

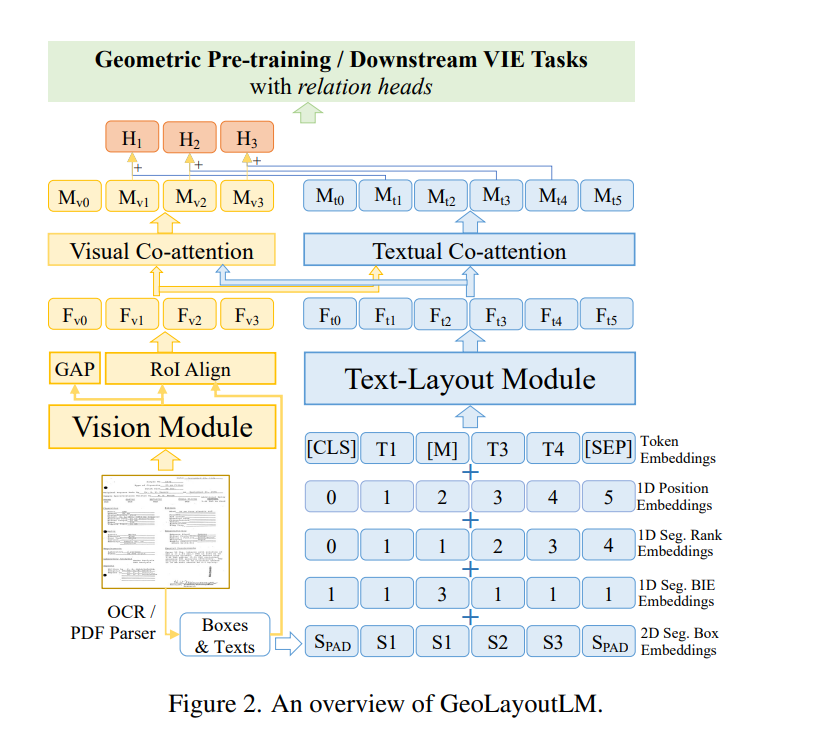
视觉信息提取(VIE)在文档智能领域中扮演着重要角色。通常,它可以分为两个任务:语义实体识别(SER)和关系抽取(RE)。最近,针对文档的预训练模型在 VIE 方面取得了显著进展,特别是在 SER 领域。然而,大多数现有模型以隐式方式学习几何表示,这对 RE 任务来说被认为是不够的,因为几何信息对 RE 尤为关键。此外,我们发现限制 RE 性能的另一个因素在于预训练阶段与 RE 微调阶段之间的目标差距。为了解决这些问题,我们在本文中提出了一种用于 VIE 的多模态框架,名为 GeoLayoutLM。GeoLayoutLM 在预训练阶段显式地对几何关系进行建模,我们称之为几何预训练。几何预训练通过三个专门设计的与几何相关的预训练任务来实现。此外,我们精心设计了新颖的关系头,这些关系头通过几何预训练任务进行预训练,并针对 RE 进行微调,以丰富和增强特征表示。根据对标准 VIE 基准的广泛实验,GeoLayoutLM 在 SER 任务中获得了非常具有竞争力的分数,并在 RE 任务中显著优于先前的最先进方法(例如,RE 在 FUNSD 上的 F1 分数从 80.35% 提高到 89.45%)。
https://www.zhuanzhi.ai/paper/ae145d71d4b8a928e02dd161f0f851db
成为VIP会员查看完整内容
相关内容

CVPR 2023大会将于 6 月 18 日至 22 日在温哥华会议中心举行。CVPR是IEEE Conference on Computer Vision and Pattern Recognition的缩写,即IEEE国际计算机视觉与模式识别会议。该会议是由IEEE举办的计算机视觉和模式识别领域的顶级会议,会议的主要内容是计算机视觉与模式识别技术。
CVPR 2023 共收到 9155 份提交,比去年增加了 12%,创下新纪录,今年接收了 2360 篇论文,接收率为 25.78%。作为对比,去年有 8100 多篇有效投稿,大会接收了 2067 篇,接收率为 25%。
Arxiv
0+阅读 · 2023年6月7日
Arxiv
0+阅读 · 2023年6月2日
Arxiv
42+阅读 · 2023年4月19日
Arxiv
11+阅读 · 2020年7月31日
Arxiv
10+阅读 · 2020年3月31日
相关主题

相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2023年6月7日
Arxiv
0+阅读 · 2023年6月2日
Arxiv
42+阅读 · 2023年4月19日
Arxiv
11+阅读 · 2020年7月31日
Arxiv
10+阅读 · 2020年3月31日