

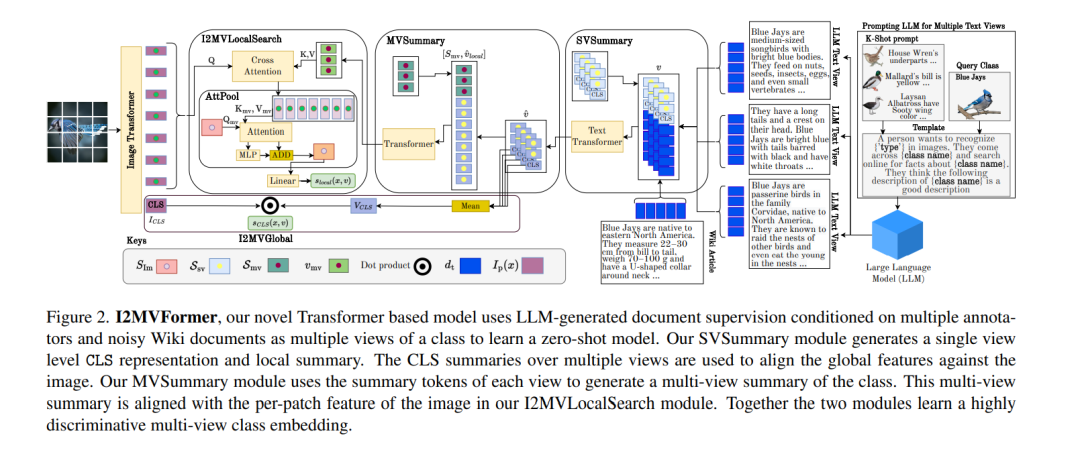
最近的工作表明,来自在线来源的非结构化文本(文档)可以作为零样本图像分类的有用辅助信息。然而,这些方法需要访问像维基百科这样的高质量来源,并且仅限于单一来源的信息。在网络规模的文本上训练的大型语言模型(LLM)显示出令人印象深刻的能力,可以将其所学的知识用于多种任务。本文提供了一种使用LLM为零样本图像分类模型提供文本监督的新视角。LLM提供了来自不同注释器的一些文本描述作为示例。LLM以这些示例为条件,为每个类生成多个文本描述(称为视图)。所提出的模型I2MVFormer用这些类视图学习多视图语义嵌入,用于零样本图像分类。类的每个文本视图都提供了补充信息,允许模型学习高度区分性的类嵌入。与基线模型相比,I2MVFormer更擅长使用LLM的多视图文本监督。I2MVFormer在三个公共基准数据集上建立了一种新的无监督语义嵌入的零样本图像分类技术。
https://www.zhuanzhi.ai/paper/bd64e48df69d1d0d94391b703ac2d14c
成为VIP会员查看完整内容
相关内容

CVPR 2023大会将于 6 月 18 日至 22 日在温哥华会议中心举行。CVPR是IEEE Conference on Computer Vision and Pattern Recognition的缩写,即IEEE国际计算机视觉与模式识别会议。该会议是由IEEE举办的计算机视觉和模式识别领域的顶级会议,会议的主要内容是计算机视觉与模式识别技术。
CVPR 2023 共收到 9155 份提交,比去年增加了 12%,创下新纪录,今年接收了 2360 篇论文,接收率为 25.78%。作为对比,去年有 8100 多篇有效投稿,大会接收了 2067 篇,接收率为 25%。
Arxiv
0+阅读 · 2023年4月14日
相关主题
相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2023年4月14日