Facebook开源增强版LASER库,包含93种语言工具包
选自code.fb
作者:HOLGER SCHWENK
机器之心编辑部
前不久,Facebook 发布了一项新研究,提出一种可学习 93 种语言的联合多语言句子表征的架构。该架构仅使用一个编码器,且可在不做任何修改的情况下实现跨语言迁移。今日,Facebook 开源增强版 LASER 库,包含上述研究的模型和代码。目前,LASER 库包含 93 种语言工具包。

为了将 NLP 应用尽快部署到更多语言,Facebook 的研究者拓展并改进了其 LASER(Language-Agnostic SEntence Representations)工具箱。今天,他们开源了第一个可探索大量多语言句子表征形式的工具——LASER,将其与 NLP 社区分享。据称,该工具现在能应用于涉及 28 种不同字符系统的 90 多种语言中。LASER 将所有语言共同嵌入到一个共享空间中(而不是为每种语言建立一个单独的模型),从而实现这样的结果。一起开源的还包括涵盖 100 多种语言的多语言测试集。
多语言编码器和 PyTorch 代码链接:https://github.com/facebookresearch/LASER
Facebook 表示:LASER 为实现 NLP 模型从一种语言(如英语)到其它语言(包括训练数据极其有限的语言)的零样本迁移打开了大门。它是首个用单个模型解决多种语言(包括低资源语言,如卡拜尔语、维吾尔语、吴语)的同类型库。有朝一日,这项工作可能会帮助 Facebook 和其它公司推出特定的 NLP 功能,比如将一种语言的电影评论分为正面或负面评论,然后立即用 100 多种其它语言将其展示出来。
LASER 的性能和功能亮点
LASER 在 XNLI 语料库 14 种语言中的 13 种语言上获得了零样本跨语言自然语言推理任务的当前最佳准确率结果。它还在跨语言文档分类(MLDoc 语料库)上取得了良好的结果。利用 LASER 获得的句子嵌入在平行语料库挖掘上表现不错,在 BUCC(2018 Workshop on Building and Using Comparable Corpora)4 个语言对中 3 个语言对的共享任务上达到了当前最佳。除了 LASER 以外,Facebook 还发布了新的基于 Tatoeba 语料库的 100 多种语言的对齐句子测试集。使用该数据集,Facebook 称其句子嵌入可以在多语言相似性搜索上获得良好的结果,即使低资源语言也不例外。
LASER 还拥有以下优势:
它能在 GPU 上每秒处理约 2000 个句子。
句子编码器是在 PyTorch 中实现的,只需要很少的外部依赖。
资源有限的语言可以从多个语言的联合训练中受益。
该模型支持在一个句子中使用多种语言。
随着新语言的加入,系统会学习识别其语系特征,从而使相关任务性能得到提升。
通用的语言无关的句子嵌入
LASER 的句子向量表征对于输入语言和 NLP 任务都是通用的。该工具能将任何语言的句子映射到高维空间中的一个点,而该句子的其它语言的嵌入也会位于附近。这种表征可以看成是语义向量空间的一种通用语言。Facebook 称该空间中的句子距离和句子语义接近度非常相关。
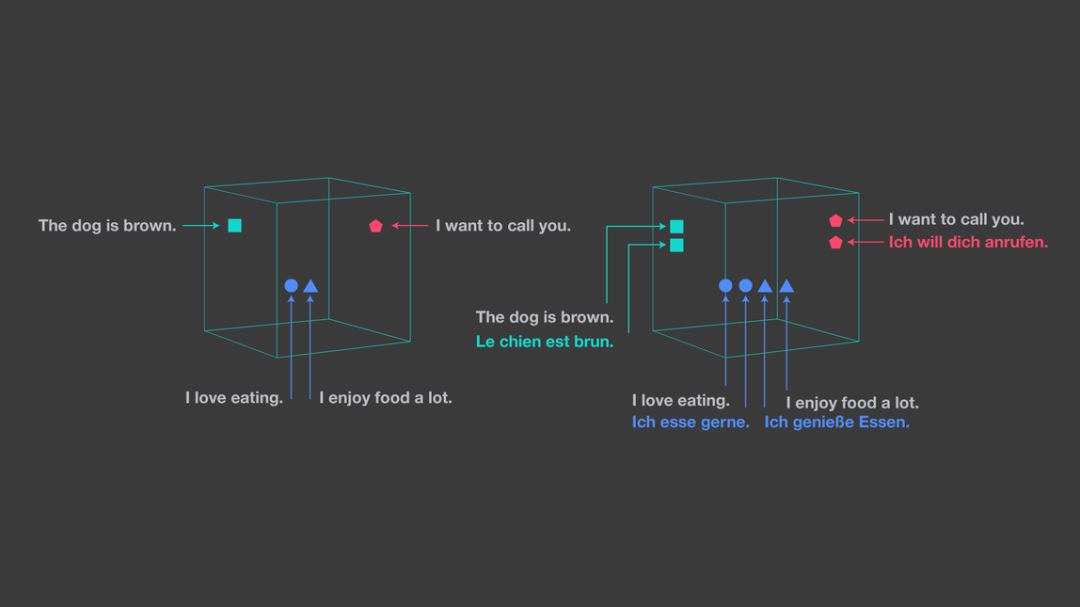
图左显示了单语嵌入空间。图右展示了 LASER 的方法,它将所有语言嵌入到一个共享空间中。
LASER 的方法建立在与神经机器翻译相同的基础技术之上:编码器/解码器方法,也称为序列到序列处理。Facebook 为所有输入语言使用一个共享编码器,并使用共享解码器生成输出语言。编码器是五层双向 LSTM 网络。与神经机器翻译相比,研究者没有使用注意力机制,而是使用 1024 维固定大小的向量来表征输入句子。它是通过对 BiLSTM 的最后状态进行最大池化来获得的。这使得句子表征可以互相比较,并将它们直接输入分类器。
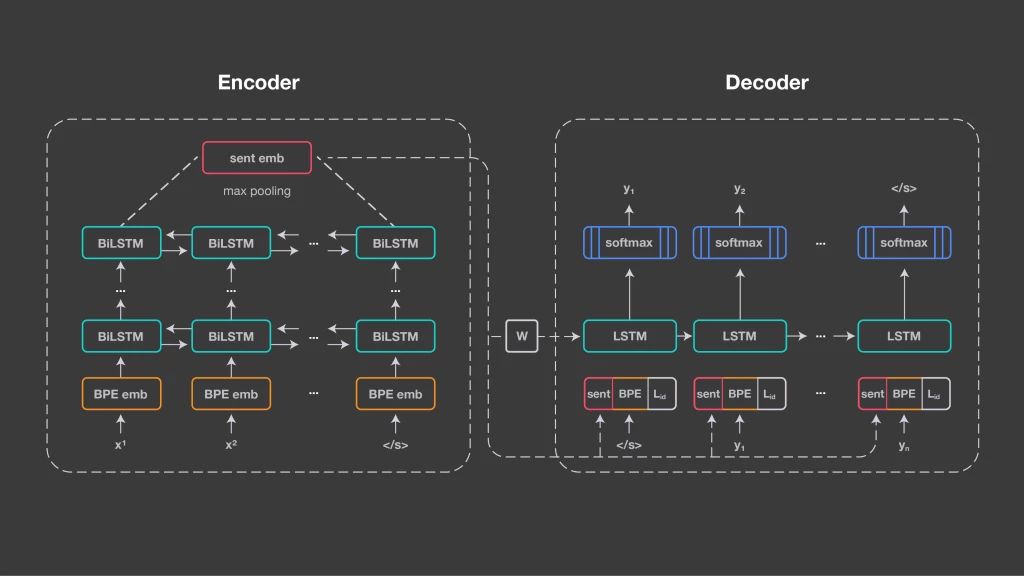
上图说明了 LASER 的架构。
这些句子嵌入通过线性变换初始化解码器 LSTM,并且还在每个时间步和其输入嵌入拼接。编码器和解码器之间没有其它连接,因为 Facebook 希望通过句子嵌入捕获输入序列的所有相关信息。
解码器必须被告知生成哪种语言。它会获得一个语言标识嵌入,在每个时间步和输入以及句子嵌入拼接。Facebook 使用具有 50000 个操作的联合字节对编码(BPE)词汇表,在所有训练语料库的拼接上进行训练。由于编码器没有指示输入语言的显式信号,因此该方法鼓励它学习与语言无关的表征。Facebook 对 2.23 亿个与英语或西班牙语对齐的公共平行数据进行了系统训练。对于每个批量,Facebook 随机选择一种输入语言并训练系统将句子翻译成英语或西班牙语。大多数语言都与目标语言保持一致,但这不是必要的。
开始时,Facebook 只用不到 10 种欧洲语言进行训练,这些语言都用相同的拉丁语书写。将 Europarl 语料库中的语言逐渐增加至 21 种后发现,语言越多,多语言迁移的表现也越好。该系统学习了语系的一般特征。通过这些方法,低资源语言受益于同语系中高资源语言的资源。
通过使用在所有语言拼接上训练的共享 BPE 词汇,这是可能实现的。对每种语言的 BPE 词汇分布之间对称的 Kullback-Leiber 距离进行的分析和聚类表明其与语言定义的语系完全相关。

这幅图展示了 LASER 自动发现的各种语言之间的关系,与语言学家手工定义的语言分类高度一致。
研究者意识到,单个共享 BiLSTM 编码器可以处理多个脚本,他们逐渐将其扩展到所有可以找到免费平行文本的语言。LASER 可以处理的 93 种语言包括主动宾(SVO)顺序的语言(如英语)、主宾动(SOV)顺序语言(如孟加拉语和突厥语)、动主宾(VSO)顺序语言(如塔加拉族语和柏柏尔语),甚至是动宾主(VOS)顺序的语言(如马达加斯加语)。
该编码器可以推广到没有被训练过(即使作为单语言文本训练集)的语言中。研究者发现编码器在地区性语言上有良好表现,包括阿斯图里亚斯语、法罗语、弗里西语、卡舒比语、北摩鹿加语、皮埃蒙特语、施瓦本语、索布语。这些语言都不同程度地和其他主要语言有一些相同点,但是它们有自己的语法系统和特定词汇。

上表展示了 LASER 在 XNLI 语料库上的零样本迁移学习性能。BERT 模型的结果是从其 GitHub README 上提取的。(注意:这些结果是通过 PyTorch 1.0 实现的,因此具体数值会和论文中略有不同,论文中使用的是 PyTorch 0.4)。
零数据、跨语言的自然语言推理
该模型在跨语言自然语言推理(NLI)上表现出色,这表明该模型极强地表示了句子的意义。研究者使用零数据设置,即先用英语训练自然语言推理器,然后在没有微调或者目标语言资源的情况下将其应用于所有的目标语言。在 14 种目标语言中,模型在 8 种语言上的零数据表现是在应用于英语时性能的 5% 上下区间。这 8 种语言包括与英语亲属关系远的俄语、汉语、越南语等。该模型也在资源比较少的斯瓦希里语和乌尔都语上取得了很好的成绩。最终,14 种目标语言,LASER 在 13 种语言的表现超过了所有以前使用零数据迁移的方法。
与以前要求句子必须是英语的方法相比,本文研究者的系统是完全使用目标语言的,并且支持不同语言中的各种前提和假设。
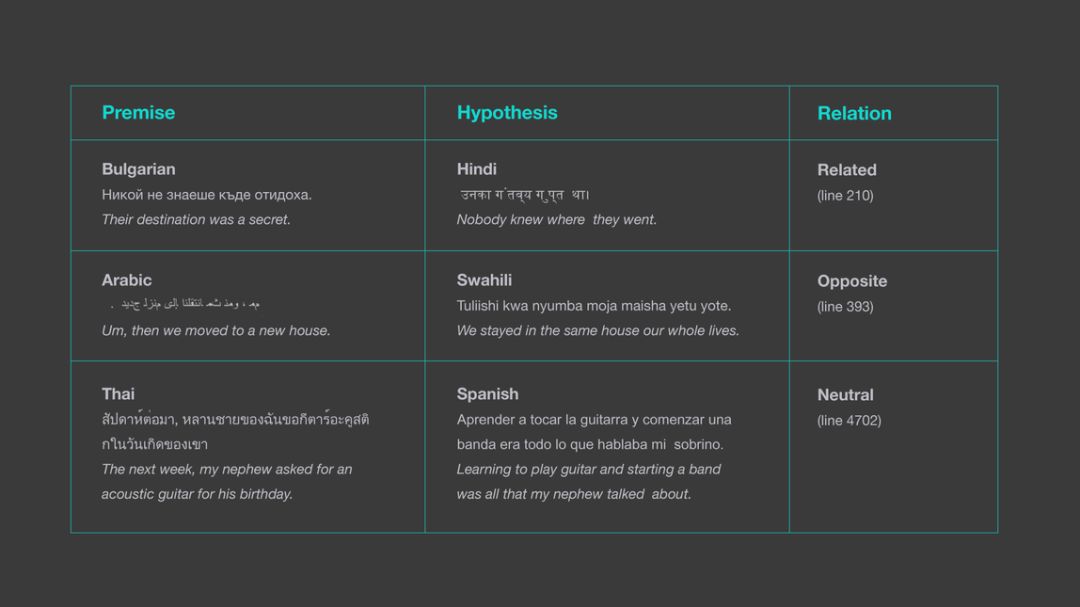
该图表明 LASER 是如何确定 XNLI 数据集中不同语言句子之间关系的。以前的方法只会考虑同一语言中的前提和假设。
该句子编码器也可被用于挖掘大型单语言文本集合中的平行数据。Facebook 研究者只需要计算所有语言对之间的距离,并选择最近的一对。这种方法通过考虑最近语句和其他最近邻之间的间隔而得到进一步改进。该搜索通过 Facebook 的 FAISS 库高效完成。
该方法在 BUCC 任务上显著优于当前最优结果。该获胜系统确实是为此任务设计的,但 Facebook 研究者把德译英的 F1 分数从 85.5 提升到了 96.2,法译英的 F1 分数从 81.5 提升到了 93.9,俄译英从 81.3 改进到 93.3,中译英从 77.5 到 92.3。可以看出,Facebook 的结果在所有语言上都高度均匀。
更多细节描述请参见论文《Massively Multilingual Sentence Embeddings for Zero-Shot Cross-Lingual Transfer and Beyond》(论文链接:https://arxiv.org/abs/1812.10464)。
该方法可用于在使用任意语言对的情况下,挖掘 90 多种语言中的平行数据。这有助于改进众多依赖平行训练数据的的 NLP 应用,包括低资源语言的神经机器翻译。
未来应用
LASER 库也可被用于其他相关任务,例如多语言语义空间可被用于对同样语言或 LASER 支持的 93 种其他语言做句子阐述或者搜索相似含义的句子。Facebook 表示将会继续改进模型,增加更多的语言。

原文地址:https://code.fb.com/ai-research/laser-multilingual-sentence-embeddings/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com