干货 | ACL 2019 知识图谱的全方位总结

来源:AI科技评论
本文约4600字,建议阅读10分钟。

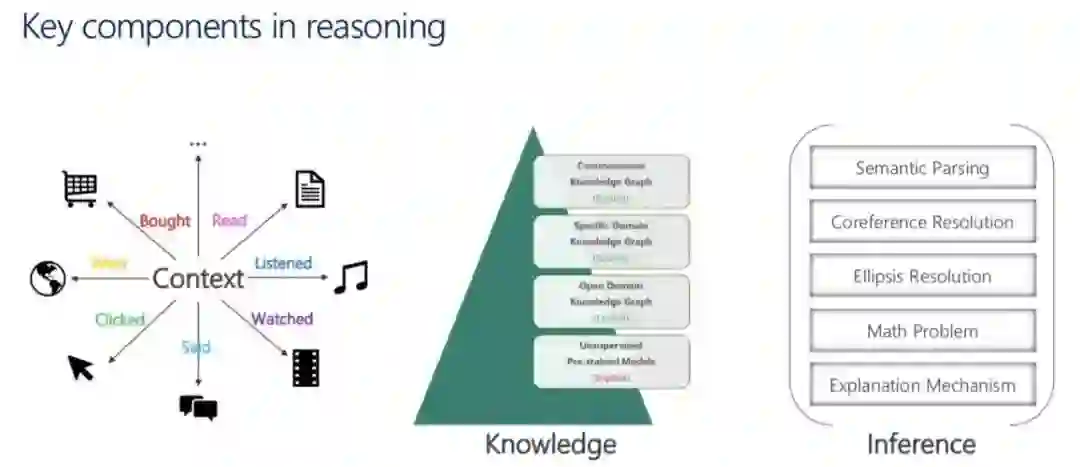
基于知识图谱的对话系统
知识图谱事实的自然语言生成
基于知识图谱的问答
基于知识图谱的NER和关系链接
知识图谱嵌入和图表示

-
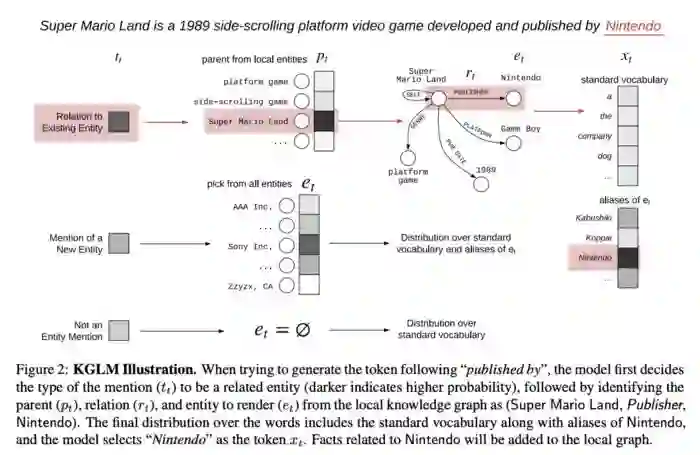
“Berlin is the capital ofGermany which hosted the World Cup 2006” -
“Berlin is the capital of thecountry where World Cup 2006 took place”
-
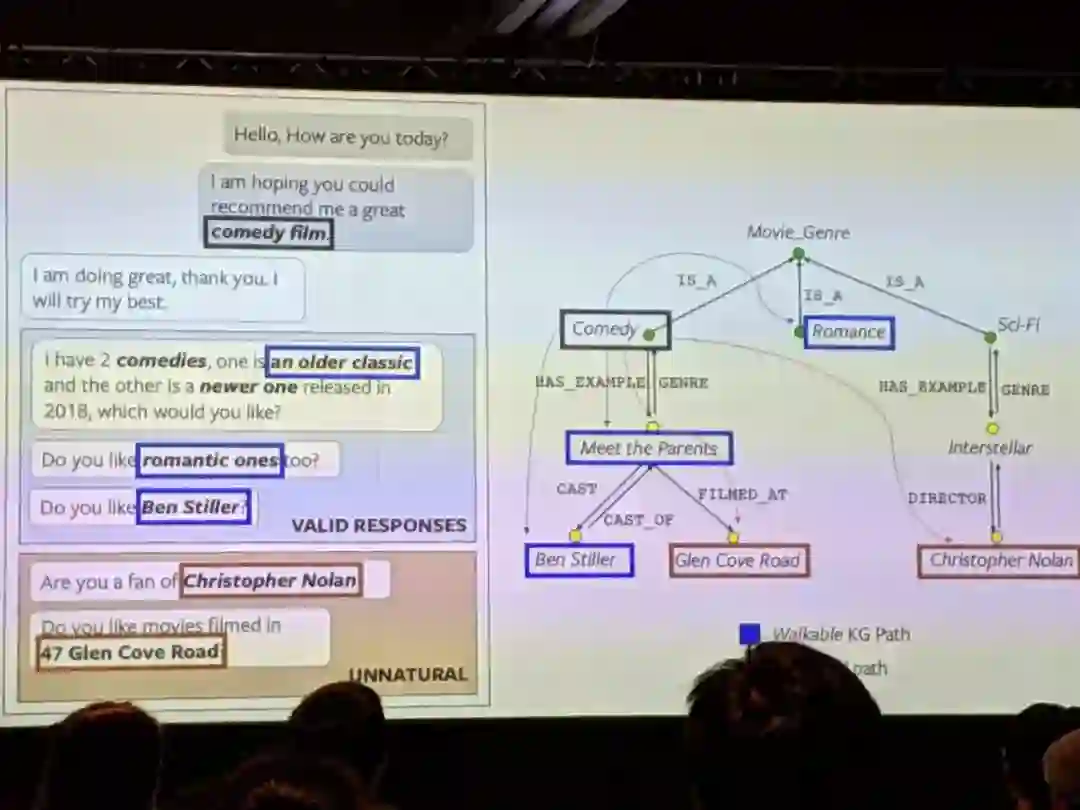
聚合:“Which people are the patron saint of around the same number ofoccupations as Hildegard of Bingen?” -
验证:“Is that administrative territory sister town of Samatice andShamsi, Iran?” -
以及更多组织为带有“基于实体和关系的指代消除”的对话。

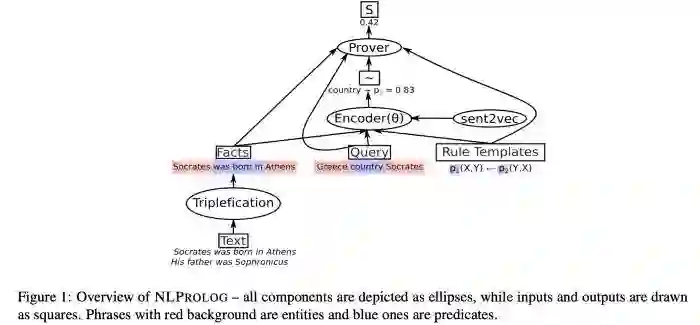
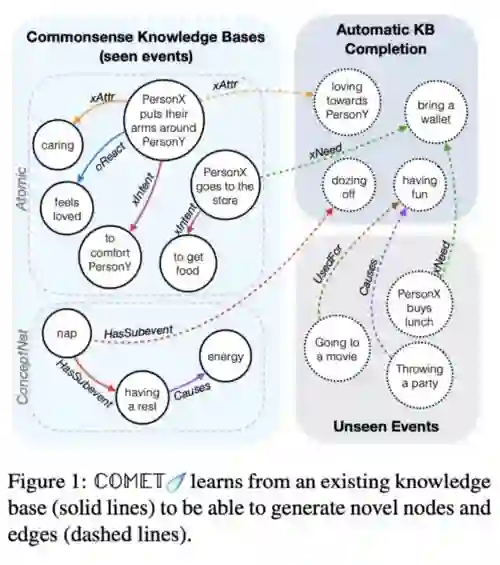
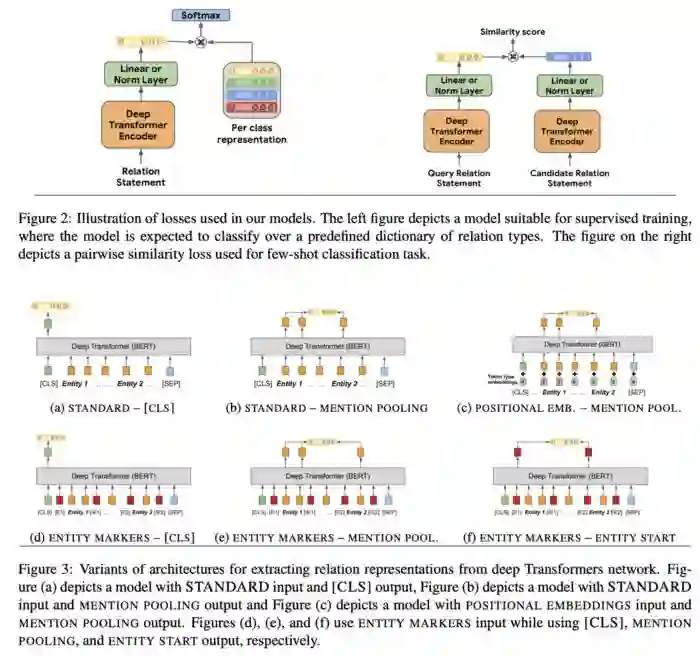
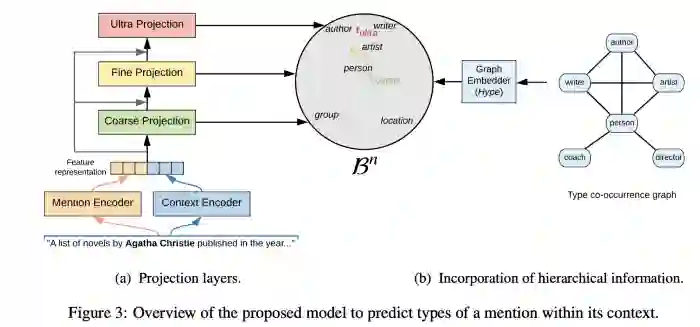
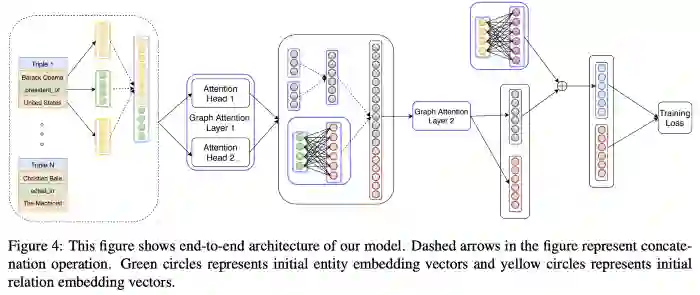
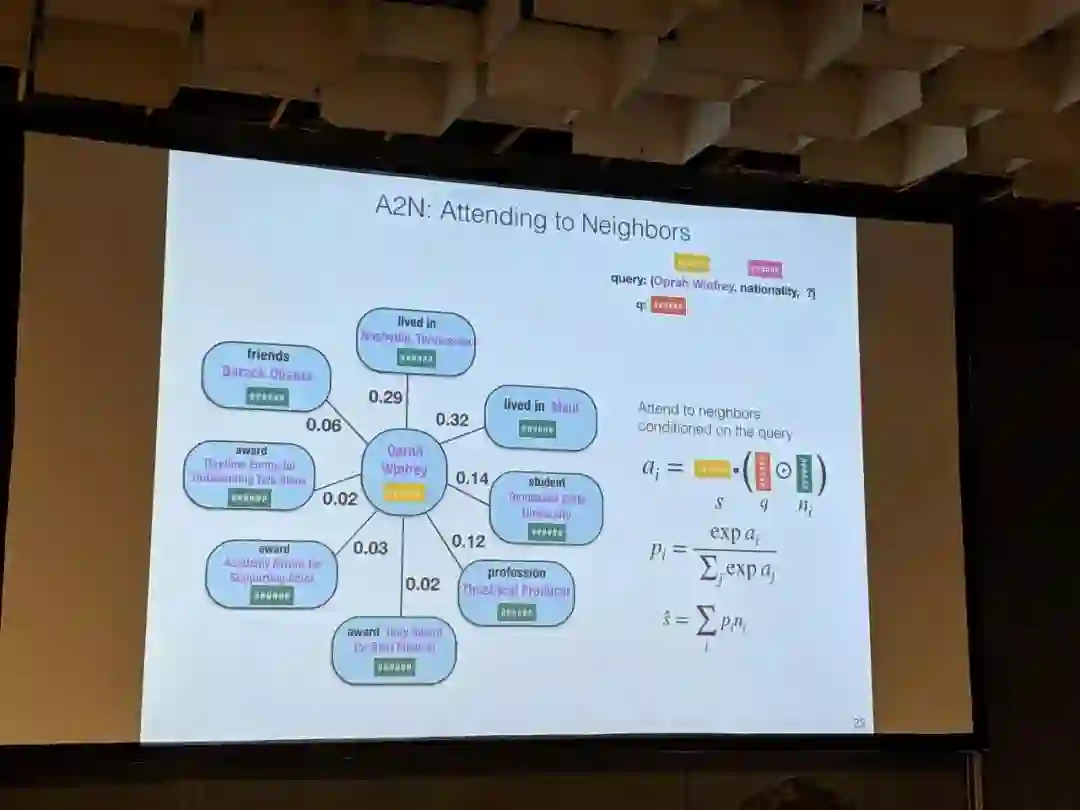
越来越多的人开始将知识图谱应用在NLP的各种领域;
关于知识图谱的各种新数据和新任务越来越频繁地出现。这些可以在会议议程中查到。

登录查看更多
相关内容

知识图谱(Knowledge Graph),在图书情报界称为知识域可视化或知识领域映射地图,是显示知识发展进程与结构关系的一系列各种不同的图形,用可视化技术描述知识资源及其载体,挖掘、分析、构建、绘制和显示知识及它们之间的相互联系。
知识图谱是通过将应用数学、图形学、信息可视化技术、信息科学等学科的理论与方法与计量学引文分析、共现分析等方法结合,并利用可视化的图谱形象地展示学科的核心结构、发展历史、前沿领域以及整体知识架构达到多学科融合目的的现代理论。它能为学科研究提供切实的、有价值的参考。
专知会员服务
40+阅读 · 2020年5月4日
Arxiv
20+阅读 · 2019年12月19日




相关VIP内容
专知会员服务
40+阅读 · 2020年5月4日
相关资讯
相关论文
Arxiv
20+阅读 · 2019年12月19日