【学界】CVPR 2019 | 基于级联语义引导下的多通道注意力选择图像翻译
来源:PaperWeekly

研究背景
目前图像翻译问题的解决方案一般是基于 Encoder-Decoder 结构,即将原域图像编码后再解码到目标域中,然而这种方案在原域与目标域图像具有显著不同结构或重叠区域极少的情况下时翻译效果会大打折扣。
作者发现之前利用语义图指导图像翻译的模型对于图像细节的翻译效果不佳,作者认为这是由于语义图一般是由深度预训练模型产生,并不能保证像素级的准确性。基于此作者提出了级联语义引导下的基于多通道注意力选择机制的图像翻译 Selection GAN,其将图像翻译分为两个阶段,第一个阶段用于产生粗粒度级的翻译结果,第二个阶段通过多通道注意力选择机制产生更细致的结果(如图 1 所示)。

▲ 图1. 效果概览
模型介绍
Selection GAN 将图像翻译的过程分为两个阶段(如图 2 所示),第一阶段作者提出了一个级联语义引导的生成器子网络,该网络是将原域图像
以及目标域语义图
级联后的结果翻译至目标域图像
,该生成图像
作为语义生成器
的输入去生成目标域的语义图
。为了保证
和
的生成效果,这里使用重建损失来限制生成器,即
,
,另外目标域语义图
是由深度预训练模型产生。
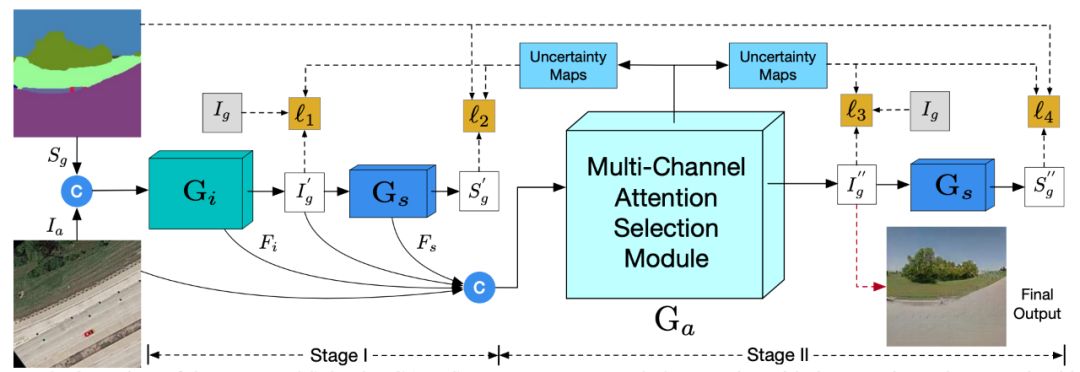
▲ 图2. 模型概览
经过第一阶段后模型产生了粗粒度级的翻译结果,在第二阶段中作者将该结果以及第一阶段生成的深度特征级联作为多通道注意力选择模型的输入(如图 3 所示),其目的是从更大的生成空间中产生更加细粒度级的翻译结果并且生成不确定映射去引导优化像素损失。
多通道注意力选择模型包括多规模空间池化和多通道注意力选择两个部分,作者选取第一阶段中和
的最后一层卷积网络的输出作为深度特征
和
,并与第一阶段的输出
和原域图像
级联为特征
,即
,输入至多规模空间池化网络中,该网络对
进行不同规模的平均池化从而获取多规模的空间上下文特征。为了保留有用信息将经过不同规模池化后的特征与输入特征
相乘,该结果经过卷积后产生新的多规模特征
并作为多通道注意力选择的输入。
作者认为普通的三通道 RGB 图像所包含的信息太少,因此作者在多通道注意力选择中通过卷积网络扩大图像的通道表示,并且结合注意力映射产生更合理的结果,另外注意力映射还需要学习产生不确定映射用于引导优化由预训练模型所带来的像素级误差对整个模型的影响。
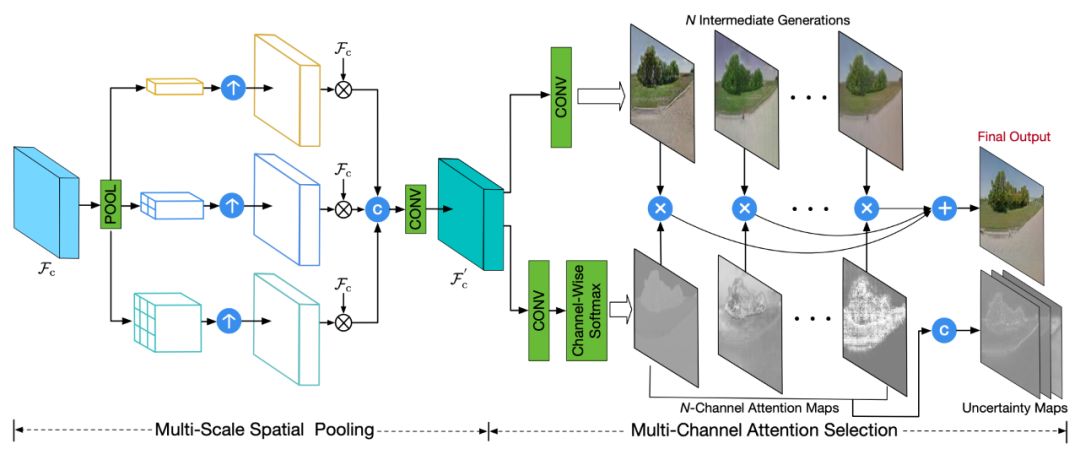
▲ 图3. 多通道注意力选择模型
Selection GAN 的优化目标主要分为三个部分:重建损失、对抗损失以及全变分正则化损失(如图 4 所示)。这里的重建损失包括三个部分:,
(第一阶段)以及
(第二阶段)。

▲ 图 4. 模型优化目标
作者认为不同于原始 GAN,Selection GAN 的鉴别器应该学习分辨来自不同域的成对图像是否彼此相关联,因此这里的对抗损失是用于区分真实图像对以及虚假图像对
,如图 5 所示。

▲ 图5. 对抗损失
实验
在具体实验中对于和
作者采用了 U-Net 架构,由于模型的目的是生成合理的翻译结果因此
采用了深层网络模型,
采用了潜层网络模型。对于鉴别器 D 作者采用了 PatchGAN 架构,用于生成于语义图的预训练模型采用了 RefineNet 架构。
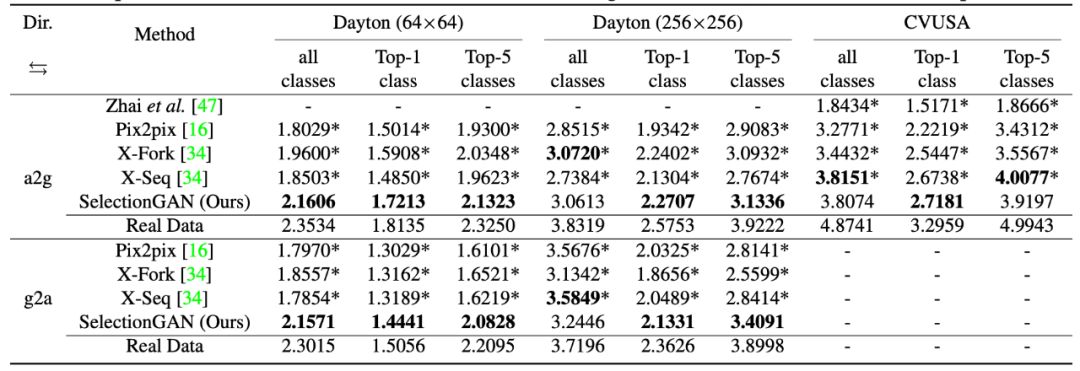
作者主要在 Dayton、CVUSA 以及 Ego2Top 数据集上进行实验,其基线模型选取了 Pix2Pix,X-Fork 以及 X-Seq 进行对比,评价指标采用了 SSIM,PSNR,SD 以及 KL 散度进行衡量,实验结果如下。

另外作者还选取了 Inception Score 进行衡量,结果如下。
总结
Selection GAN 旨在解决具有显著不同结构的图像翻译问题,其将翻译过程分为两个阶段,阶段一旨在捕获场景的语义结构,阶段二通过提出的多通道注意力选择模块关注更多外观细节。另外作者还提出了利用不确定性映射引导优化由预训练模型产生的语义图像素损失,以解决不准确的语义标签问题。在三个公共数据集的实验结果表明,该方法获得了比现有技术更好的结果。
☞ OpenPV平台发布在线的ParallelEye视觉任务挑战赛
☞【学界】OpenPV:中科院研究人员建立开源的平行视觉研究平台
☞【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞【CFP】Virtual Images for Visual Artificial Intelligence
☞【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞【学界】Ian Goodfellow等人提出对抗重编程,让神经网络执行其他任务
☞【学界】六种GAN评估指标的综合评估实验,迈向定量评估GAN的重要一步
☞【资源】T2T:利用StackGAN和ProGAN从文本生成人脸
☞【学界】 CVPR 2018最佳论文作者亲笔解读:研究视觉任务关联性的Taskonomy
☞【业界】英特尔OpenVINO™工具包为创新智能视觉提供更多可能
☞【学界】ECCV 2018: 对抗深度学习: 鱼 (模型准确性) 与熊掌 (模型鲁棒性) 能否兼得

