

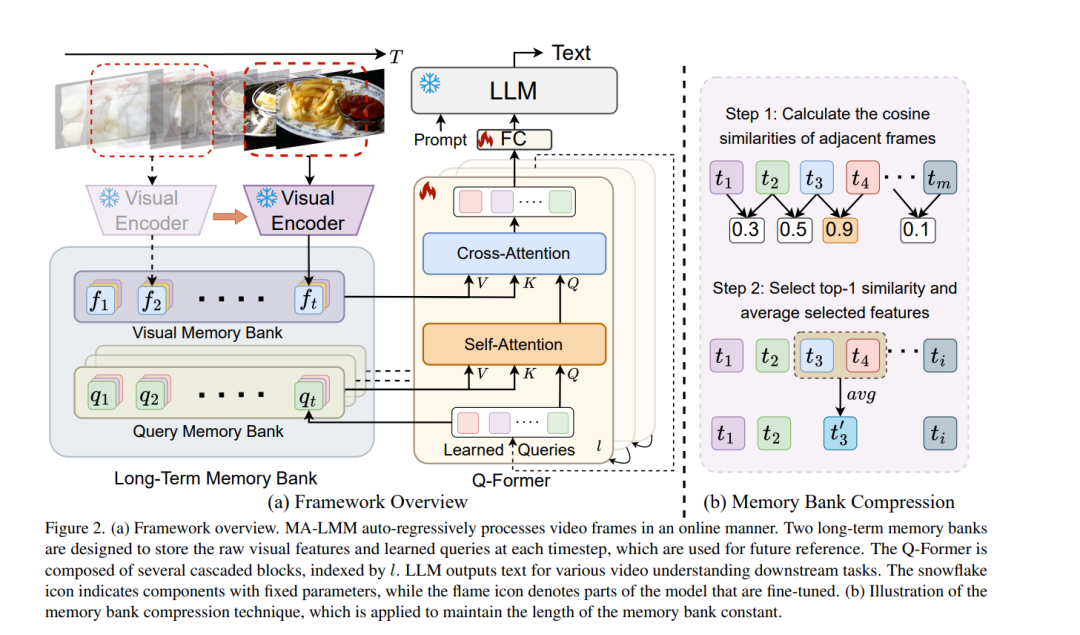
随着大型语言模型(LLMs)的成功,将视觉模型整合到LLMs中以构建视觉-语言基础模型近来引起了更多的关注。然而,现有的基于LLM的大型多模态模型(例如,Video-LLaMA,VideoChat)只能处理有限数量的帧来理解短视频。在这项研究中,我们主要关注设计一个高效且有效的模型用于长期视频理解。我们提出一种在线处理视频的方法,而不是像大多数现有工作那样尝试同时处理更多帧,并在内存库中存储过去的视频信息。这使得我们的模型能够参考历史视频内容进行长期分析,而不会超出LLMs的上下文长度限制或GPU内存限制。我们的内存库可以以现成的方式无缝集成到当前的多模态LLMs中。我们在各种视频理解任务上进行了广泛的实验,例如长视频理解、视频问题回答和视频字幕制作,我们的模型在多个数据集上都能实现最先进的性能。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日

相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日