想在PyTorch里训练BERT,请试试Facebook跨语言模型XLM
晓查 发自 凹非寺
量子位 报道 | 公众号 QbitAI
今年2月,Facebook发表了论文《Cross-lingual Language Model Pretraining》,这篇论文提出了基于BERT优化的跨语言模型XLM,它刚刚出生就在两项机器翻译任务上取得了巨大进步。
在无人监督的机器翻译中,XLM在WMT’16的德语-英语上获得了34.3 BLEU,比之前的技术水平提高了9个以上BLEU。
然而这只是在单个应用领域的成绩,XLM更全面的性能测试结果如何呢?
就在昨天,论文的两位作者提交了GLUE测试得分,在使用相同的数据 (Wiki/TBC)的情况下,没有下一句预测任务,XLM新模型在所有提交的GLUE任务上均优于BERT。

为何能比BERT性能更好,论文作者之一Guillaume说:是因为更大的维度,以及没有下一句预测。
XLM项目
Facebook已经在GitHub上更新了的XLM项目的最新结果。
根据最新的文档描述,XLM的PyTorch英语模型与预训练的BERT TensorFlow模型使用相同的数据(Wikipedia + Toronto Book Corpus)进行训练。
该实现不使用下一句预测任务,网络只有12层但容量更高,包含6.65亿参数。总的来说,XLM模型在所有GLUE任务上都比原始BERT具有更好的性能。
整个XLM项目包括以下代码:
1、预训练语言模型:
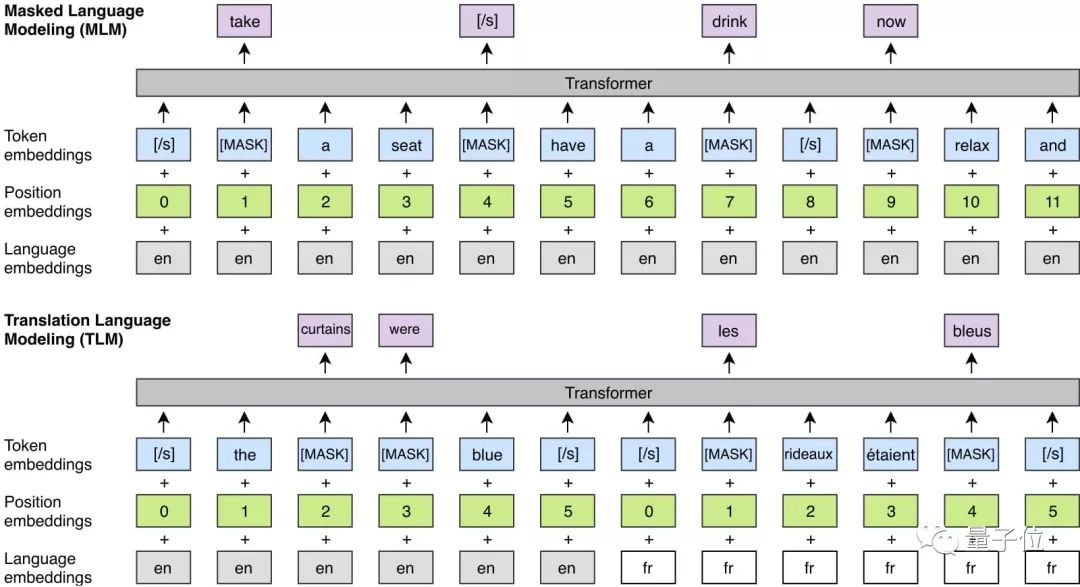
因果语言模型(CLM)- 单语
掩码训练的语言模型(MLM) - 单语
翻译语言模型(TLM) - 跨语言2、监督/无监督的机器翻译训练:
去噪自动编码器
并行数据培训
在线反向翻译3、XNLI微调
4、GLUE微调
Facebook展示了XLM在生成跨语言句子表征上的能力。下面的代码中可以看到根据预训练模型获取句子表征的例子。
# list of (sentences, lang)
sentences = [
('the following secon@@ dary charac@@ ters also appear in the nov@@ el .', 'en'),
('les zones rurales offr@@ ent de petites routes , a deux voies .', 'fr'),
('luego del cri@@ quet , esta el futbol , el sur@@ f , entre otros .', 'es'),
('am 18. august 1997 wurde der astero@@ id ( 76@@ 55 ) adam@@ ries nach ihm benannt .', 'de'),
('اصدرت عدة افلام وث@@ اي@@ قية عن حياة السيدة في@@ روز من بينها :', 'ar'),
('此外 , 松@@ 嫩 平原 上 还有 许多 小 湖泊 , 当地 俗@@ 称 为 “ 泡@@ 子 ” 。', 'zh'),
]
# add </s> sentence delimiters
sentences = [(('</s> %s </s>' % sent.strip()).split(), lang) for sent, lang in sentences]
论文简介
最近的研究证明了生成预训练(Generative pretraining)对英语自然语言理解的效率。而Facebook将这种方法扩展到多种语言,并展示了跨语言预训练的有效性。
他们提出了两种学习跨语言模型(XLM)的方法:一种是无监督学习,只依赖单语数据,另一种是监督学习,利用新的跨语言语言模型目标的平行数据。

这种方法获得了关于跨语言分类、无监督和监督机器翻译的最新结果。在XNLI上,这种方法比之前的技术将准确率提高了4.9%。
在无人监督的机器翻译中,XLM在WMT’16德语 - 英语上获得了34.3 BLEU,比之前的最佳结果提高了9个以上BLEU。
在有监督机器翻译中,XLM在WMT’16罗马尼亚语-英语上获得了38.5 BLEU的结果,比之前的最佳方法提高了超过4 BLEU。
传送门
论文地址:
https://arxiv.org/abs/1901.07291
项目地址:
https://github.com/facebookresearch/XLM
作者系网易新闻·网易号“各有态度”签约作者
— 完 —
AI社群 | 与优秀的人交流

小程序 | 全类别AI学习教程


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「好看」吧 !

