

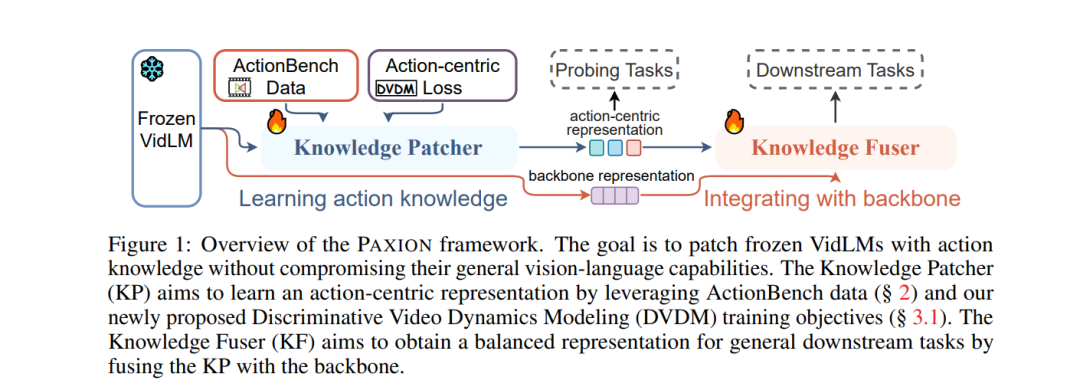
动作知识涉及对动作的文本、视觉和时间方面的理解。我们介绍了动作动力学基准(ActionBench),其中包含两个精心设计的探测任务:动作反义和视频反转,分别针对模型的多模态对齐能力和时间理解技能。尽管近来的视频-语言模型(VidLM)在各种基准任务上的表现令人印象深刻,但我们的诊断任务揭示了它们在动作知识方面的惊人不足(近乎随机性能),这表明当前模型依赖于对象识别能力作为理解动作的捷径。为了补救这一问题,我们提出了一种新颖的框架,PAXION,以及一个新的区分性视频动力学建模(DVDM)目标。PAXION框架利用知识修补网络来编码新的动作知识,并利用知识融合组件将修补器整合到冻结的VidLM中,而不会损害它们现有的能力。由于广泛使用的视频-文本对比(VTC)损失在学习动作知识方面的局限性,我们引入DVDM目标来训练知识修补器。DVDM迫使模型编码动作文本与视频帧正确排序之间的关联。我们的广泛分析显示,PAXION和DVDM一起有效地填补了动作知识理解的差距(~50% → 80%),同时维持或提高了在一系列以对象和动作为中心的下游任务上的表现。
成为VIP会员查看完整内容
相关内容
专知会员服务
15+阅读 · 2019年12月3日
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
10+阅读 · 2021年9月30日
相关主题

相关VIP内容
专知会员服务
15+阅读 · 2019年12月3日
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
10+阅读 · 2021年9月30日