

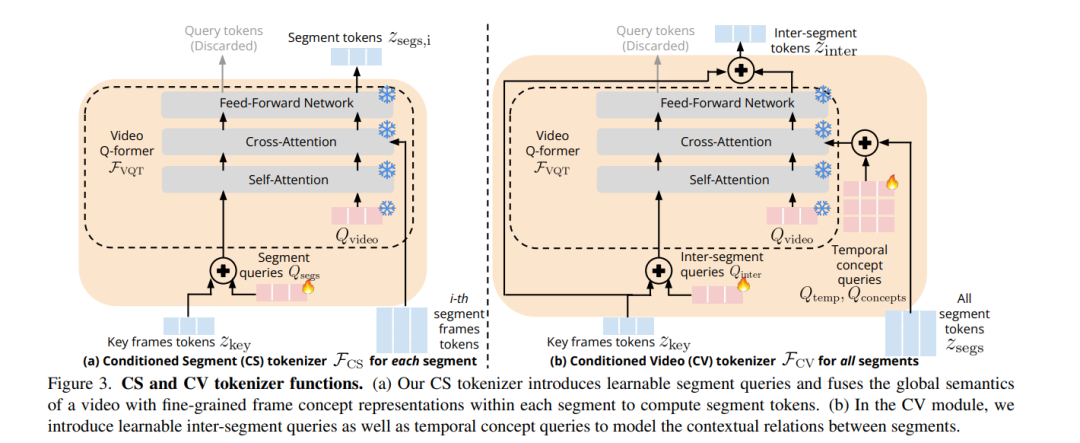
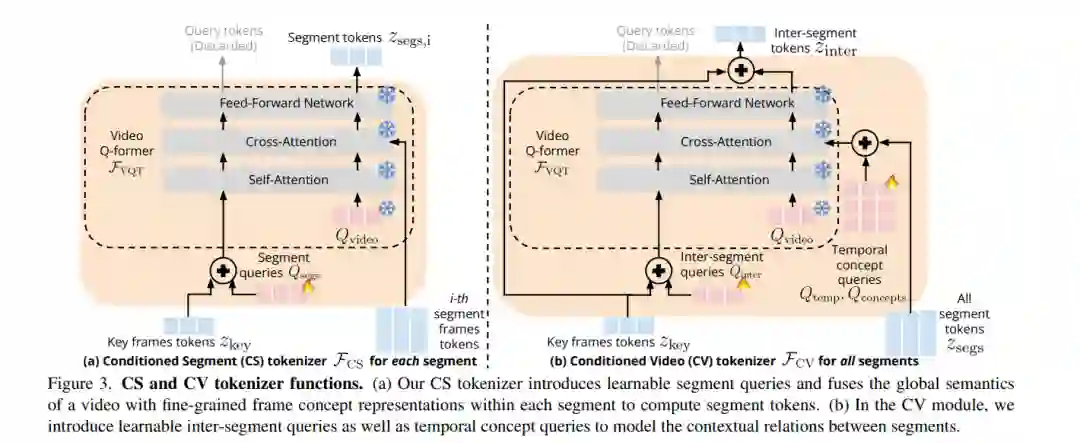
长视频问答是一项具有挑战性的任务,涉及识别短期活动并推理其细粒度关系。最先进的视频大语言模型(vLLMs)因展现出对新任务的突现能力而被认为是可行的解决方案。然而,尽管在数百万个短视频(视频长度仅几秒)上进行了训练,vLLMs 仍无法理解长达数分钟的视频并准确回答有关这些视频的问题。为了解决这一限制,我们提出了一种轻量级且自监督的方法——关键帧条件化长视频语言模型(Koala),引入了可学习的时空查询以适应预训练的 vLLMs,以便泛化到更长的视频。我们的方法引入了两种新的分词器,这些分词器依赖于从稀疏视频关键帧计算得到的视觉令牌,以理解短视频和长视频瞬间。我们在HowTo100M上训练我们的提议方法,并在零样本长视频理解基准测试中展示了其有效性,在所有任务中绝对准确率比最先进的大模型提高了 3 - 6%。令人惊讶的是,我们还实证显示我们的方法不仅有助于预训练的 vLLM 理解长视频,还提高了其在短期动作识别上的准确性。
成为VIP会员查看完整内容

相关内容
Arxiv
0+阅读 · 2024年5月31日
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日
相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2024年5月31日
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日