828K个句子。Trisedya等人[21]提出了一个包含255K文本三元对、280K个实体和158个谓词的数据集,基于这个数据集还提出了一个任务(从给定自然语言句子中构建知识图谱)和一个基准模型。此外,Chen等人[22]提出了一个关系相似性的数据集,包含426K三元组、112K个实体和188个关系。
在对信息提取的深入研究方面,Zhu等人[23]利用图注意力网络在关系链接方面取得不错的结果。他们将句子中的实体和关系组合建模为一个图,并使用能够识别多重关系(multi-hop relations)的GNN。结果在SOTA有重大的提升。
Soares等人[24]提出了一个关系学习的新方法——预训练一个大型模型(例如BERT),将句子输入它的编码器获得关系的抽象概念,然后在例如Wikidata、TACRED或DBpedia等特定模式中进行微调来获得一个带有相应ID的真实的谓词。这种方法具有很大的现实意义。通常基于KG的信息抽取方法都是为特定的本体(ontology)而设定的,所以你有多少本体你就需要有多少任务。这里作者从所有方案中提取了一些普适性的关系,这些关系你可以加入到你自己的方案中,从而减少大量重复性工作。这种方法在zero-shot和few-shot任务特别管用,在训练数据非常有限的情况下使用这种方式可以显著地提高你的模型的精确度。
在实体链接上,Logeswaran等人[25]提出使用类BERT的预训练阅读理解模型来将实体链接推广到未知领域的未知实体上。为此,他们引入了一个域自适应预训练(DAP)策略,以及在未知领域zero-shot实体链接的新任务。尽管目前他们的数据集仅包含了Wikia的文章,不过我认为将他们的框架应用到包含多语言标注和同义词或定义明确的特定领域本体的知识图谱上应该不会有太大问题。
Hosseini等人[26]的工作研究了从自然语言文本中直接提取关系图的问题,他们在多个评估数据集上获得了显著的改善。Shaw等人[27]也完成了一个类似的工作,他们用图网络(GNN这些天确实比较火)来获得带有实体的逻辑形式。
Wu等人[28]研究了KG中的关系表示,并提出一种表示适配模型(Representation Adapter model),这个模型可以推广到基于已有KG嵌入的未知关系当中。作者在文章中还将SimpleQuestion(SQ)数据集调整为SimpleQuestions-Balance(SQB)数据集,使得训练/测试拆分中实体与虚拟的谓词的分布更加平衡。
在命名实体识别(Named Entity Recognition,NER)上,我强烈推荐Lopez等人的文章“Fine-grained Entity Typing in Hyperbolic Space”[29]。使用可能涉及的实体&实体类型的二维列表(flat list),作者构建了一个双曲嵌入空间,来推断涉及的上下文,并将一个实体类型赋予给一个实体。例如,给定一个句子“A list of novels by Agatha Christie published in …”,其中“Agatha Christie”将不仅被标记为“human”,同时在更细粒度上会被标记为“writer”类中。实际中,这个框架在UltraFine数据集上的训练可以划分三级;在OntoNotes上,结果与SOTA方法旗鼓相当。
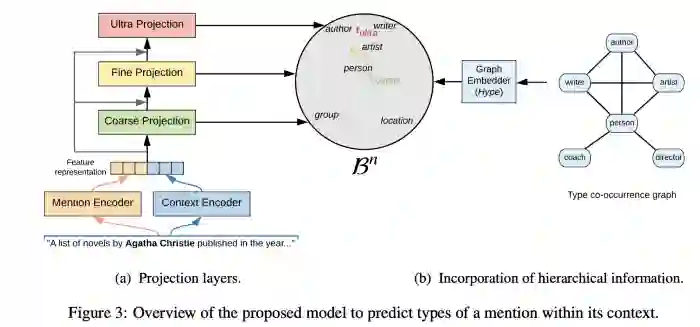
图9:Taken from Lopez et al.
五、知识图谱嵌入和图表示
可能有人会认为NLP的会议不是一个学习关于图表示的最佳场所,但在ACL这次会议上确实出现了许多有见解的论坛,它们尝试从结构和语义两方面对知识图谱进行编码。
Nathani等人[30]介绍了一种基于图谱注意力网络(graph attention networks,GAT)的知识图谱嵌入方法,该方法在注意力机制中考虑了结点(node)和边缘(edge)的特征。作者采用了多头注意力架构(multi-head attention architecture),并重点强调了学习关系表示。论文中对四个数据集(WN18RR、FB15k-237、NELL-995、Kinship)进行的基准测试中显著提高了SOTA性能。实际上,这种方法要比ACL会议上同一天展示的(下面介绍的)另外一个方法要更好。
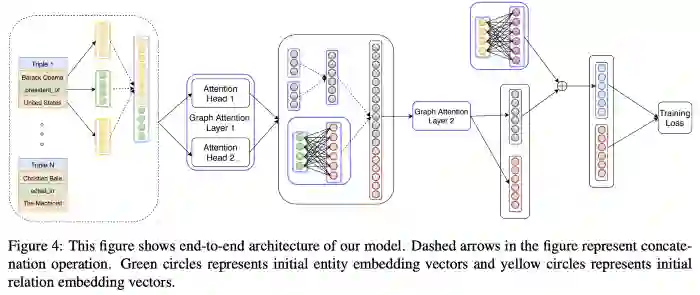
图10:Taken from Nathani et al.
Bansal等人[31]提出了A2N的方法,这是一种带有近邻注意力(neighbourhood attention)的知识图谱嵌入技术。作者在评估中证明,从近邻中获取信息可以更好地表示多重关系(multi-hop relation)。在关系预测的基准测试中,A2N的表现与ConvEx相当,有时候甚至更好。不过与前面提到的方法比起来要稍显逊色一些。我建议,作者可以比较一下训练时间和内存消耗。
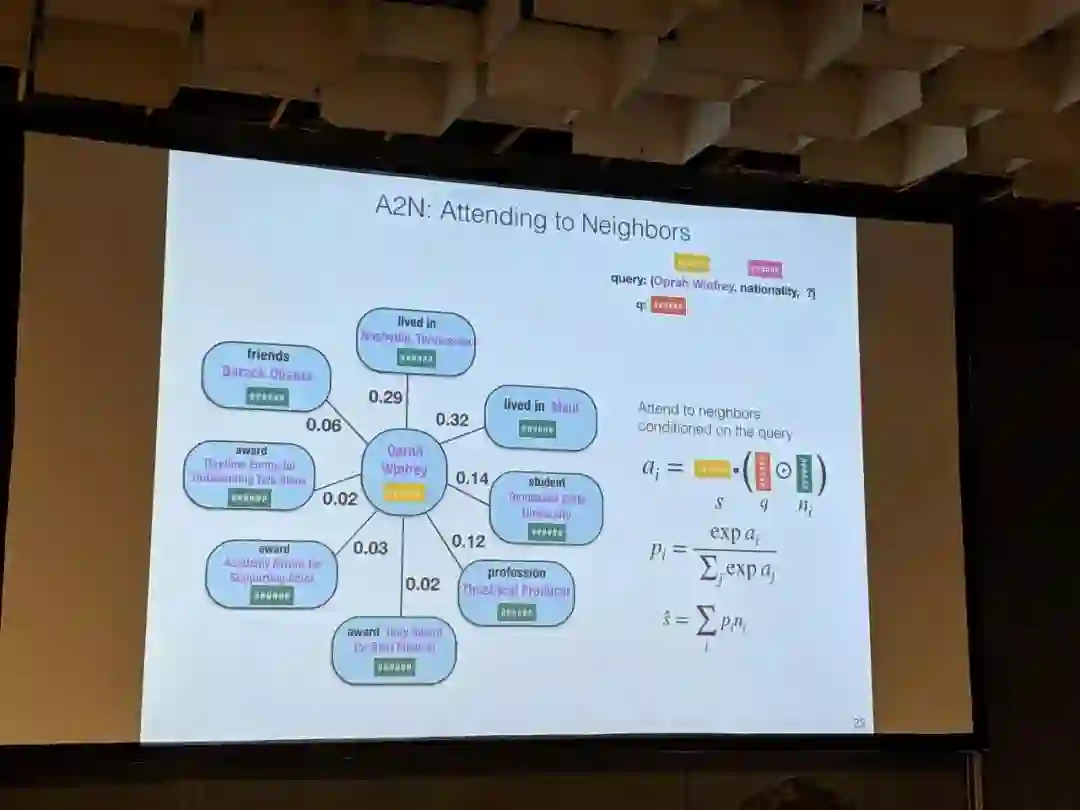
图11:A2N,Google提出一种新颖的知识图嵌入方法,关注邻居结点
Xu和Li的工作[32]和前两篇工作有些不一样,他们使用二面体群(不懂的同学请翻翻群论的书)来给KG嵌入的关系建模。要想读懂这篇论文就需要坚实的数学基础了(可以尝试挑战一下自己,💪),简单来说就是,二面体群可以为谓词的非阿贝尔成分(译者注:所谓非阿贝尔即,A*B!= B*A)建模,例如parent_of * spouse_of != spouse_of * parent_of(这里*表示矩阵乘积)。此外,这种方法也能够对谓词见的对称和反对称关系进行建模。这种方法在传统基准测试中的表现并不比ConvE好多少(这主要是因为传统基准包含了大量的阿贝尔元素成分),不过在作者构建的更侧重于非阿贝尔元素的数据集FAMILY上它们能够取得优秀的成绩。需要强调的是,这篇文章绝对值得一看,不过确实需要一些数学基础。
Kutuzov等人[33]提出了一种构建知识嵌入的新框架,在这个框架中他们不再使用基于向量的距离函数,而是采用基于图的最优测度(类似于最短路径),并插入了自定义结点相似度函数(例如Leacock-Chodorow)。不过,虽然这种方法能够提高推理速度,但却没有充分利用结点和边的特征。作者表示将在未来的工作中进一步完善,期待ing!
Stadelmeier和Pado两人[34]提出了一个上下文路径模型(context path model,CPM),目的是在传统KG嵌入方法的基础上提供一个可解释层。作者在文章中建议使用两个优化分数:1)路径校正分数;2)三元组和路径之间的相关性分数。
Wang等人[35]在他们的论文“On Evaluating Embedding Models for Knowledge BaseCompletion”中提出了KG嵌入评估中反复出现的一个问题:KG嵌入预测在逻辑上是否一致?例如在图中我们会有一些规则,像:
“Roger can’t befriends with David” (instance level);
“Humans can’t be made of Wood” (class level)
这意味着应该考虑KG嵌入,并降低此类陈述出现的可能性。但作者发现现在大部分KG嵌入模型都会给相当不切实际的三元组分配一个非零的概率值。
总 结
总结一点:
1)越来越多的人开始将知识图谱应用在NLP的各种领域;
2)关于知识图谱的各种新数据和新任务越来越频繁地出现。这些可以在会议议程中查到。
参考资料:
[1]https://sites.google.com/view/nlp4convai/
[2]https://homes.cs.washington.edu/~yejin/
[3]https://sites.google.com/site/ruhisarikaya01/home
[4] https://www.microsoft.com/en-us/research/people/jfgao/
[5] https://www.aclweb.org/anthology/P19-1081
[6] https://sites.google.com/view/acl-19-nlg/slides
[7] https://www.aclweb.org/anthology/P19-1598
[8] https://rloganiv.github.io/linked-wikitext-2/
[9]https://arxiv.org/abs/1904.03396
[10]https://arxiv.org/pdf/1907.09361.pdf
[11] https://www.mitpressjournals.org/doi/pdf/10.1162/tacl_a_00262
[12]https://arxiv.org/pdf/1906.06187.pdf
[13] https://www.aclweb.org/anthology/P19-1417
[14] https://www.aclweb.org/anthology/P19-1488
[15] https://www.aclweb.org/anthology/P19-1226
[16] https://www.aclweb.org/anthology/P19-1415
[17] https://www.aclweb.org/anthology/P19-1616
[18] https://www.aclweb.org/anthology/P19-1620
[19]https://www.aclweb.org/anthology/P19-1470
[20]https://arxiv.org/pdf/1906.06127.pdf
[21] https://www.aclweb.org/anthology/P19-1023
[22]https://www.aclweb.org/anthology/P19-1278
[23]https://www.aclweb.org/anthology/P19-1128
[24]https://www.aclweb.org/anthology/P19-1279
[25]https://www.aclweb.org/anthology/P19-1335
[26]https://www.mitpressjournals.org/doi/pdf/10.1162/tacl_a_00250
[27]https://www.aclweb.org/anthology/P19-1010
[28]https://www.aclweb.org/anthology/P19-1616
[29] https://arxiv.org/pdf/1906.02505.pdf
[30]https://www.aclweb.org/anthology/P19-1466
[31] https://www.aclweb.org/anthology/P19-1431
[32] https://www.aclweb.org/anthology/P19-1026
[33] https://www.aclweb.org/anthology/P19-1325
[34] https://www.aclweb.org/anthology/W19-4816
[35] https://arxiv.org/pdf/1810.07180.pdf
via https://medium.com/@mgalkin/knowledge-graphs-in-natural-language-processing-acl-2019-7a14eb20fce8


 ACL 2019已经结束,但是
KDD 2019图文直播
还在进
行中,扫码或点击阅读原文即可查看
ACL 2019已经结束,但是
KDD 2019图文直播
还在进
行中,扫码或点击阅读原文即可查看




