

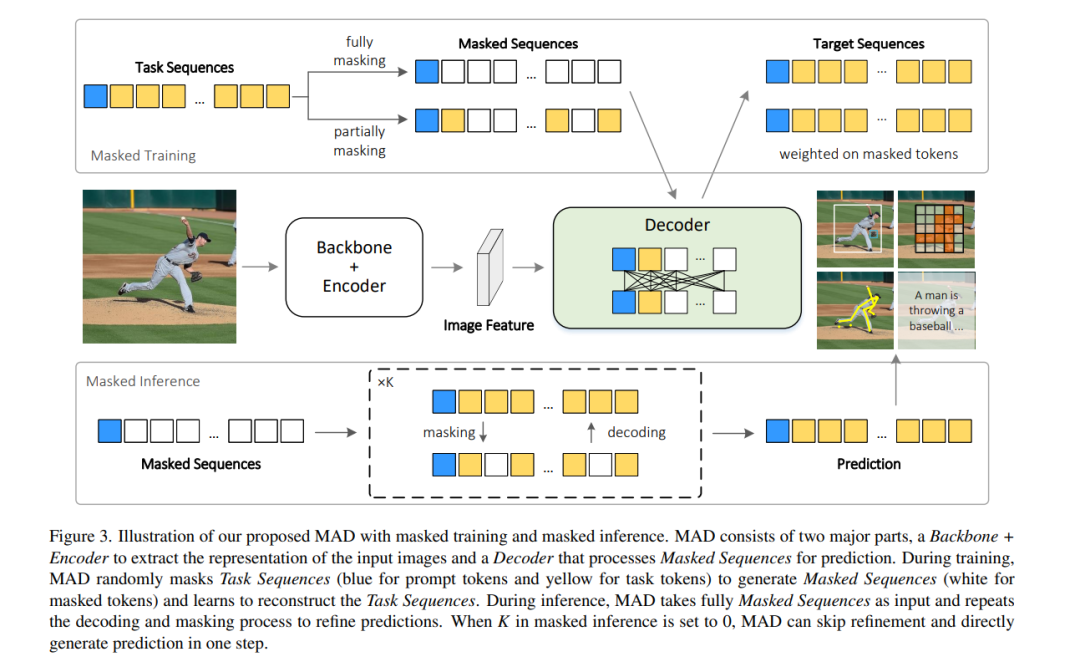
受到自然语言处理(NLP)中通用模型成功的启发,近期研究尝试将不同的视觉任务统一到相同的序列格式中,并使用自回归的Transformers进行序列预测。它们应用单向注意力来捕捉序列依赖性,并递归生成任务序列。然而,这样的自回归Transformers可能不适合视觉任务,因为视觉任务序列通常缺乏在自然语言中通常观察到的序列依赖性。在这项工作中,我们设计了Masked AutoDecoder (MAD),一个有效的多任务视觉通用模型。MAD包含两个核心设计。首先,我们开发了一个并行解码框架,引入双向注意力以全面捕捉上下文依赖性,并并行解码视觉任务序列。其次,我们设计了一种遮蔽序列建模方法,通过遮蔽和重构任务序列来学习丰富的任务上下文。通过这种方式,MAD通过单一网络分支和简单的交叉熵损失处理所有任务,最小化任务特定设计。广泛的实验展示了MAD作为统一各种视觉任务新范式的巨大潜力。与自回归对手相比,MAD实现了更优的性能和推理效率,同时与任务特定模型保持竞争力的准确率。代码将在https://github.com/hanqiu-hq/MAD 发布。
成为VIP会员查看完整内容
相关内容
Arxiv
0+阅读 · 2024年4月23日
Arxiv
224+阅读 · 2023年4月7日
相关主题

相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2024年4月23日
Arxiv
224+阅读 · 2023年4月7日